

强化学习(十一)-Actor Critic
一、概念
1、融合了以价值学习为基础的算法(例如Q Learning)和以策略学习为基础的算法(例如Policy Gradient)
2、Actor对应Policy Gradient,在连续的行为中,基于概率选择合适的行为,回合更新,根据得分来修改选择行为的概率
3、Critic对应Q Learning,单步更新,用来评判行为的得分
二、从Policy Gradient到Actor Critic的转化
1、策略梯度没有Critic,但可以使用蒙特卡洛法,计算每一步的价值,相当于Critic的部分功能,场景比较受限
2、可以类似DQN,用价值函数代替蒙特卡洛法,作为一个通用的Critic
3、有两组近似:
策略函数近似
价值函数近似
4、总结
Critic通过Q网络,来计算状态的最优价值Vt
Actor使用Vt,迭代更新策略函数的参数θ,进而选择动作,得到反馈和新的状态
Critic使用反馈和新的状态,更新Q网路参数w,帮助Critic计算状态的最有价值
三、优缺点
1、优点:可以单步更新,比传统的Policy Gradient要快
2、缺点:取决于critic的评判标准,但是critic难以收敛,有可能学不到东西
四、Actor-Critic算法的可选形式
1、基于状态价值
2、基于动作价值
3、基于TD误差
4、基于优势函数
5、基于TD(λ)误差
五、流程
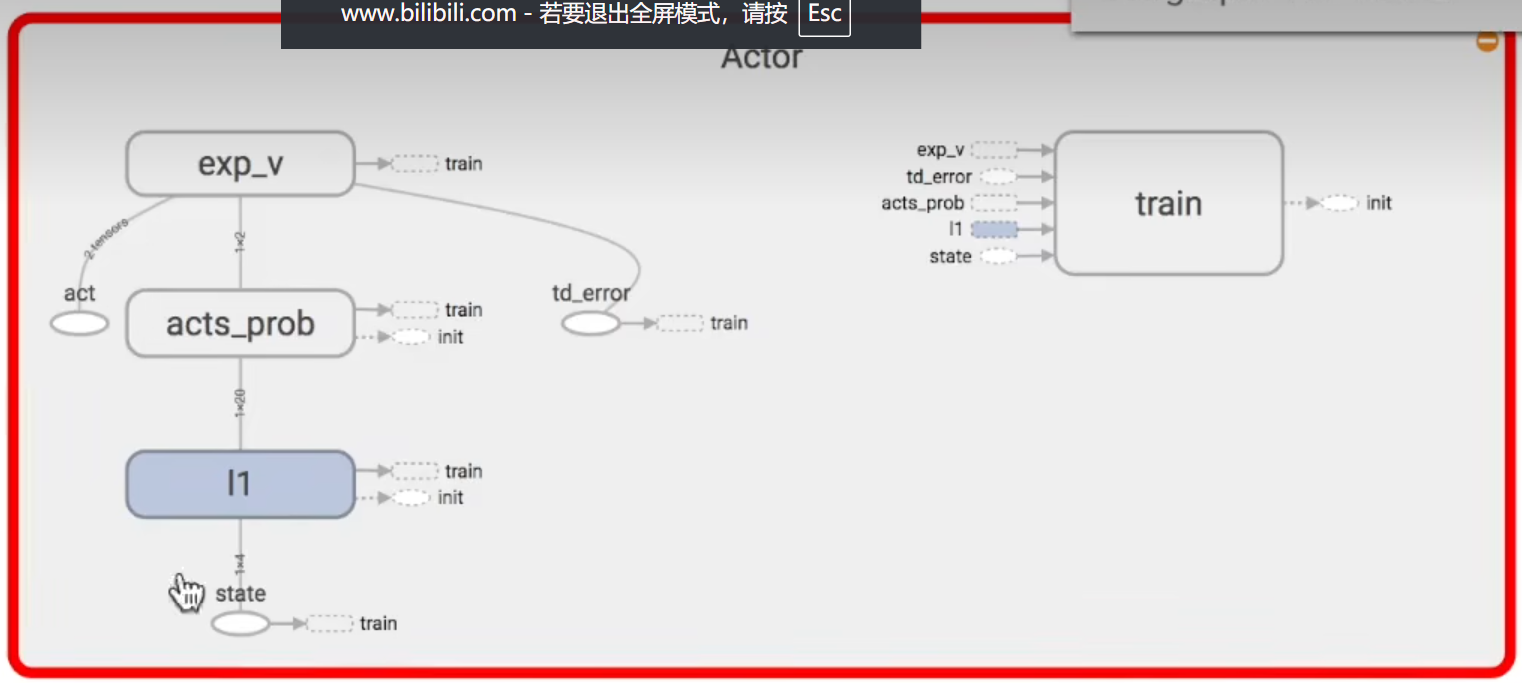
1、Actor:输入state,输出预测的行为的概率,通过概率优化行为,需要使用Critic给的td_error进行处理
2、Critic:输入state,输出这个状态的价值,生成td_error

六、代码
import numpy as np import tensorflow as tf import gymnasium as gym np.random.seed(2) tf.random.set_seed(2) # reproducible # Superparameters OUTPUT_GRAPH = False MAX_EPISODE = 3000 DISPLAY_REWARD_THRESHOLD = 200 # renders environment if total episode reward is greater then this threshold MAX_EP_STEPS = 1000 # maximum time step in one episode RENDER = False # rendering wastes time GAMMA = 0.9 # reward discount in TD error LR_A = 0.001 # learning rate for actor LR_C = 0.01 # learning rate for critic env = gym.make('CartPole-v1', render_mode='human') env = env.unwrapped N_F = env.observation_space.shape[0] N_A = env.action_space.n class Actor(tf.keras.Model): def __init__(self, n_features, n_actions, lr=0.001): super(Actor, self).__init__() self.n_actions = n_actions # Build the network self.dense1 = tf.keras.layers.Dense( 20, activation='relu', kernel_initializer=tf.keras.initializers.RandomNormal(0., 0.1), bias_initializer=tf.keras.initializers.Constant(0.1) ) self.dense2 = tf.keras.layers.Dense( n_actions, activation='softmax', kernel_initializer=tf.keras.initializers.RandomNormal(0., 0.1), bias_initializer=tf.keras.initializers.Constant(0.1) ) self.optimizer = tf.keras.optimizers.Adam(learning_rate=lr) def call(self, state): x = self.dense1(state) return self.dense2(x) def learn(self, s, a, td_error): s = tf.expand_dims(s, 0) with tf.GradientTape() as tape: acts_prob = self(s) log_prob = tf.math.log(acts_prob[0, a]) loss = -log_prob * td_error # negative because we want to maximize gradients = tape.gradient(loss, self.trainable_variables) self.optimizer.apply_gradients(zip(gradients, self.trainable_variables)) return loss def choose_action(self, s): s = tf.expand_dims(s, 0) probs = self(s) return np.random.choice(self.n_actions, p=probs.numpy().ravel()) class Critic(tf.keras.Model): def __init__(self, n_features, lr=0.01): super(Critic, self).__init__() # Build the network self.dense1 = tf.keras.layers.Dense( 20, activation='relu', kernel_initializer=tf.keras.initializers.RandomNormal(0., 0.1), bias_initializer=tf.keras.initializers.Constant(0.1) ) self.dense2 = tf.keras.layers.Dense( 1, activation=None, # linear activation for value function kernel_initializer=tf.keras.initializers.RandomNormal(0., 0.1), bias_initializer=tf.keras.initializers.Constant(0.1) ) self.optimizer = tf.keras.optimizers.Adam(learning_rate=lr) def call(self, state): x = self.dense1(state) return self.dense2(x) def learn(self, s, r, s_): s = tf.expand_dims(s, 0) s_ = tf.expand_dims(s_, 0) # Get next state value v_next = self(s_) with tf.GradientTape() as tape: v_current = self(s) td_error = r + GAMMA * v_next - v_current loss = tf.square(td_error) gradients = tape.gradient(loss, self.trainable_variables) self.optimizer.apply_gradients(zip(gradients, self.trainable_variables)) return td_error.numpy()[0, 0] # return scalar td_error # Initialize actor and critic actor = Actor(n_features=N_F, n_actions=N_A, lr=LR_A) critic = Critic(n_features=N_F, lr=LR_C) # we need a good teacher, so the teacher should learn faster than the actor for i_episode in range(MAX_EPISODE): s, info = env.reset() t = 0 track_r = [] while True: if RENDER: env.render() a = actor.choose_action(s) s_, r, terminated, truncated, info = env.step(a) done = terminated or truncated if done: r = -20 track_r.append(r) td_error = critic.learn(s, r, s_) # gradient = grad[r + gamma * V(s_) - V(s)] actor.learn(s, a, td_error) # true_gradient = grad[logPi(s,a) * td_error] s = s_ t += 1 if done or t >= MAX_EP_STEPS: ep_rs_sum = sum(track_r) if 'running_reward' not in globals(): running_reward = ep_rs_sum else: running_reward = running_reward * 0.95 + ep_rs_sum * 0.05 if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True # rendering print("episode:", i_episode, " reward:", int(running_reward)) break

 浙公网安备 33010602011771号
浙公网安备 33010602011771号