


强化学习(九)-DQN的改进算法
一、Nature DQN
1、DQN缺点:只有一个神经网络,既选择动作,又估计价值,估计值容易过高;不能保证Q网络收敛,Q网络模型效果差
2、Nature DQN两个Q神经网络,在线网络用于动作选择,目标网络用于估计Q值,减少目标Q值计算和要更新Q网络参数之间的依赖
3、这两个神经网络结构是一样的
二、DQN的其他问题
1、目标Q值得计算是否准确?全部通过maxQ来计算有没有问题?Double DQN
2、经验回放里的不同样本,重要性不一样,TD误差大的样本更重要,所以随机采样的方法好吗?Prioritisted Replay DQN
3、Q值代表状态、动作的价值,单独评估是不是更准确?Dueling DQN
三、Double DQN,双深度Q网络
1、DQN的目标值,是通过贪婪法找max值获得的,会产生过度估计问题(over estimation),有估计偏差
2、Double DQN,两个神经网络,解耦目标Q值的动作选择和计算,在线网络用于动作选择,目标网络用于估计Q值,从而消除贪婪法带来的偏差
3、与Nature DQN只有1个不同点:
优化目标Q值
不是直接在目标Q网络里,寻找每个动作的最大Q值
而是先在当前的Q网络中,找到最大Q值得动作,然后用这个动作,在目标网络里,计算目标Q值
三、Prioritisted Replay DQN(优先级回放DQN)
1、对经验回放的部分做优化,之前的算法都是从经验回放里,用相同的概率,进行随机采样
2、TD误差=目标Q网络计算的目标Q值-当前Q网络计算的Q值
3、不同样本的TD误差不同,误差越大,反向传播的作用越大
4、对TD误差的绝对值大的样本进行采样的概率越大,算法越容易收敛
5、Prioritisted Replay DQN会把优先级(和TD误差的绝对值成正比)也放入经验回放池
6、经验回放池是sumTree二叉树,样本只保存在叶子节点中
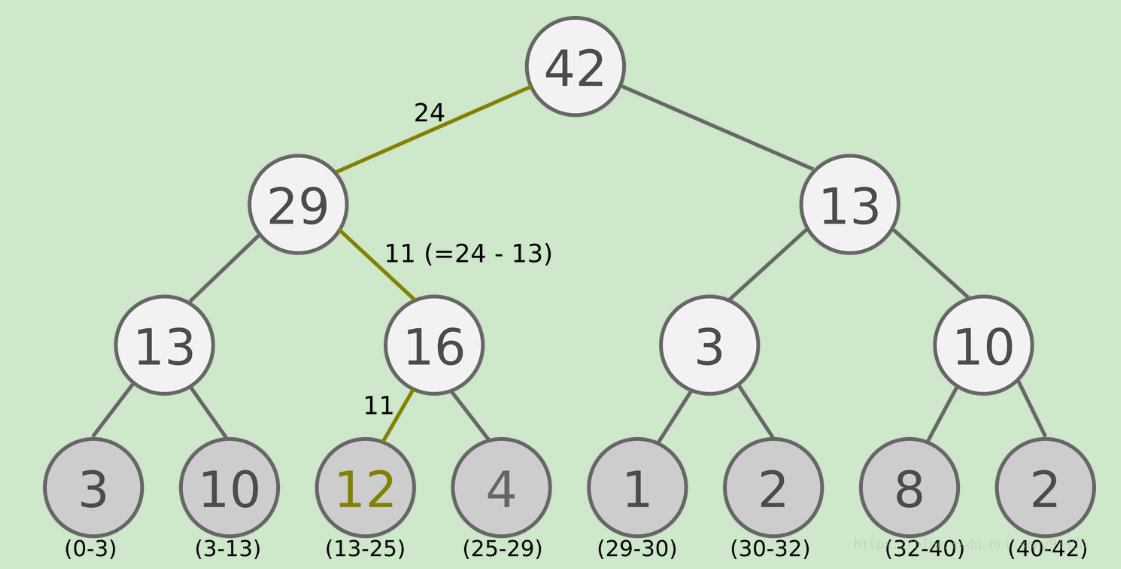
7、对Q网络参数进行了梯度更新后,需要重新计算TD误差,并更新到sumTree上
8、收敛速度有了很大提高,避免了一些没有价值的迭代
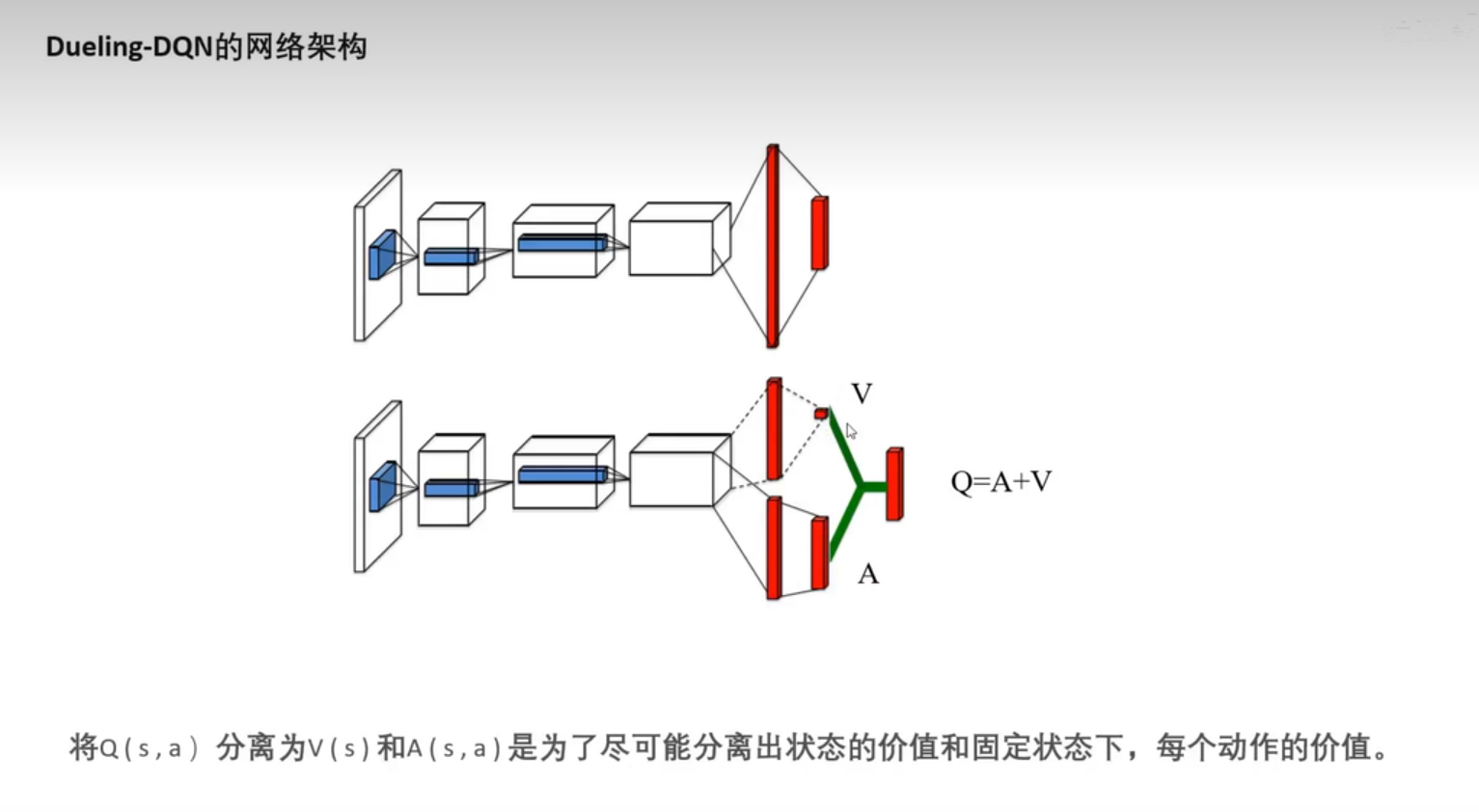
四、Dueling DQN,竞争深度Q网络
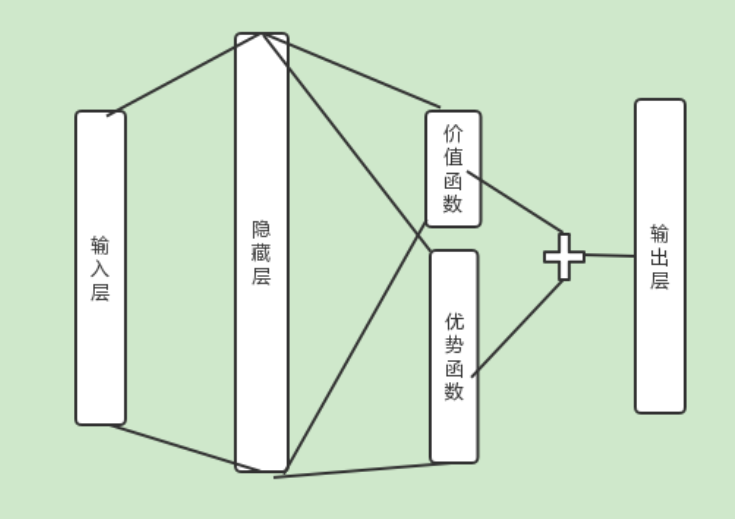
1、优化神经网络的结构,把Q网络分为两部分:
价值函数部分:只与状态S有关,与动作A无关
优势函数部分:同时与状态S和动作A有关
2、Q网络的计算过程表达式:
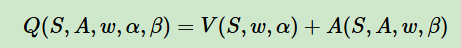
w:公共的网络参数
a:价值函数的网络参数
b:优势函数的网络参数
3、网络结构
五、噪声网络
1、在Q函数的每一个参数上,加上高斯噪声,变成噪声Q函数
2、在每一个网络权重参数上,加上高斯噪声,得到噪声网络
六、分布式Q函数
七、连续动作的深度Q网络
1、深度Q网络比策略梯度稳定,但是难以处理连续动作
2、解决方法:
对动作进行采样
梯度上升
设计网络架构
参考:
https://datawhalechina.github.io/easy-rl/#/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号