

强化学习(八)-DQN
一、概念
1、基于表格的强化学习(Q-Learning和Sarsa),数据量大的情况下,很耗时,例如表格里的state太多
2、所以引入了DQN(Deep Q-Learning Network),它融合了神经网络和Q-Learning
3、并且使用价值函数近似:神经网络通过状态,近似表示状态/动作价值函数,就可以输出Q值,而不用经过复杂的表格计算,这里的神经网络又叫Q网络
二、神经网络训练过程
1、状态s2通过神经网络,获取Q(s2,a1),Q(s2,a2),即Q(s2)估计
2、计算Q(s')现实:R+γ*max[Q(s',a1),Q(s',a2)]
3、把α*(Q现实-Q估计),传递给神经网络进行学习
三、Expierence replay经验回放
1、每次和环境交互,把状态、动作、奖励、下一个状态,都保存到回放缓冲区中,缓冲区FIFO
2、用于后面目标Q值的更新,类似于Q表的功能
3、随机抽取之前的经历,用过去的经验数据进行学习,可以重复学习
4、打乱了经历之间的相关性,能让神经网络更好的学习
原因:通常使用梯度下降法,来训练神经网络,数据相关性会破坏梯度传递,使训练难以收敛
四、Fixed Q-targets 暂时冻结Q目标参数
1、如果一直更新价值网络的参数,会导致新目标不断变化,不稳定,增大回归难度
2、优化目标公式的左右两侧同时更新,不稳定;将公式等号右边固定,只更新左边
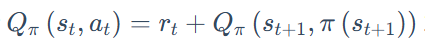
3、Q估计:Q为现在的参数,即每步都更新
4、Q现实:R+γ*maxQ‘,Q’为很久以前的参数,即隔了很多步(例如1000步)才更新
5、同样打乱经历之间的相关性,即切断相关性
五、DQN代码
1、算法更新
from RL_brain import DeepNetwork import sys import os sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__)))) from maze_env import Maze def run_maze(): step = 0 for episode in range(300): observation = env.reset() while True: env.render() action = RL.choose_action(observation) observation_, reward, done = env.step(action) RL.store_transition(observation, action, reward, observation_) if (step > 200) and (step % 5 == 0): RL.learn() observation = observation_ if done: break step += 1 print('game over') env.destroy() if __name__ == '__main__': env = Maze() RL = DeepNetwork(env.n_actions, env.n_features, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, replace_target_iter=200, memory_size=2000) env.after(100, run_maze()) env.mainloop() RL.plot_cost()
2、思维决策
import numpy as np import pandas as pd import tensorflow as tf from tensorflow import keras from tensorflow.keras import layers class DeepNetwork: def __init__(self, n_actions, n_features, learning_rate=0.01, reward_decay=0.9, e_greedy=0.9, replace_target_iter=300, memory_size=500, batch_size=32, e_greedy_increment=None, output_graph=False): self.n_actions = n_actions self.n_features = n_features self.lr = learning_rate self.gamma = reward_decay self.epsilon_max = e_greedy self.replace_target_iter = replace_target_iter self.memory_size = memory_size self.batch_size = batch_size self.epsilon_increment = e_greedy_increment self.epsilon = 0 if e_greedy_increment is None else self.epsilon_max self.learn_step_counter = 0 self.memory = pd.DataFrame(np.zeros((self.memory_size, self.n_features * 2 + 2))) # 构建网络 self.eval_net = self._build_net('eval_net') self.target_net = self._build_net('target_net') # 优化器 self.optimizer = keras.optimizers.RMSprop(learning_rate=self.lr) # 初始化目标网络参数 self._replace_target_params() self.cost_his = [] def _build_net(self, name): """构建神经网络""" model = keras.Sequential([ layers.Dense(10, activation='relu', input_shape=(self.n_features,), name=f'{name}_l1'), layers.Dense(self.n_actions, name=f'{name}_l2') ], name=name) return model def store_transition(self, s, a, r, s_): if not hasattr(self, 'memory_counter'): self.memory_counter = 0 # 处理maze环境的坐标数据,只取前两个坐标作为位置 if isinstance(s, list) and len(s) == 4: s = [s[0], s[1]] # 只取x, y坐标 if isinstance(s_, list) and len(s_) == 4: s_ = [s_[0], s_[1]] # 只取x, y坐标 elif s_ == 'terminal': s_ = [0, 0] # 终止状态用[0,0]表示 s = np.array(s).flatten() s_ = np.array(s_).flatten() transition = np.hstack((s, [a, r], s_)) index = self.memory_counter % self.memory_size self.memory.iloc[index, :] = transition self.memory_counter += 1 def choose_action(self, observation): # 处理maze环境的坐标数据,只取前两个坐标作为位置 if isinstance(observation, list) and len(observation) == 4: observation = [observation[0], observation[1]] # 只取x, y坐标 observation = np.array(observation)[np.newaxis, :] observation = tf.constant(observation, dtype=tf.float32) if np.random.uniform() < self.epsilon: actions_value = self.eval_net(observation) action = np.argmax(actions_value.numpy()) else: action = np.random.randint(0, self.n_actions) return action def learn(self): # 检查是否需要更新目标网络 if self.learn_step_counter % self.replace_target_iter == 0: self._replace_target_params() print('\ntarget params replaced\n') # 从记忆库中采样 if self.memory_counter > self.memory_size: batch_memory = self.memory.sample(self.batch_size) else: batch_memory = self.memory.iloc[:self.memory_counter].sample( self.batch_size, replace=True) # 准备批次数据 batch_s = tf.constant(batch_memory.iloc[:, :self.n_features].values, dtype=tf.float32) batch_a = batch_memory.iloc[:, self.n_features].astype(np.int32).values batch_r = tf.constant(batch_memory.iloc[:, self.n_features + 1].values, dtype=tf.float32) batch_s_ = tf.constant(batch_memory.iloc[:, -self.n_features:].values, dtype=tf.float32) # 计算目标Q值 q_next = self.target_net(batch_s_) q_eval = self.eval_net(batch_s) # 计算目标值 q_target = q_eval.numpy().copy() batch_indices = np.arange(self.batch_size, dtype=np.int32) q_target[batch_indices, batch_a] = batch_r + self.gamma * tf.reduce_max(q_next, axis=1) q_target = tf.constant(q_target, dtype=tf.float32) # 训练网络 with tf.GradientTape() as tape: q_pred = self.eval_net(batch_s) loss = tf.reduce_mean(tf.square(q_target - q_pred)) gradients = tape.gradient(loss, self.eval_net.trainable_variables) self.optimizer.apply_gradients(zip(gradients, self.eval_net.trainable_variables)) self.cost_his.append(loss.numpy()) # 更新epsilon if self.epsilon_increment is not None: self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max self.learn_step_counter += 1 def _replace_target_params(self): """将评估网络的参数复制到目标网络""" for target_param, eval_param in zip(self.target_net.trainable_variables, self.eval_net.trainable_variables): target_param.assign(eval_param) def plot_cost(self): import matplotlib.pyplot as plt plt.plot(np.arange(len(self.cost_his)), self.cost_his) plt.ylabel('Cost') plt.xlabel('Training Steps') plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号