
强化学习(五)-时序差分法TD求解
一、概述
1、蒙特卡洛法的缺点:需要一个经历完整的状态序列,从中采样;如公式里的奖励Rt+1到RT,表示完整状态序列的奖励
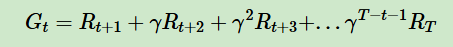
2、时序差分(Temporal-Difference,TD),不基于环境的状态转化概率模型,也不需要经历完整的状态序列,介于动态规划和蒙特卡洛方法之间
3、是现在主流的强化学习求解问题的方法
二、自举和采样
1、自举(bootstrapping):更新时使用了估计,用TD目标近似代替Gt的过程
2、采样:更新时通过采样得到一个期望
3、动态规划只使用了自举,蒙特卡洛只使用了采样,时序差分同时使用了自举和采样
三、时序差分算法
1、贝尔曼方程如下,对比蒙特卡洛方程,可以用Rt+1+γV(St+1)近似代替Gt,只需要两个连续的状态与对应奖励
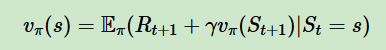
2、时序差分目标(TD target):带着衰减的未来奖励的总和,即Rt+1+γV(St+1)
3、时序差分误差(TD error):
a.衡量智能体对未来收益的“当前预测值”和“新观测后修正值”之间的误差
b.是TD学习算法(Sarsa,Q-learning)更新价值函数的核心依据
c.价值函数的学习,依赖于对预测的不断修正,而TD误差是修正的标尺
d.公式:Rt+1+γV(St+1)-V(St),解释:即时奖励+未来状态的预测价值,来修正当前状态的预测价值
四、预测和控制
1、预测问题求解
预测问题:估计某个给定策略的价值
时序差分可以解决预测问题
2、控制问题求解
控制问题:如何优化价值函数,得到最佳策略
在线控制算法:SARSA,只有一个策略,也叫同策略
离线控制算法:Q-Learning,有两个策略,一个用于选择动作,一个用于更新价值函数,也叫异策略
五、动态规划、蒙特卡洛、时序差分三种算法比较
1、相同点:都是描述与更新价值函数,都基于对未来事件的展望,计算一个回溯值
2、不同点:
动态规划:有模型,自举
蒙特卡洛:无模型,采样
时序差分:无模型,自举+采样
参考:
https://www.cnblogs.com/pinard/p/9529828.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号