


【DPDK】谈谈DPDK如何实现bypass内核的原理 其一 PCI设备与UIO驱动
【前言】
随着网络的高速发展,对网络的性能要求也越来越高,DPDK框架是目前的一种加速网络IO的解决方案之一,也是最为流行的一套方案。DPDK通过bypass内核协议栈与内核驱动,将驱动的工作从内核态移至用户态,并利用polling mode的线程工作模式加速网络I/O使得网络IO性能出现大幅度的增长。
在使用DPDK的时候,我们常常会说提到用DPDK来接管网卡以达到bypass内核驱动以及内核协议栈的操作,本篇文章将主要分析DPDK是如何实现的bypass内核驱动来实现所谓的“接管网卡”的功能。
注意:
- 本篇文章会涉及一些pci设备的内容,但是不会重点讲解pci设备,pci设备中的某些规则就是这么设计的,并没有具体原因。
- 本篇部分原理的讲解会以Q&A的方式拖出,因为DPDK bypass内核的这部分涉及的知识维度比较多,没有办法按照线性的思路讲解。
- 本人能力以及水平有限,没办法保证没有疏漏,如有疏漏还请各路神仙进行指正,本篇内容都是本人个人理解,也就是原创内容。
- 由于内容过多,本篇文章会着重基础的将PCI以及igb_uio相关的知识与分析,以便于不光是从DPDK本身,而是全面的了解DPDK如果做到的bypass内核驱动,另外关于DPDK的代码部分实现将会放在后续文章中放出,另外还有DPDK的中断模式以及vfio也会在后续的文章中依次发出(先开个坑,立个flag)
【1.谈一谈使用】
通常启动一个基于dpdk开发的应用,都需要几步准备来完成。
- 首先需要插入igb_uio/vfio-pci这两个驱动中的一个,接下来会以igb_uio为例讲解(因为简单...vfio还是有点复杂的...vfio的解析会放在以后的文章中放出)。
- 其次需要运行dpdk-devbinds.py这个dpdk官方给出的py脚本,以此来完成内核驱动到igb_uio/vfio的接管。接管之后,再次运行dpdk-devbinds可以很明显的看到驱动从ixgbe转为了igb_uio。请见图1.
- 运行dpdk应用,以-p参数指定要接管的网口,例如-c 0x03,那么接管的网口便是port 0和port 1.
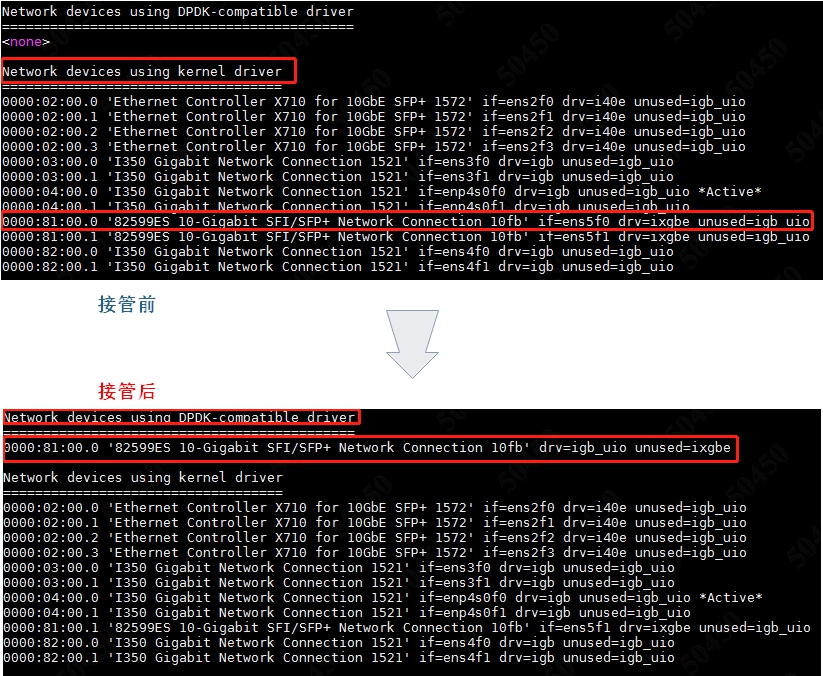
图1.接管前后pci设备驱动发生的变化
那么经过上述三个操作,至少脑子里会产生这么几个问题:
Q:igb_uio/vfio-pci的作用是什么?为什么要用这两个驱动?这里的“驱动”和dpdk内部对网卡的“驱动”(dpdk/driver/)有什么区别呢?
Q:dpdk-devbinds是如何做到的将内核驱动解绑后绑定新的驱动呢?
Q:dpdk应用内部是如何操作pci设备的呢?是怎么让pci设备可以将数据包直接扔到用户态的呢?
这三个问题,实际上也是我当初在研究这一部分是遇到的三个问题。首先我们先来看第一个问题。
【问题一:igb_uio/vfio-pci是什么?】
我们会以igb_uio驱动为例进行讲解。这里其实很难一步讲清楚igb_uio的作用以及实现原理,所以接下来的讲解还是会以Q&A和“挖坑式”的方式进行逐步将原理展现给各位看官面前。先说说操作一个外设,最先想到的是什么呢?如果有过单片机等嵌入式外设开发的朋友肯定会冒出这样的一个想法
我得配置这个外设,为此我需要找到它的寄存器,但是找到它的寄存器前提是我得先拿到基地址才行,接下来通过基地址+寄存器偏移就能找到寄存器所在的地址,然后就可以配置了
所以第一个任务便是我们要拿到”基地址“,首先有必要先科普一下pci设备的基地址。因此我必须得掏出一张图,即描述pci配置空间的一张图,如果图2所示。

图2.pci设备的配置空间
图2为pci配置空间的分布图,在图中,0x0010 ~ 0x0028这24个字节中,分布着6个PCI BAR(base address register),也就是最最重要的“基地址”,那这里有人可能会想问“这个图和我们有关系么?这个图中的空间在哪?我们该怎么解析?”,答案是“无关”,这些图中的信息事实上在系统启动时,就已经被解析完成了,以文件系统的方式供用户态程序取读取。但是这里其实有这样的一个问题:
PCI设备为啥有6个BAR,而不是3个、8个?这些BAR都有啥区别?实际访问寄存器的时候以哪一个BAR为基准呢?
其实解释这个问题,是一件简单而又不简单的事情。简单是因为pci设备规定就是有6个bar空间,而不简单是因为不知道为什么规定6个bar空间。那么这些BAR又有什么区别呢?这里要引用一下stackoverflow上面一位老哥说的话,见图3.(这里其实我之前也一直不太明白,因为国内的很多论坛帖子都是千篇一律...很难筛选出自己想要的信息...)
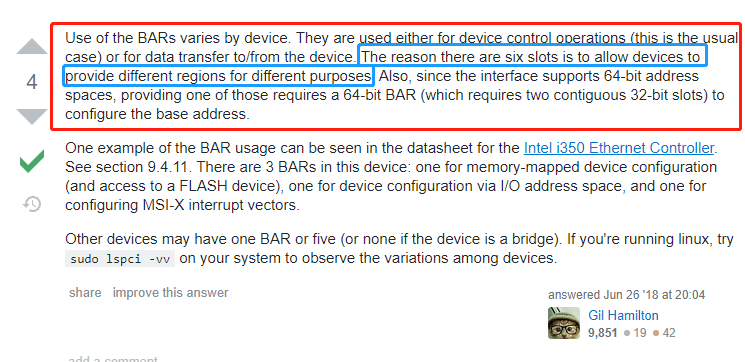
图3.不同BAR空间的区别之StackOverflow
其实关键就是蓝色的那句话,即”6个槽(BAR)允许设备以不同的目的提供不同的区域“,根据这个线索,我们来看一下intel 82599这款经典的10G网卡的datasheet中9.3.6中的解释。见图4.

图4.intel 82599 datasheet中关于不同pci bar的划分
可以看到这款经典网卡(其实intel的卡基本都是这么分的)主要将6个pci bar分成了三块区域:
- Memory BAR : 内存BAR,Memory BAR标志着这块BAR空间位于内存空间,通过mmap映射后可以直接访问。
- I/O BAR : IO BAR空间,I/O BAR标志着这块BAR空间位于IO空间,对其的访问不能像Memory BAR那样映射之后就可以随心所欲访问,IO BAR必须通过专门的操作来进行读写。
- MSI-X BAR : 这个BAR空间主要是用来配置MSI -X 中断向量。
那么这里可能有人会问,一共不是6个BAR空间么?这里只分了3个区域,那么每个区域分多少呢?这里请注意的是关于图3中6个PCI BAR,每个PCI BAR都是32位的,但是像82599这种工作在64位的网卡,其实就只有三个BAR。BAR0 BAR1为Memory BAR,BAR2 BAR3为I/O BAR,BAR4 BAR5为MSI-X BAR。这里我们可以对照一款低端网卡I350的datasheet,见图5.

图6.I350网卡datasheet中关于BAR分布的描述
从图6可以看到,对于I350这种低端的千兆网卡,可以将其配置位工作在32位还是64位模式下,但是对于82599这种万兆10g的卡,就没那么多选择余地了,只能工作在64位模式下,因此回到图3中,我们可以根据intel 82599的datasheet来得知intel的64bit网卡的bar分布是长什么样子的,如图7.

图7.intel 82599网卡的BAR分布
所以PCI配置空间的规范结合intel的I350和82599这两款网卡的datasheet进行分析,我们可以得出这样的一个结论:”PCI有6个BAR是规范,6个BAR的区别和作用取决于具体的PCI外设,需要查看datasheet才能给出答案“。
说完6个BAR的作用以及分布,接下来还有个问题,实际访问PCI BAR的时候以哪一个BAR为基准呢?这里主要有疑问的地方会出现在Memory BAR还是I/O BAR。因为需要搞清楚这两者的区别,才能真正判断在哪个BAR写配置。关于IO BAR和Memory BAR的区别首先需要科普一下,在x86体系架构下,内存的编址情况。接下来进入科普时间。
其实这里是比较晦涩难懂的,首先我们得知道,为什么会出现I/O空间和外设空间?在讨论区别之前我们可以看一张图,看看I/O空间和Memory空间长什么样子,这里可以看宝华叔经典的《Linux设备驱动开发详解》的第11章部分,这里我就简单的说一下,x86下的I/O空间和Memory空间到底长啥样子。见图8.

图8.I/O空间与内存空间,来自宝华叔的《Linux设备驱动开发详解》中第11章
另外需要注意的时,非x86体系架构下,例如ARM、PowerPC这些架构下,所有的外设和主存(RAM)都会进行统一的编址,所以kernel可以像访问正常的内存空间一样访问内设。而x86体系架构下,外设是进行独立编址的,如图8所示,因此也就出现了IO空间和Memory空间的区别。(其实可以将RAM看成一种”专门用来内存映射的IO设备“)。另外我们从图8还可一看到另外一个信息,那就是访问外设其实可以有两种方式,一种是通过I/O空间用专有的指令进行访问,另外一种便是访问内存空间,而访问内存空间就相对而言容易的多,也随便的多,那么为什么外设会同时拥有两个空间呢?这里是由于外设通常会自带“存储器”。另外宝华叔还特地提到了如下一句话:
访问外设可以通过访问内存空间,而访问外设其实可以不必通过IO空间,也间接说明了IO空间实际上不是访问设备所必要的,而内存空间才是必要的
这里常常还有一个容易懵逼的概念,叫做“I/O端口”和”I/O内存“(趁着说DPDK,这里就把这些基础的概念依次科普一下),首先访问I/O空间是必须通过一些专有指令进行访问的,通过独特的in、out指令进行访问,端口号表示了外设的寄存器地址。Intel语法中的in、out指令格式如下:
IN 累加器, {端口号 | DX}
OUT {端口号 | DX}, 累加器
这两个指令实际上不需要知道是什么意思,只需要知道访问I/O空间需要独特的in、out指令来访问寄存器地址,这些寄存器地址就像“开放了端口”一样供cpu访问,因此称为“I/O端口”。而I/O内存便是正常访问内存空间的I/O设备所在的寄存器地址。简而言之,通过I/O指令通过I/O端口来访问I/O空间的外设寄存器;通过内存映射后通过I/O内存访问内存空间的外设寄存器,在这里所谓的I/O端口或者I/O内存可以理解为一种“通道”,主语是“CPU”,谓语是“访问”,宾语是”外设寄存器“,而I/O端口则是“状语”。并且实际上,在现在的计算机体系架构下,已经不再推荐通过I/O端口的方式取访问寄存器了,而是推荐采用IO内存的方式。
经历了上面的关于PCI BAR、IO空间、内存空间、IO端口、IO内存的科普,接下来我们回归DPDK的驱动托管流程。上面的科普说到了一个关键就是“访问寄存器实际上可以I/O内存的方式取访问内存空间的外设寄存器,而不必通过I/O端口的方式访问位于I/O端口的外设寄存器”。补充了这些关键的基本知识后,我们再梳理一下可以得到哪些关键性的结论:
- PCI有6个BAR,6个BAR的不同划分跟pci设备设计有关,intel的网卡有Memory Bar、IO Bar还有MSI-X Bar。
- 这些Bar,想操作寄存器的话,不必通过I/O Bar,通过Memory Bar即可,也就是intel网卡中的Bar0空间。
知道要访问哪一块Bar后,接下来就要想办法拿到BAR空间供用户态访问。
【4.如何拿到BAR?】
如何拿到BAR,关于这个问题,可以通过阅读DPDK的源代码来解决,接下来不会系统性的分析DPDK是如何在启动阶段扫描PCI设备,这里会留到以后新开一篇文章阐述,接下来的分析将会从代码中的某一点出发进行分析。
进入DPDK源代码中的drivers/bus/pci/linux/pci.c中的函数,上代码:
#define PCI_MAX_RESOURCE 6 /* * pci扫描文件系统下的resource文件 * @param filename 通常为/sys/bus/pci/devices/[pci_addr]/resource文件 * @param dev[out] dpdk中对一个pci设备的抽象 */ static int pci_parse_sysfs_resource(const char *filename, struct rte_pci_device *dev) { FILE *f; char buf[BUFSIZ]; int i; uint64_t phys_addr, end_addr, flags; f = fopen(filename, "r"); //先打开resource文件,resource文件是一个只读文件,任何的写操作都会被忽略掉 if (f == NULL) { RTE_LOG(ERR, EAL, "Cannot open sysfs resource\n"); return -1; } //扫描6次,为什么是6次,在之前已经提到,PCI最多有6个BAR for (i = 0; i<PCI_MAX_RESOURCE; i++) { if (fgets(buf, sizeof(buf), f) == NULL) { RTE_LOG(ERR, EAL, "%s(): cannot read resource\n", __func__); goto error; } //扫描resource文件拿到BAR if (pci_parse_one_sysfs_resource(buf, sizeof(buf), &phys_addr, &end_addr, &flags) < 0) goto error; //如果是Memory BAR,则进行记录 if (flags & IORESOURCE_MEM) { dev->mem_resource[i].phys_addr = phys_addr; dev->mem_resource[i].len = end_addr - phys_addr + 1; /* not mapped for now */ dev->mem_resource[i].addr = NULL; } } fclose(f); return 0; error: fclose(f); return -1; } /* * 扫描pci resource文件中的某一行 * @param line 某一行 * @param len 长度,为第一个参数字符串的长度 * @param phys_addr[out] PCI BAR的起始地址,这个地址要mmap才能用 * @param end_addr[out] PCI BAR的结束地址 * @param flags[out] PCI BAR的标志 */ int pci_parse_one_sysfs_resource(char *line, size_t len, uint64_t *phys_addr, uint64_t *end_addr, uint64_t *flags) { union pci_resource_info { struct { char *phys_addr; char *end_addr; char *flags; }; char *ptrs[PCI_RESOURCE_FMT_NVAL]; } res_info; //字符串处理 if (rte_strsplit(line, len, res_info.ptrs, 3, ' ') != 3) { RTE_LOG(ERR, EAL, "%s(): bad resource format\n", __func__); return -1; } errno = 0; //字符串处理,拿到PCI BAR起始地址、PCI BAR结束地址、PCI BAR标志 *phys_addr = strtoull(res_info.phys_addr, NULL, 16); *end_addr = strtoull(res_info.end_addr, NULL, 16); *flags = strtoull(res_info.flags, NULL, 16); if (errno != 0) { RTE_LOG(ERR, EAL, "%s(): bad resource format\n", __func__); return -1; } return 0; }
代码1.
可以看到这段代码的逻辑非常简单,就是扫描某个pci设备的resource文件获得PCI BAR。也就是/sys/bus/pci/[pci_addr]/resource这个文件,接下来让我们看一下这个文件长什么样子,见图9.
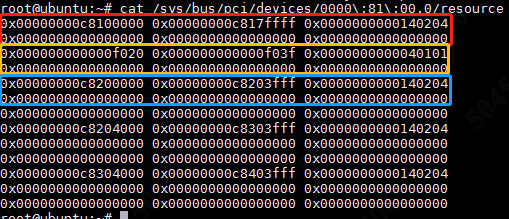
图9.pci目录下的resource文件
可以看到resource文件内部的特点,前6行为PCI设备的6个BAR,每行共3列,其中第1列为PCI BAR的起始地址,第2列为PCI BAR的终止地址,第3列为PCI BAR的标识。图中的例子是ixgbe驱动的intel 82599网卡,之前在第3节也说过,对于82599这张卡工作在64bit模式,前两个BAR为Memory BAR,中间两个BAR为IO BAR,最后两个BAR为MSI-X BAR,因此实际上只有第一行是对我们有用的。通过读取resource文件便完成了BAR的获取。另外PCI目录下还有很多其他关于PCI设备的信息,见图10.

图10.PCI设备目录内容
这张图中的目录结构和图2是不是有些眼熟呢?没错这些文件起始就是系统在启动时根据PCI设备信息自动进行处理并建立的。
- config: PCI配置空间,二进制,可读写;
- device: PCI设备ID,只读。很重要;
- driver: 为PCI设备采用的驱动目录的软连接,真正的目录位于/sys/bus/pci/drivers/目录下,可以看图10中显示这个PCI设备采用的是内核ixgbe驱动;
- enable: 设备是否正常使能,可读写;
- irq: 被分到的中断号,只读;
- local_cpulist: 这个网卡的内存空间位于和同处于一个NUMA节点上的cpu有哪些,列表方式呈现,只读。举个例子,比如网卡的内存空间位于numa node 0,cpu 1-6同样位于numa node0,那么读取这个文件的内容便是:1-6。重要,因为跨numa节点访问内存会带来极大的性能开销。
- local_cpu: 与local_cpulist的作用相同,不过是以掩码的方式给出,例如1-6号cpu和pci设备处于同一个numa节点,那么掩码便是0x7E(0111 1110)。重要,重要程度等价于local_cpulist。
- numa_node: 只读,告诉这个PCI设备属于哪一个numa节点。重要,会影响性能。
- resource: BAR空间记录文件,只读,任何写操作将会被忽略,通常有三列组成,第一列为PCI BAR起始地址,第二列为PCI BAR终止地址,第三列为这个PCI BAR的标识,见图9.
- resource0..N: 某一个PCI BAR空间,二进制,只读,可以映射,如果用户态程序向操作PCI设备必须通过mmap这个resource0..N,也就意味着这个文件是可以mmap的。重要。
- sriov_numfs: 只读,虚拟化常用的技术,sriov透传技术,可以理解在这个网卡上可以虚拟出多个虚拟网卡,这些虚拟网卡可以直接透传到qemu中的客户机,并且网卡内部会有一个小的交换机实现VM客户机数据包的收发,可以极大的减少时延,这个numvfs便是告诉这个pci设备目前虚拟出多少个虚拟网卡(vf)。重要,主要应用在虚拟化场合。
- sriov_totalvfs: 只读,作用与sriov_numfs相同,不过是总数,揭示这个PCI设备一共可以申请多少个vf。
- subsystem_device: PCI子系统设备ID,只读。
- subsystem_vendor: PCI子系统生产商ID,只读。
- vendor:PCI生产商ID,比如intel便是0x8086.重要。
上面便是关于PCI设备目录下的一些文件的解释。
但是DPDK真的是通过读取resource文件来拿到BAR的么?答案其实是否定的...DPDK获取PCI BAR并不是这么获取的。接下来上代码,代码位于drivers/bus/pci/linux/pci_uio.c文件中:
/* * 映射resource资源获取PCI BAR * @param DPDK中关于某一个PCI设备的抽象实例 * @param res_id下标,说白了就是获取第几个BAR * @param uio_res用来存放PCI BAR资源的结构 * @param map_idx uio_res数组的计数器 */ int pci_uio_map_resource_by_index(struct rte_pci_device *dev, int res_idx, struct mapped_pci_resource *uio_res, int map_idx) { ..... //省略 //打开/dev/bus/pci/devices/[pci_addr]/resource0..N文件 if (!wc_activate || fd < 0) { snprintf(devname, sizeof(devname), "%s/" PCI_PRI_FMT "/resource%d", rte_pci_get_sysfs_path(), loc->domain, loc->bus, loc->devid, loc->function, res_idx); /* then try to map resource file */ fd = open(devname, O_RDWR); if (fd < 0) { RTE_LOG(ERR, EAL, "Cannot open %s: %s\n", devname, strerror(errno)); goto error; } } /* try mapping somewhere close to the end of hugepages */ if (pci_map_addr == NULL) pci_map_addr = pci_find_max_end_va(); //进行mmap映射,拿到PCI BAR在进程虚拟空间下的地址 mapaddr = pci_map_resource(pci_map_addr, fd, 0, (size_t)dev->mem_resource[res_idx].len, 0); close(fd); if (mapaddr == MAP_FAILED) goto error; pci_map_addr = RTE_PTR_ADD(mapaddr, (size_t)dev->mem_resource[res_idx].len); //将拿到的PCI BAR映射至进程虚拟空间内的地址存起来 maps[map_idx].phaddr = dev->mem_resource[res_idx].phys_addr; maps[map_idx].size = dev->mem_resource[res_idx].len; maps[map_idx].addr = mapaddr; maps[map_idx].offset = 0; strcpy(maps[map_idx].path, devname); dev->mem_resource[res_idx].addr = mapaddr; return 0; error: rte_free(maps[map_idx].path); return -1; } /* * 对pci/resource0..N进行mmap,将PCI BAR空间通过mmap的方式映射到进程内部的虚拟空间,供用户态应用来操作设备 */ void * pci_map_resource(void *requested_addr, int fd, off_t offset, size_t size, int additional_flags) { void *mapaddr; //核心便是这句mmap,其中要注意的是,offset必须为0 mapaddr = mmap(requested_addr, size, PROT_READ | PROT_WRITE, MAP_SHARED | additional_flags, fd, offset); if (mapaddr == MAP_FAILED) { RTE_LOG(ERR, EAL, "%s(): cannot mmap(%d, %p, 0x%zx, 0x%llx): %s (%p)\n", __func__, fd, requested_addr, size, (unsigned long long)offset, strerror(errno), mapaddr); } else RTE_LOG(DEBUG, EAL, " PCI memory mapped at %p\n", mapaddr); return mapaddr; }
代码2
关于内存映射resource0..N的方法来让用户空间得到PCI BAR空间的操作其实在Linux kernel doc中早有说明:https://www.kernel.org/doc/Documentation/filesystems/sysfs-pci.txt,具体可以看图11.

图11.Linux Kernel Doc中关于PCI设备resource0..N的说明
可以看到,DPDK是怎么拿到PCI BAR的呢?是igb_uio将pci bar暴露给用户态的么?其实完全不是,而是直接mmap resource0..N就做到了,至于resource0..N则是内核自带的一个供用户态程序通过mmap的方式访问PCI BAR。网上很多的文章提到igb_uio的作用,基本都是以下两点:
- igb_uio负责将PCI BAR提供给用户态应用,也就是DPDK;
- igb_uio负责处理中断,形成用户态程序和内核中断的一个桥梁。
这两点中,第二点是正确的,但是第一点则是非常不准确的,第一点很容易误导人,让人产生“DPDK之所以能bypass内核空间获得PCI BAR靠的就是igb_uio”,事实不然,DPDK访问PCI BAR完全绕过了igb_uio,igb_uio的确提供了方法可以让用户态空间应用来访问PCI BAR,不过DPDK没有用。关于这个地方,intel 包处理专家、《DPDK深入浅出》一书的作者梁存铭梁大师给出的解释是:
UIO提供了(PCI BAR)访问方式,但是DPDK直接mmap了resource,Kernel对resource实现的mmap跟在igb_uio中实现一个mmap是一样的实现,没有区别,用kernel自己的方式不是更好么?
所以我们可以确定的是:
- igb_uio负责创建uio设备并加载igb_uio驱动,负责将内核驱动接管的网卡抢过来,以此来先屏蔽掉内核驱动以及内核协议栈;
- igb_uio负责一个桥梁的作用,衔接中断信号以及用户态应用,因为中断只能在内核态处理,所以igb_uio相当于提供了一个接口,衔接用户态与内核态的驱动,关于驱动,后续会开文章专门讲解DPDK的中断;
事实上,igb_uio做的就是上面两点,接下来会从代码以及函数的角度分析igb_uio.ko的实现以及uio如何将PCI BAR暴露给用户态(虽然DPDK没有使用这种方式,但是如何将PCI BAR暴露给用户态,是UIO驱动的一大特色)
【5.igb_uio以及uio的部分代码分析】
想读懂一个内核模块的作用,首先得确定其工作流程。
igb_uio.ko初始化流程如图12所示:
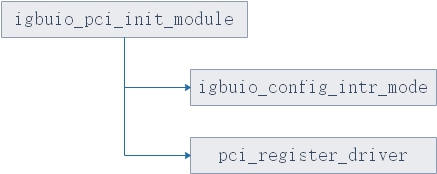
图12.igb_uio.ko的初始化流程
igb_uio.ko初始化主要是做了两件事:
- 第一件事是配置中断模式;
- 第二种模式便是注册驱动,见图13.;
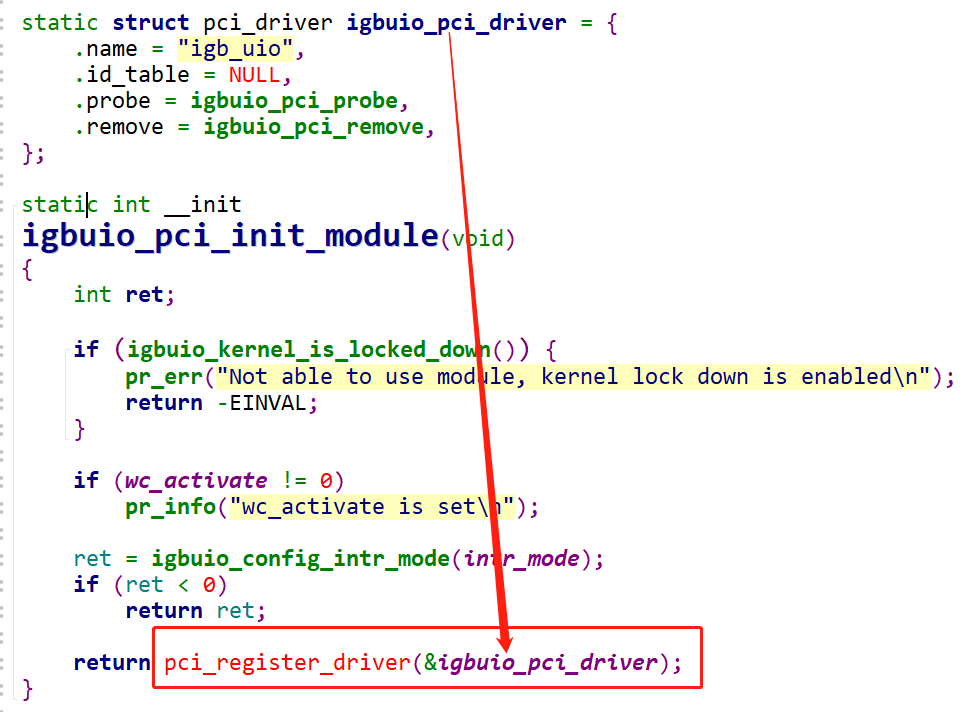
图13.igbuio_pci_init_module函数注册igb_uio驱动
注册驱动后,剩余的进入内核处理内核模块的流程,也就是内核遍历注册的driver,调用driver的probe方法,在igb_uio.c中,也就是igbuio_pci_probe函数,见图14.。
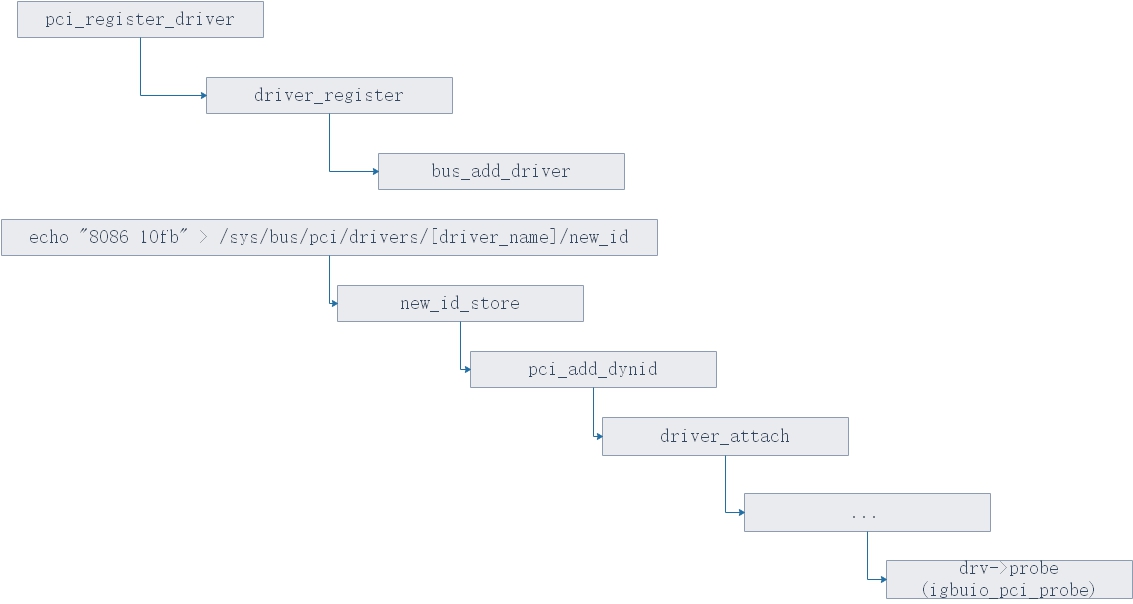
图14.内核处理注册的驱动以及调用probe的流程
接下来便进入igbuio_pci_probe函数,处理主要的注册uio驱动的逻辑,函数调用图如图14所示。
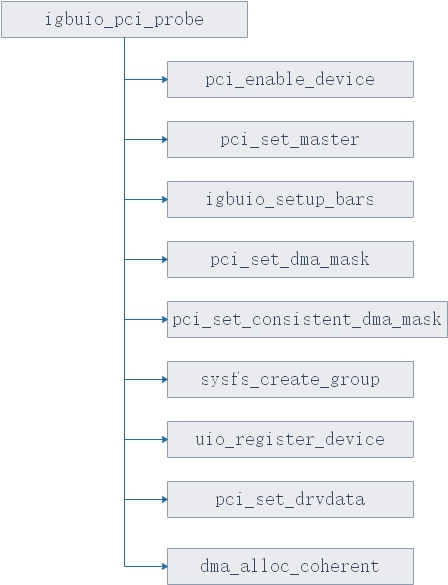
图15.igbuio_pci_probe函数的内部调用流程
- pci_enable_device : 使能PCI设备
- igbuio_pci_bars : 对PCI BAR进行ioremap的映射,拿到所有的PCI BAR。
- uio_register_device : 注册uio设备
- pci_set_drvdata : 设置私有变量
其中在igbuio_pci_bars函数中,会遍历6个PCI BAR,获得其PCI BAR的起始地址,并对这些起始地址进行ioremap,见代码3。这里需要注意的是,内核空间若想通过IO内存的方式访问外设在内存空间的寄存器,必须利用ioremap对PCI BAR的起始地址进行映射后才能访问。
static int igbuio_setup_bars(struct pci_dev *dev, struct uio_info *info) { int i, iom, iop, ret; unsigned long flags; static const char *bar_names[PCI_STD_RESOURCE_END + 1] = { "BAR0", "BAR1", "BAR2", "BAR3", "BAR4", "BAR5", }; iom = 0; iop = 0; //遍历PCI设备的6个BAR for (i = 0; i < ARRAY_SIZE(bar_names); i++) { //PCI BAR空间不等于0且起始地址不等于0,认为为有效BAR if (pci_resource_len(dev, i) != 0 && pci_resource_start(dev, i) != 0) { //拿到BAR的标识,如果为0x00000200则为内存空间 flags = pci_resource_flags(dev, i); if (flags & IORESOURCE_MEM) { //对内存空间的PCI BAR进行映射 ret = igbuio_pci_setup_iomem(dev, info, iom, i, bar_names[i]); if (ret != 0) return ret; iom++; //IO空间不再讨论范围内 } else if (flags & IORESOURCE_IO) { ret = igbuio_pci_setup_ioport(dev, info, iop, i, bar_names[i]); if (ret != 0) return ret; iop++; } } } return (iom != 0 || iop != 0) ? ret : -ENOENT; } //对内存BAR进行映射,以及填充数据结构 static int igbuio_pci_setup_iomem(struct pci_dev *dev, struct uio_info *info, int n, int pci_bar, const char *name) { unsigned long addr, len; void *internal_addr; if (n >= ARRAY_SIZE(info->mem)) return -EINVAL; //拿到PCI BAR的起始地址 addr = pci_resource_start(dev, pci_bar); //拿到PCI BAR的长度 len = pci_resource_len(dev, pci_bar); if (addr == 0 || len == 0) return -1; //wc_activate为igb_uio.ko的参数,默认为0,会进入if条件 if (wc_activate == 0) { //对PCI BAR进行ioremap,映射到内核空间,得到可以在内核空间映射后的PCI BAR地址,虽然没什么用,因为igb_uio完全不需要操作PCI设备,因此获得此地址意义不大 internal_addr = ioremap(addr, len); if (internal_addr == NULL) return -1; } else { internal_addr = NULL; } //填充数据结构 info->mem[n].name = name; //PCI BAR名,例如BAR0、BAR1 info->mem[n].addr = addr; //PCI BAR起始地址,物理地址 info->mem[n].internal_addr = internal_addr; //经过ioremap映射后的PCI BAR,可以供内核空间访问 info->mem[n].size = len; //PCI BAR长度 info->mem[n].memtype = UIO_MEM_PHYS; //PCI BAR类型,为内存BAR return 0; }
代码3
可以看到igbuio_set_bars做的工作也非常简单,就是填充数据结构加上对PCI BAR的IO内存(物理地址)进行ioremap,但是在这里ioremap其实没什么用,进行ioremap映射后会得到一个可以供内核空间访问的PCI BAR地址(虚拟地址),不过从设计角度上讲,igb_uio不需要对PCI设备得到BAR空间,并对PCI设备进行配置,因此意义不大。接下来便是调用uio_register_devcie注册uio设备。

图16.uio_register_device调用流程
uio_register_device的流程主要是做了4件事:
- dev_set_name : 给设备设置名称,uio0...N,为/dev/uio0..N
- device_register : 注册设备
- uio_dev_add_attribute : 主要是创建一些设备属性,这里说属性也有点不太恰当,从表现形式来看是在/sys/class/uio/uio0/目录中创建maps目录,里面包含的主要也是和resource文件一致,就是pci设备经过uio驱动接受以后再把resource资源通过文件系统暴露给用户态而已,可以看图17.
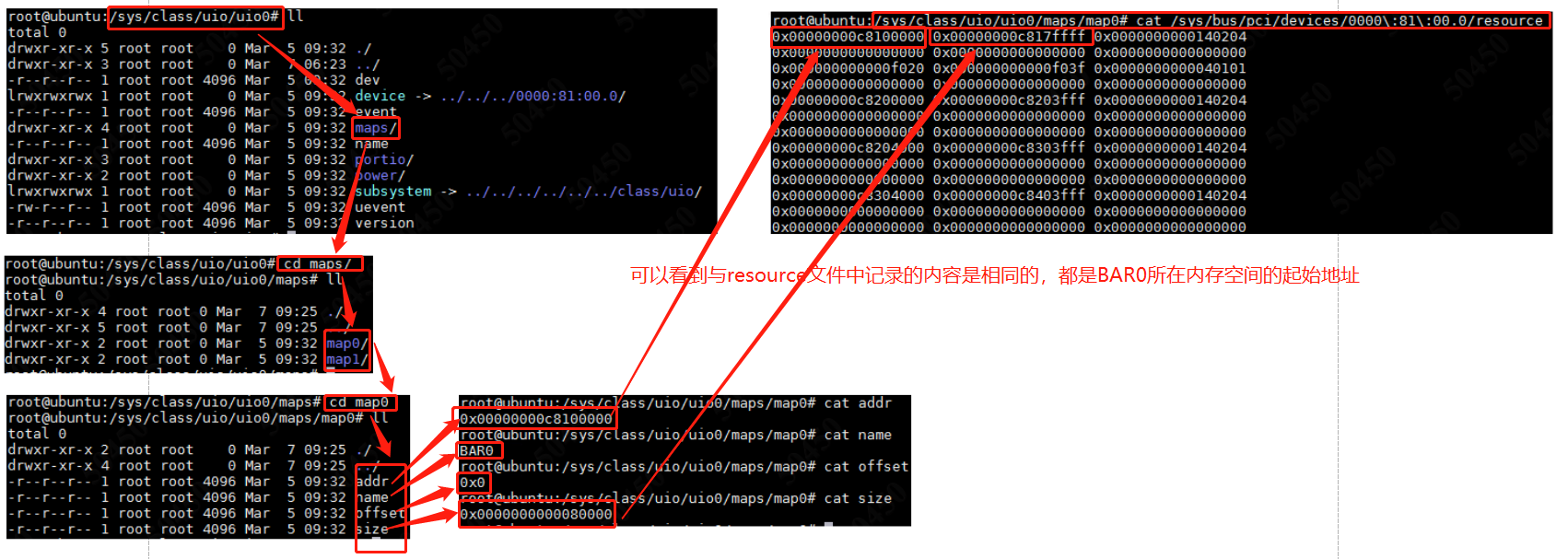
图17.uio_dev_add_attribute的作用
到这里位置,igb_uio的初始化以及注册过程都已经完成了,最终表现形式便是在/dev/uio创建了一个uio设备,这个设备是用来衔接内核态的中断信号与用户态应用的,关于uio申请中断这里的细节以后会专门开一篇文章介绍DPDK的中断,这里先不予介绍。介绍到这里,贴一张数据结构关系图供大家理解,见图18.
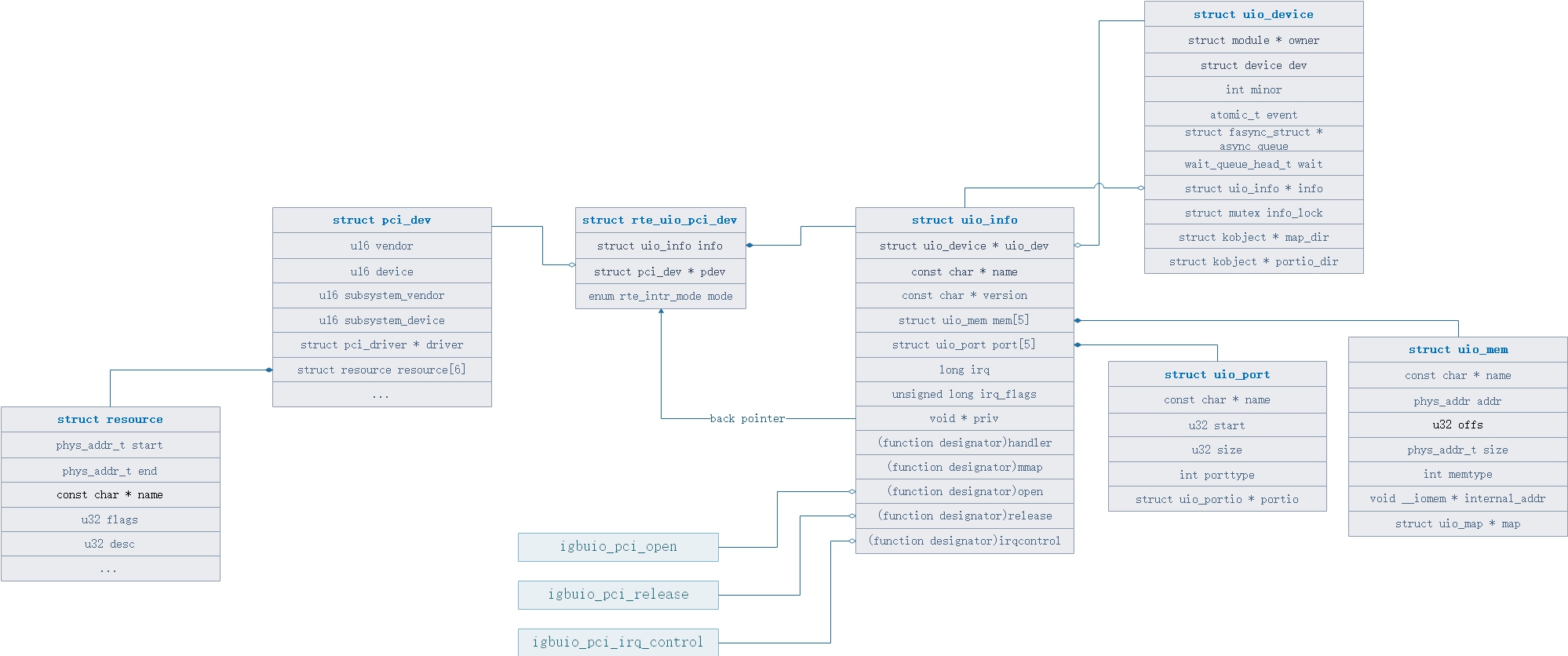
图18.数据结构关系
- struct resource : 内核将PCI BAR的信息存储在这个数据结果中,可以理解为PCI BAR的抽象,可以理解这个resource结构体就对应了/sys/bus/pci/devices/[pci_addr]/resource文件
- start : PCI BAR空间起始地址(这里不一定是内存空间还是IO空间);
- end : PCI BAR空间的结束地址;
- name : PCI BAR的名字,例如BAR 0、BAR1、BAR2....BAR5;
- flags : PCI BAR的标识,如果flags & 0x00000200则为内存空间,如果flags & 0x00000100则为IO空间;
- desc : IO资源描述符
- struct pci_dev : pci设备的抽象,可以理解为一个struct pci_dev就代表一个pci设备
- vendor : 生产商id,intel为0x0806,见/sys/bus/pci/devices/[pci_addr]/vendor文件;
- device : 设备id;
- subsystem_vendor : 子系统生产商id;
- subsystem_device : 子系统设备id;
- driver : 当前PCI设备所用驱动;
- resource : 当前pci设备的pci bar资源;
- struct rte_uio_pci_dev : igb_uio的抽象,可以理解为igb_uio本身
- info : 用于关联uio信息;
- pdev : 用于关联pci设备;
- mode : 中断模式配置
- struct uio_info : uio 信息配置的抽象
- uio_dev : 用来指向所属于的uio设备实例;
- name : 这个uio设备的名字,例如/dev/uio0,/dev/uio1,/dev/uio2;
- mem : 同样是PCI BAR资源,不过这里是已经做了区分,特指Memory BAR,这里的值仍然来自于内核的resource结构体,不过这里往往是将内核resource结构体映射后的值,可以理解为原始数据“加工”后的值;
- port : 同样是PCI BAR资源,不过这里是已经做了区分,特质Port BAR,这里的值仍然来自于内核的resource结构体,不过这里往往是将内核resource结构体映射后的值,可以理解为原始数据“加工”后的值;
- irq : 中断号;
- irq_flags : 中断标识;
- priv : 一个回调指针,指向dpdk的igb_uio驱动实例,其实这个字段的设计并不是为了专门服务于dpdk的igb_uio;
- handler、mmap、open、release、irqcontrol:分别为几个函数钩子,例如对/dev/uio进行open操作后,最终就会通过uio的file_operations -> open调用到igbuio_pci_open中,可以理解为open操作的内部实现;
- struct uio_device : uio设备的抽象,其实例可以代表一个uio设备
- 这里的内容不多加介绍,因为关于一个uio设备的主要配置和信息都在uio_info结构中
- struct uio_mem : 经过对resource进行处理后的Memory BAR信息,这里的信息主要是指的对PCI BAR进行ioremap
- name : PCI Memory BAR的名字,例如BAR 0、BAR1、BAR2....BAR5;
- addr : PCI Memory BAR的起始地址,为物理地址,这个地址必须经过ioremap映射后才可以给内核空间使用;
- offs : 偏移,一般为0;
- size : PCI Memory BAR的大小,通常可以用resource文件中的第二列(PCI BAR的终止地址)和resource文件中的第一列(PCI BAR的起始地址) + 1计算得出;
- memtype : 这个Memory Bar的内存类型,可以选择为物理地址、逻辑地址、虚拟地址三种类型,在DPDK的igb_uio中赋值为物理地址;
- internal_addr : 这个是一个关键,这个值即为PCI Memory BAR起始地址经过ioremap映射后得到的可以在内核空间直接访问的虚拟地址,当然之前也描述过,这个地址对于uio这种设计理念的设备而言是不需要的;
以上便是关于igb_uio、uio代码中主要的数据结构关系以及数据结构之间的字段介绍,那么重新思考那个问题:
假设不局限于DPDK的igb_uio,也不考虑内核开放出来的resource0..N,uio该怎么向用户空间暴露PCI BAR提供给用户空间使用呢?
经过上述的流程分析和数据结构的分析,我们起码可以知道一个事实,那就是uio内部其实是拿得到PCI BAR资源的,那么该怎么将这个BAR资源给用户态应用使用呢?答案其实也很简单,就是对/dev/uio0..N这个设备调用mmap进行内存映射,调用mmap之后,将会转到内核态事先注册好的file_operations.mmap钩子函数上,也就是调用uio_mmap,调用流程如图19所示:
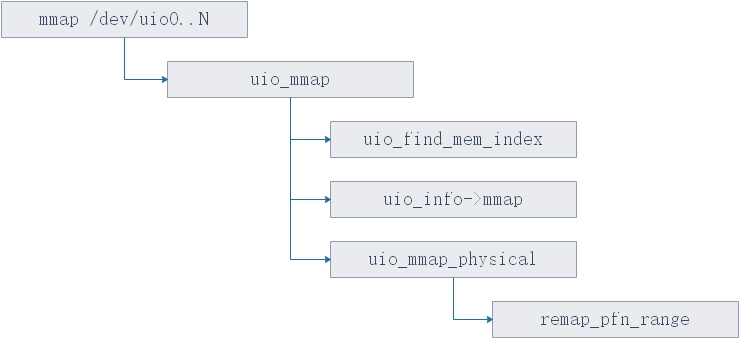
图19.mmap /dev/uio0..N的内核态函数调用流程
当然之前也说过,igb_uio其实完全没有做mmap这块的工作,因此uio_info->mmap这个钩子函数其实是NULL,所以DPDK完全不靠igb_uio得到PCI BAR,而是直接调用内核已经映射过的resource0..N即可。
现在回到第二章的那三个Question上,现在经过3、4、5这三章的讲解,已经完全可以回答第一个Questions
Q:igb_uio/vfio-pci的作用是什么?为什么要用这两个驱动?这里的“驱动”和dpdk内部对网卡的“驱动”(dpdk/driver/)有什么区别呢?
A:igb_uio主要作用是实现了两个功能,第一个功能是将PCI设备进行take-over,以此来屏蔽掉内核驱动和内核协议栈;第二个功能是实现了一个桥梁的作用,衔接内核态的中断与用户态(当然中断的内容会在后续开始讲解)。
【6.如何将PCI设备的驱动重新绑定】
这个操作其实只需要两个步骤:
- 将当前PCI设备的现有驱动目录下的unbind写入PCI设备的PCI地址,例如:
- echo "0000:81:00.0" > /sys/bus/pci/drivers/ixgbe/unbind
- 拿到当前PCI设备的device id和vendor id,并将其写入新的驱动的new_id中,例如我手头上的intel 82599网卡的device id是10fb,intel的vendor id是8086,那么绑定例子如下:
- echo "8086 10fb" > /sys/bus/pci/drivers/igb_uio/new_id
那这么做背后的原理是什么呢?其实也很简单,在内核源代码目录/include/linux/devices.h中有这么一组宏:
#define DRIVER_ATTR_RW(_name) \ struct driver_attribute driver_attr_##_name = __ATTR_RW(_name) #define DRIVER_ATTR_RO(_name) \ struct driver_attribute driver_attr_##_name = __ATTR_RO(_name) #define DRIVER_ATTR_WO(_name) \ struct driver_attribute driver_attr_##_name = __ATTR_WO(_name)
代码5.对于attribute的三种声明
利用这三种宏声明的attribute,最终在文件系统中就是这个驱动中的attribute文件的状态,Linux中万物皆文件,这些attribute实际上就是/sys/bus/pci/drivers/[driver_name]/目录下的文件。例如以上述两个步骤中使用的unbind和new_id为例,代码位于/driver/base/bus.c中
/* * PCI设备驱动的unbind属性实现 */ static ssize_t unbind_store(struct device_driver *drv, const char *buf, size_t count) { struct bus_type *bus = bus_get(drv->bus); struct device *dev; int err = -ENODEV; //先根据写入的参数找到设备,根据例子命令,便是根据"0000:08:00.0"这个pci地址找到对应的pci设备实例 dev = bus_find_device_by_name(bus, NULL, buf); if (dev && dev->driver == drv) { if (dev->parent && dev->bus->need_parent_lock) device_lock(dev->parent); //pci设备释放驱动,其中调用的就是driver或者bus的remove钩子函数,然后再将device中的driver指针置空 device_release_driver(dev); if (dev->parent && dev->bus->need_parent_lock) device_unlock(dev->parent); err = count; } put_device(dev); bus_put(bus); return err; } static DRIVER_ATTR_WO(unbind); //进行attribute生命,声明为只写
代码6.unbind attribute的实现
可以看到对unbind文件进行写操作后,最终会转到内核态的pci设备的unbind_store函数,这个函数的内容也非常简单,首先根据输入的PCI 地址找到对应的PCI设备实例,然后调用device_release_driver函数释放device相关联的driver,而new_id的属性实现则是在/drivers/pci/pci-driver.c中,函数调用流程即为图14中的下半部分,最终会调到驱动的probe钩子上,在igb_uio驱动中即为igbuio_pci_probe函数。
以上,便是dpdk-devbinds实现驱动的解绑以及重绑的实现,有兴趣的可以自己写个pyhon或者shell脚本试一下。
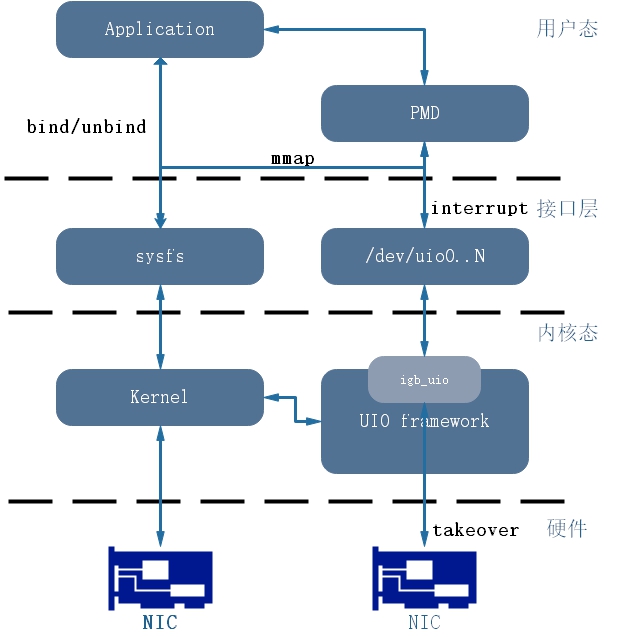
图20,层级结构
图20是个人理解:
- 内核接管硬件并将PCI BAR通过sysfs暴露给用户态,供用户态对其mmap后直接访问Memory BAR空间;
- 应用层程序通过sysfs接口实现pci设备的驱动的unbind/bind;
- UIO为一框架,无法独立生存,需要在框架的基础上开发出igb_uio,igb_uio实现了uio设备的生命周期管理全权交给用户态应用掌管;
- 其中中断信号仍然只能在内核态处理,不过uio通过创建/dev/uio来实现了一个"桥梁"来衔接用户态和内核态的中断处理,这时已经可以将用户态应用视为一种"中断下半部";
- Application为最终的业务层,只需要调用PMD的对上接口即可;
【7.后话】
1.3-6章的讲解,基本解决了第二章的前两个Questions,最后一个Questions以及DPDK如何实现的中断,以及vfio的解析会在后续文章中逐一发出。
2.这篇文章花费了较多的精力完成,并且内容较多,涉及到的知识也多为底层知识,因此其中难免会存在错别字、语法不通顺、以及笔误的情况,当然理解错误的地方也可能存在,还望各位朋友能够点明其中不合理的分析以及疏漏。
3.写完这篇文章后,不禁再次感慨,毕业如今一年半,遇到令我震撼的项目一共有两个,第一个是DPDK,第二个便是VPP,经过分析原理才发现,设计者是真的牛逼,根本不是我等菜鸡所能企及的存在...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号