

强化学习(一):概述
一、介绍
1、强化学习(reinforcement learning, RL)是人工智能(AI)的核心分支之一。
人工智能核心的分支有:
机器学习:一些经典的学习算法,例如线性回归、随机森林等,目前工业界主流已经很少单独使用
深度学习:通过神经网络进行学习
强化学习:通过试错进行学习
大模型:参数量很大(几千亿)的深度学习
2、强化学习的核心思想是通过试错来学习:
智能体(agent)通过与环境(environment)持续进行交互,每次交互得到奖励或者惩罚的反馈,从而优化策略,得到最大的奖励。
3、为什么研究强化学习
强化学习通过自己的试错学习,得到超过人类的表现,例如alpha go,围棋赢过人类冠军
而监督学习(机器学习、深度学习)是以人类标注的数据为依据,上限就是人类的表现
二、架构
1、两部分:环境、智能体Agent
2、三要素:状态state、动作action、奖励reward
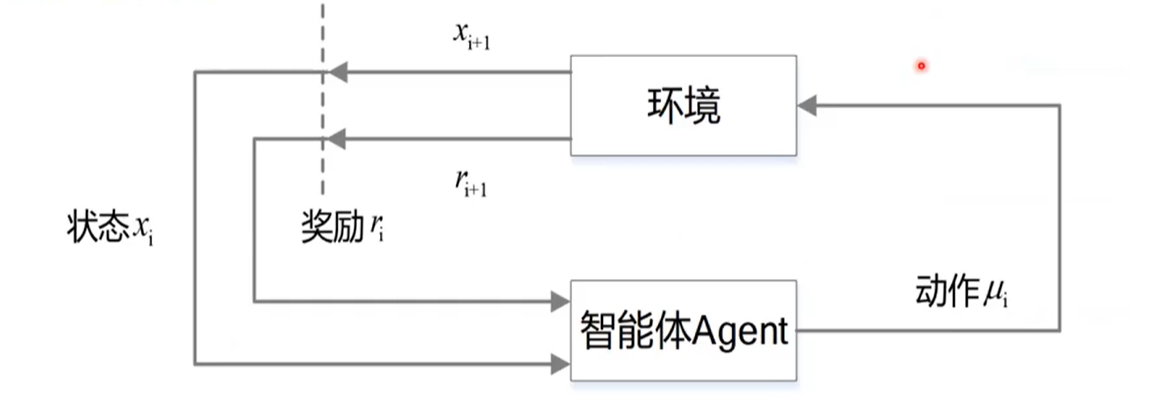
3、流程
在时刻t,state为St,agent做出决策,选择一个action(At),引起了状态state的变化;
在时刻t+1,state变成St+1,同时得到奖励Rt+1;
agent再次做出决策选择动作,循环该过程
4、目标
智能体最大化长期总收益,尽可能获取最大的奖励
三、要素解释
1、环境状态S,t时刻的状态为St,是环境状态集合里的某一个状态
2、agent的动作A,t时刻的动作为At,是动作集合(动作空间)里的某一个动作
3、环境的奖励R,t时刻,在状态St时,选择动作At,会在t+1时刻得到奖励Rt+1
4、个体策略π,个体会依据π来选择动作,例如π(a|s)=P(At=a|St=s),即在t时刻状态s时,动作选择a的概率
5、采取动作后的价值Vπ(s)
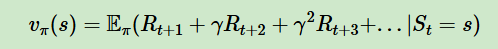
6、奖励衰减因子γ,在0和1之间,代入到上面的式子,为0表示价值只由当前奖励决定,为1表示后续奖励和当前奖励都一样,一般为0到1之间的数,表示离当前奖励越远,影响越小
7、概率状态机,即在t时刻状态s时,动作选择a,转化到下一个状态s'的概率
8、探索率ϵ,即不选择当前迭代轮次里,价值最大的动作的概率,提高了随机性,防止一些比较好的动作被错过
四、探索和利用
1、探索(exploration):尝试一些新的动作,但是有可能得到奖励,有可能得到惩罚
2、利用(exploitation):采取已知的获取奖励最多的动作,重复执行,但是未知动作有可能获得更高的奖励
3、探索利用窘境:需要对两者进行权衡
解决方法:
ε-贪心:有ε的概率随机,刚开始时,不知道哪个动作好,会花费大力气做探索;随着训练次数增多,就会减少探索;所以ε一直递减,随机性变小
玻尔兹曼探索:类似于梯度策略
五、价值函数
1、状态价值函数:输入是一个状态,根据状态,计算以后积累奖励的期望
2、动作价值函数:输入是一个状态-动作对,即某个状态,及在该状态下采取的动作;同时假设使用策略Π,计算积累奖励的期望
3、智能体的核心目标:学习价值函数,即某个状态(状态-动作对)下,未来能获得累计奖励的期望
六、强化学习的应用
1、游戏
2、自动驾驶
3、具身智能(机器人)
参考:
https://datawhalechina.github.io/easy-rl/#/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号