

强化学习(二)-马尔可夫决策过程MDP
一、介绍
1、马尔可夫决策过程MDP,可以用方程组求解,简化强化学习的建模
2、马尔可夫性质:未来状态的条件概率分布,仅依赖于当前状态,将来状态和过去状态是独立的
3、马尔可夫过程:满足马尔可夫性质的过程
4、马尔可夫链:离散时间的马尔可夫过程,叫马尔可夫链,是最简单的马尔可夫过程
5、马尔可夫奖励过程:马尔科夫链+奖励函数
6、马尔可夫决策过程MDP:
马尔可夫奖励过程+决策,因此未来状态不仅依赖于当前状态,也依赖于当前动作
强化学习是一个与时间相关的序列决策问题
MDP是序列决策的经典的表现方式,是强化学习里一个基本的学习框架
MDP四元组:(S、A、P、R)状态、动作、状态转移概率、奖励
二、贝尔曼方程
1、价值函数,和状态和动作都有关系
2、状态价值函数
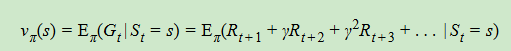
3、动作价值函数
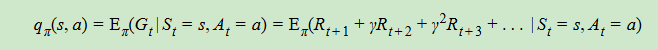
4、状态价值函数,可以表示为递推式,即状态价值函数的贝尔曼方程,表示当前状态与未来状态的迭代关系
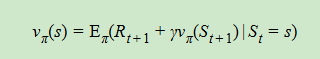
5、同理可得,动作价值函数的贝尔曼方程
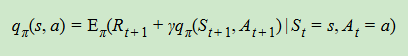
6、状态价值函数和动作价值函数,也可以相互表示和转化,某个状态下,所有动作的价值乘以该动作的概率,然后求和,得到对应的状态价值
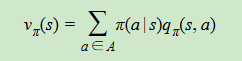
7、利用贝尔曼方程,也可以推导出下式,即状态动作价值由两部分组成
第一部分是即时奖励
第二部分是所有可能出现的下一个状态的价值,乘以其概率,然后求和,并加上衰减
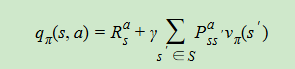
三、最优价值函数
1、强化学习的目的:找到最优策略,使价值最大
2、最优策略不好找,可以找一个局部最优策略,找到状态价值函数、动作价值函数的局部最优值
3、根据状态、动作价值函数的关系式,得到最优价值函数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号