

强化学习(十)-Policy Gradient
一、概念
1、DQN的缺点:
对连续动作的处理能力不足
对受限状态下的问题处理能力不足
无法解决随机策略问题
2、基于策略的算法,是对策略近似表示成一个连续的函数
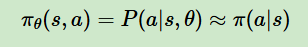
3、寻找最优策略的方法是梯度上升
二、特点
1、不根据奖惩的值,直接输出action,不需要value
2、能够在一个连续区间内,选择动作,而基于奖惩值的算法,消耗太大
3、通过神经网络,来输出action
三、策略梯度算法
1、策略梯度公式
2、策略函数
四、蒙特卡洛策略梯度reinforce算法
1、是一个经典的策略梯度算法
2、使用价值函数v(s)来近似代替策略梯度公式里的Qπ(s,a)
3、但是需要完全的序列样本才能做算法迭代
4、计算过程
根据一个确定好的策略模型,输出每一个可能动作的概率
采样一个动作,与环境交互,环境反馈整个回合的数据
将回合数据,输入学习函数,并构造损失函数
通过优化器优化,再更新策略模型
五、反向传递
1、没有误差,而是让行为反向传递
2、目的是把当前选中的action,再下一次更有可能发生
3、在行为反向传递的时候,在这个时候才进行奖惩
4、不是单步更新,而是回合更新的
六、策略梯度优化技巧
1、添加基线
为了防止所有奖励都为正,需要减去基线b,让奖励有正有负,正就上升概率,负就降低概率
2、分配合适的分数
之前的回报为总奖励,改为从t时刻到结束的奖励,并且对未来的奖励打折扣
3、优势函数
综合了上面的两种方法,在状态S时采取动作A,计算优势函数的大小
七、代码
1、算法更新
import gymnasium as gym from RL_brain import PolicyGradient import matplotlib.pyplot as plt RENDER = True DISPLAY_REWARD_THRESHOLD = 400 env = gym.make('CartPole-v1', render_mode='human') env = env.unwrapped observation, info = env.reset(seed=1) print(env.action_space) print(env.observation_space) print(env.observation_space.high) print(env.observation_space.low) RL = PolicyGradient( n_actions=env.action_space.n, n_features=env.observation_space.shape[0], learning_rate=0.02, reward_decay=0.99, ) for i_episode in range(3000): observation, info = env.reset() while True: if RENDER: env.render() action = RL.choose_action(observation) observation_, reward, terminated, truncated, info = env.step(action) done = terminated or truncated RL.store_transition(observation, action, reward) if done: ep_rs_sum = sum(RL.ep_rs) if 'running_reward' not in globals(): running_reward = ep_rs_sum else: running_reward = running_reward * 0.99 + ep_rs_sum * 0.01 if running_reward > DISPLAY_REWARD_THRESHOLD: RENDER = True print('episode ', i_episode, ' reward ', running_reward) vt = RL.learn() if i_episode == 0: plt.plot(vt) plt.xlabel('episode steps') plt.ylabel('normalized state-action value') plt.show() break
2、思维决策
import numpy as np import pandas as pd import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers class PolicyGradient: # 1、初始化 def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.95, output_graph=False): self.n_actions = n_actions self.n_features = n_features self.lr = learning_rate self.gamma = reward_decay self.ep_obs, self.ep_as, self.ep_rs = [], [], [] self._build_net() self.optimizer = keras.optimizers.Adam(learning_rate=self.lr) # 2、建立神经网络 def _build_net(self): self.model = keras.Sequential([ layers.Dense(10, activation='tanh', kernel_initializer=keras.initializers.RandomNormal(mean=0, stddev=0.3), bias_initializer=keras.initializers.Constant(0.1), name="fc1"), layers.Dense(self.n_actions, activation=None, kernel_initializer=keras.initializers.RandomNormal(mean=0, stddev=0.3), bias_initializer=keras.initializers.Constant(0.1), name="fc2") ]) # 4、存储回合 def store_transition(self, s, a, r): self.ep_obs.append(s) self.ep_as.append(a) self.ep_rs.append(r) # 3、选择行为 def choose_action(self, observation): observation = tf.expand_dims(observation, 0) logits = self.model(observation) prob_weights = tf.nn.softmax(logits) action = np.random.choice(range(prob_weights.shape[1]), p=prob_weights.numpy().ravel()) return action # 5、学习,更新参数 def learn(self): discounted_ep_rs_norm = self._discount_and_norm_reward() observations = tf.convert_to_tensor(np.vstack(self.ep_obs), dtype=tf.float32) actions = tf.convert_to_tensor(np.array(self.ep_as), dtype=tf.int32) rewards = tf.convert_to_tensor(discounted_ep_rs_norm, dtype=tf.float32) with tf.GradientTape() as tape: logits = self.model(observations) action_probs = tf.nn.softmax(logits) # 计算负对数概率 neg_log_prob = tf.reduce_sum(-tf.math.log(action_probs) * tf.one_hot(actions, self.n_actions), axis=1) loss = tf.reduce_mean(neg_log_prob * rewards) gradients = tape.gradient(loss, self.model.trainable_variables) self.optimizer.apply_gradients(zip(gradients, self.model.trainable_variables)) self.ep_obs, self.ep_as, self.ep_rs = [], [], [] return discounted_ep_rs_norm # 6、衰减回合的reward def _discount_and_norm_reward(self): discounted_ep_rs = np.zeros_like(self.ep_rs) running_add = 0 for t in reversed(range(0, len(self.ep_rs))): running_add = running_add * self.gamma + self.ep_rs[t] discounted_ep_rs[t] = running_add discounted_ep_rs -= np.mean(discounted_ep_rs) discounted_ep_rs /= np.std(discounted_ep_rs) return discounted_ep_rs
参考:
https://datawhalechina.github.io/easy-rl/#/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号