

深度学习(一)-神经网络概述(ANN/DNN)
一、ANN(Artificial Neural Network)人工神经网络
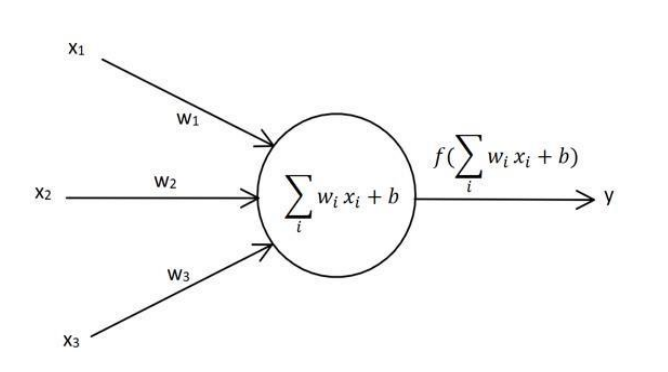
1、单层感知器,最简单的神经网络,有输入层和输出层,他们直接相连
公式:输入和权向量相乘,求和,再加上偏置因子,使用激活函数,得到y
输入:x1,x2,x3,输出y
普通参数:权重w1,w2,w3,偏置因子b
激活函数:f(x),是一个非线性函数,为了增强网络的表达能力,例如sigmoid;因为线性函数会使多层神经网络坍塌为1层,导致深度学习失效
每个神经元都有自己的权重和偏置
目标:根据给出的训练数据和公式,求出来w1,w2,w3和b,即得到一个模型,可以应用于其他数据
2、多层感知器
3、神经网络即按照一定规则连接起来的多个神经元
二、DNN(Deep Neural Network)深度神经网络
1、DNN一般是指全连接神经网络,即上一层的每个神经元,都会与下一层的所有神经元连接
2、本质是寻找一个合适的函数
三、基本步骤
1、建立模型,确定网络结构,多少层,每层多少个神经元
2、选择损失函数,用来衡量模型的预测值和真实值的差异
3、设置学习率,初始化每个神经元的权重和偏置
4、经过神经网络,得到最后输出的预测值,跟训练集的标签值做比较,计算损失
5、使用梯度下降、反向传播等方法,求总误差对某个神经元的偏导数,进行参数学习,得到更新后的权重参数
6、把所有权重和偏置的参数更新完,即完成一轮训练
7、重复该过程,使损失在预期范围内
说明:超参数是需要人工确定的参数,例如训练轮数、学习率、层数、神经元个数;相对于普通参数权重w和偏置b,是计算得到的
四、学习方式
1、目标:使损失函数最小
2、梯度下降(Gradient Descent,GD)
a.通过迭代调整模型参数(如权重和偏置)来最小化损失函数
b.随机梯度下降(Stochastic Gradient Descent,SGD)随机选取小批量样本,计算梯度并更新参数,而不是对所有的样本进行计算
虽然每次迭代精度低,但是速度快,可以训练更多的批次,比梯度下降效果更好,少而粗糙,优于多而精确
3、反向传播
a.信号正向传播,即数据流向是输入->输出的方向
b.误差反向传播(Back Propagation,BP),实际应用中,80%的神经网络,使用了BP
使用链式法则,求总误差对某个神经元的偏导数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号