一 前言
时间过得真快,距离本系列博客第一篇的发布已经过去9个月了,本文是该系列的第四篇博客,将对JDownload做一个整体的描述与介绍。恩,先让笔者把记忆拉回到2017年年初,那会笔者在看Unix环境高级编程这本书,其中有些章节是socket相关的,这引起了我很大的兴趣。然后有一天,看着屏幕上正在下载文件的迅雷,突然灵光一闪,要不自己也写个下载工具吧,正所谓学以致用嘛,然后网上简单搜索了一下,发现是可行的,于是乎就开始着手实现之。该系列的第一篇博客实现了一个基本的http站点迷你下载工具,第二篇加入了断点续传功能,第三篇加入了多线程的功能。本篇将从总体上对JDownload做一个描述,以图形的方式来展示一下JDownload的工作流程,因此笔者建议读者先阅读一下该系列的另外三篇博客:
- JWebFileTrans: 一款可以从网络上下载文件的小程序(一) 链接请点击我
- JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(二) 链接请点击我
- JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(三),多线程断点下载 链接请点击我
GitHub代码链接请点击我
PS: 本篇博客是博客园用户“cs小学生”的原创作品,转载请注明原作者和原文链接,谢谢。
二 JDownload执行流程图
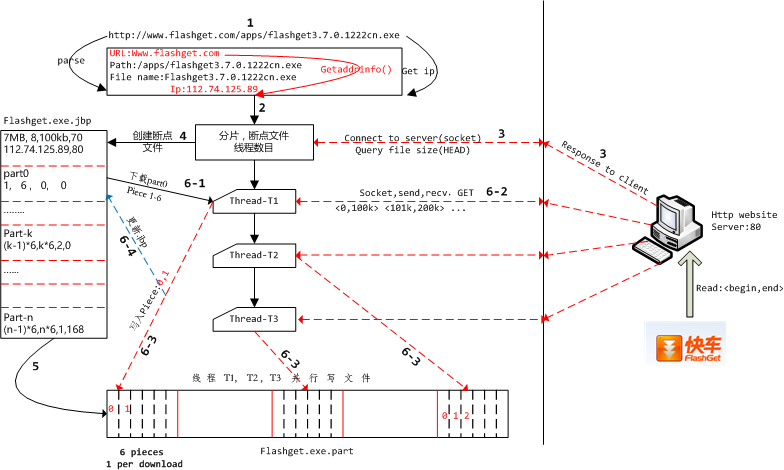
如上图所示,描述了JDownload从快车官网上下载“快车”软件的整个执行流程图,图中的数字标志了执行的先后顺序。诸如6-1,6-2之类的表示这几个步骤的关系比较紧密,6表示都属于同一个大操作,后面的1,2,3,4,表示在这个大操作的内部的执行顺序。在图中每一个线程都会经历6-1,2,3,4的这样一个执行流过程,但是为了防止图变得太过稠密而影响美观,只有线程1完整标志出了6-1,2,3,4这几个标识符,其他几个线程也会经历这几个过程,但是图中省略了这几个标识符。当然对于步骤6,图中的线程是并行执行的。
接下来让我们从标识符1开始,来走一遍整个下载过程:
1. 解析http链接
首先是用户输入下载链接“http://www.flashget.com/apps/flashget3.7.0.1222cn.exe”给JDownload,然后如图最上端的矩形框所示,JDownload会从这个链接里面解析出3个部分,分别是
- URL: www.flashget.com,通过该URL可以得到对应的ip地址
- 服务端资源路径:/apps/flashget3.7.0.1222cn.exe
- 文件名:flashget3.7.0.1222cn.exe
相信学过计算机网络这门课程的童鞋应该记得:ip地址和端口号唯一标志了一台计算机上面的一个服务,所谓服务比如80端口对应的是http服务,端口号21对应的是ftp服务等等。想象一下,我们要下载的东西必定存储在网络中的某台计算机上,但是这台计算机上很可能存在着很多服务,比如http服务、ftp服务、邮箱服务,由于这些服务是用约定好的端口号来标志的,而我们已经知道下载的东西在http站点上,所以我们向端口号80请求下载文件即可。那么端口号80我们已经知道了,服务器的ip地址怎么找呢?其实linux库函数getaddrinfo()就具备通过域名来查找ip地址的功能,具体使用请参考APUE.
前面我们说过,通过GET可以向http站点请求下载文件,我们每一次向服务器请求文件的一部分,然后不断地请求,最后就可以把整个文件下载下来。所以我们需要知道文件的大小是多少,每一次下载多少字节量的数据,这样我们就可以知道总共需要下载多少次。文件的大小可以通过HEAD命令来向服务器查询,每次下载的量我们可以自定义比如500kb等。Get、Head命令都会收到服务器发过来的一个描述文件信息的头部,而对于Get来说,头部数据后面紧跟着就是文件的真正数据,这正是我们要下载的目标。
1 sprintf(send_buffer,"GET %s",path); 2 strcat(send_buffer," HTTP/1.1\r\n"); 3 strcat(send_buffer,"host: "); 4 strcat(send_buffer,host_ip); 5 strcat(send_buffer," : "); 6 strcat(send_buffer,port); 7 strcat(send_buffer,buffer_range); 8 strcat(send_buffer, "\r\nKeep-Alive: 200"); 9 strcat(send_buffer,"\r\nConnection: Keep-Alive\r\n\r\n");
上面的代码便是构造Get命令的代码,其中的path就是我们解析出来的服务端资源路径,host_ip就是通过getaddrinfo(url)得到的ip地址,buffer_range表示要下载的文件的范围,比如第1字节到第1000字节。这些格式化的信息要通过Linux send()函数发送给服务端,然后我们通过recv()函数接收服务端发送过来的响应。
2. 创建断点文件
什么是断点文件呢?以大家最熟悉的迅雷为例,没有下载完的文件,下次可以启动迅雷接着下载,而不用从头开始下载,其实是迅雷记住了上次下载中断时的一些信息,而我们的断点文件就是用来还原上次下载中断时的现场,以便我们可以继续上次结束的地方接着下载,也即断点续传。
顺着流程图中的数字2我们来到一个矩形小方框,从框里的内容我们可以得知我们需要对文件进行分片,所谓的分片也即把整个文件分成N等分,然后其中的每m个等分组成一个task,这样的话就会有N/m个task,后续将会创建一些线程,每一个线程负责下载其中的若干task. 为了完成这件事情,我们首先来到数字3标志的执行流:向服务器发起连接,发送HEAD请求、服务器响应请求向客户端发送信息。根据这些信息,JDownlaod就可以对文件进行分片,然后创建断点文件了。
顺着图中数字4标志的箭头,我们为快车创建了一个断点文件:flashget.exe.jbp. 正如上文所述,断点文件时用来恢复下载现场用的,因此要记录一下关键信息。最开头的部分记录了文件的大小、被分成了多少个task(后续每一个线程会下载其中的1个或多个task)、每一个分片的大小、分片的数目。紧接着后面挨个描述了每一个task(或者part)的信息,以part-n为例,该task包含了第(n-1)*6到第n*6个分片,当前已经下载完成了1个分片,该task包含一个168字节的数据,168不足一个分片的大小,因此单独拿出来描述(图中的数据只是一个示意,并不是真实数据)。当然只有最后一个task才会出现不足一个分片的情况。显然有了这些信息,不管下载的过程何时中断,以及中断多少次,我们都可以恢复现场。
断点文件创建完毕后,我们沿着图中的数字5表示的箭头,在本地磁盘创建同名文件,为后续接收socket发来的数据做准备。
3. 多线程下载
从图中我们可以看出,创建了3个线程用于下载文件,以线程1为例,从数字6-1处可以看到,先从断点文件里读取part-0处的信息,得知需要下载第1到6个分片,而且当前并没有已经下载完毕的分片。于是沿着6-2,线程向服务端挨个请求这6个分片的数据。收到数据后沿着6-3将文件数据写到对应的offset处。这里多个线程是并发写入文件的,由于每一个线程写入的范围并没有交集,所以不需要用锁来保护数据的一致性。从图中可以看出线程1将分片1,2写入了文件中,紧接着沿着数字6-4线程应该更新断点文件,具体是更新当前已经下载了多少个分片的那个字段,这样如果文件没有下载完毕,下次重新启动的时候可以从接着已经下载的分片继续下载,而不用重复下载。
当然,未下载完成的文件,下次继续下载时就不用执行数字1,2,3标志的过程了,而是直接读取断点文件,创建线程,每个线程从断点文件里面读取自己分配到的task,如果该task分配已下载完毕则忽略,否则接着上次下载的地方继续下载。
三 结束语
在前几篇博客里面,我们以文字和代码片段的形式叙述了JDownload的实现过程,而本篇博客以图形的方式展示了JDownload的整体概貌,并且顺着图形走了一条完整的下载路径。主要涉及到下载链接的解析、断点文件的设计、多线程的运用。在未来可能会考虑添加FTP的支持。
时间过得真快啊,距离写关于JDownload的第一篇博客已经过去了9个月。
联系方式:https://github.com/junhuster/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号