C++培训文档
过于落后, 可以展示
-1. 在开始之前
有*标识的内容为可选内容, 不做强制要求, 但是是很有用的基础知识
学习编程最重要的不是学会编程, 而是学会怎么学习
突然了解到C++最多讲4~6h, 这样的话如果想细致入微得系统的学习C++最好是去看《C++ primer》《C++ primer plus》以及C++菜鸟教程(推荐) , 需要的话我这有电子版. 这两本书并没有任何关系, 单纯是plus版稍难, 而且都是大部头, 请做好心理准备, C++一直是一个很难的语言, 需要的是长久的学习和实践.
以及, 现在发达的互联网, 你可以在上面找到很多你想要的东西, 如果找不到那只能说是方法问题. (或者你确实是前无古人的大佬)
可以多了解几个网站:
百度 : 这个应该都很熟悉了
bing : 可以当成一个更纯净的百度, 搜索的质量还不错
B站 : 经典B站大学
CSDN : 一个程序员为主的博客网站, 可惜现在臭掉了
博客园 : 也是博客网站, 但是体量没有上者大, 但是名声好了不少, 2023.9.19更新: 现在要寄掉了/(ㄒoㄒ)/~~
谷歌 : Scientific-Surfing的孩子才能访问的网站
Github : 全球最大的同性交友网站
以及如果想要进队的话需要熟练掌握的: OpenCV, Git, Cmake(必备), Linux(Ubuntu即可), 强大的搜索与自学能力 , Python(最好)
其实在暗示你们都要学什么
2023.9.19更新, OpenCV除了4的最新版本之外, 其他都是可以的,
呃呃呃, 突然又了解到C++需要讲的内容经过了大量的扩充, 现在我们需要还要讲C++11&C++14的一些特性, 奇怪的任务又增加了
0. 什么是程序? *
以下是参考《计算机导论》中的内容, 如果觉得不够详细可以去看一下原书, 也很不错.
进制 *
在位置化数字系统中, 数字中符号所占据的位置决定了其表示的值.
其中, S是一套符号集, b是底(或基数), 它等于S符号集中的符号的总数.
可以预见, 十进制时有b=10, S={0~9}, 二进制时有b=2, S={0,1}, 八进制同理, 十六进制时b=16, S={0~9,A,B...F}
进制的转换
在进制的转换中需要我们把(1)中表达式转换到另一种样子, 这个过程可以把(1)的式子写成(2) 的样子然后求值, 转换.
在其他进制向十进制的转换中, 直接套(2)即可
十进制向N进制转换: 整数部分不断除N取余, 小数部分不断乘N取整
二进制, 四进制(不常用), 八进制, 十六进制的互相转换可以通过十进制作为中介, 也可以用特殊方法
再详细的教程请直接百度.
通用计算机
设想这么一个机器, 它有一个由一排小格子组成的数据存储器, 小格子排成一很长的排, 每个小格子中存放的是0或1, 还有一个既可以读取也可以写入小格子, 且能操作所有小格子的数据读写头.

最基础的命令是读写头左移, 右移, 读取, 写入, 然后我们可以在此基础上组件更多的命令.
我们可以用一套高级命令集来让它完成所有的计算任务, 所有的计算任务都可以通过编码转化成一长串命令.
这就是一个简陋的通用计算机.
对于一个通用计算机来说, 我们要求它可以通过不同的命令, 做到我们需要的任何计算任务, 在我们给定输入的时候得到我们想要的输出, 比如计算加减乘除或者让你玩一个游戏.
更进一步: 冯诺依曼模型
这样一个通用计算机已经很优秀了, 但是在成为我们手中的手机前还有一个很重要的问题没有解决, 我们不可能在需要一个计算任务时现场把命令输入到这个计算机当中, 然后看着读写头反复横跳.
这便引出了冯诺依曼模型, 其提出将这些命令也作为数据存储在计算机当中, 当我们需要的时候直接用计算机读取这些命令并执行. 这样的计算机可以由存储器, 运算器, 控制器(用于解析输入的命令并调取存储的命令), 和输入输出结构组成.
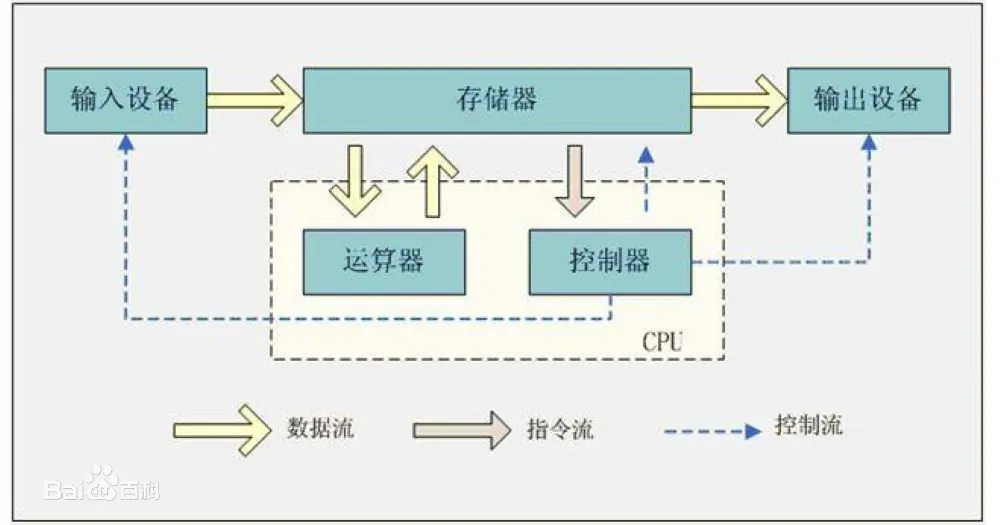
而这些存储在计算机中的命令即是我们所写的程序. 在这里我们需要强调一点, 即数据和程序是同样存储在计算机的存储器里的. 而想要区分不同类型的数据和程序, 我们需要额外的数据来表示我们存储的东西, 其一是给人和计算机看的后缀名, 但这个后缀名并不绝对, 他只是一个标识, 可以被人为修改, 其二是封装在数据中的数据头, 就是在我们保存的东西前面有一串用来标识数据的额外数据, 记录了这个数据是什么类型, 应该被怎么读取等( 个人理解, 有的数据类型可能没有 )
操作系统
以上要素已经能组成一个可以胜任任何计算任务的计算机了, 但是这个计算机仍然" 不好玩 ", 即人很难与之交互. 于是, 一种特殊的程序产生了, 这个程序可以合理的分配CPU,内存等等资源, 方便我们操作计算机, 这即是操作系统. 我在用的是Windows10操作系统, 在这以外还有很多不同的操作系统, 理论上这些操作系统应当是天差地别的, 但在编写它们的大佬们的不懈努力之下, 我们所用的很多软硬件以及对操作系统的使用方式基本上大差不差.
**可选作业: **用虚拟机安装linux系统, 具体操作请自行搜索
高级语言
最后回归主体, 引出我们的高级语言. 刚刚我们对程序的阐述已经能满足编程的需要了, 但是这使得编程变得十分困难, 我们总不能写几千万行的" 0101010 " 吧, 所以在计算机能直接理解的机器语言之上, 有了一些我们更便于理解, 可以翻译成机器语言的低级语言, 例如汇编语言(类似于"左移读写头, 读取, 右移读写头, 写入"之类的命令), 但是这仍不够, 由于汇编语言对于大型软件开发效率低下, 跨平台能力差, 直接操作硬件等问题, 在其之上又出现了高级语言, 这里就是JAVA, PYTHON, 以及今天的主角C++.
编译 & 链接库
这个东西作为基础知识的重要性十足. (虽然是长篇大论但是真的很重要)
前面我们提到的高级语言, 其样貌已经十分美观了, 我们可以用结构清晰且好看的方式打我们的代码 : 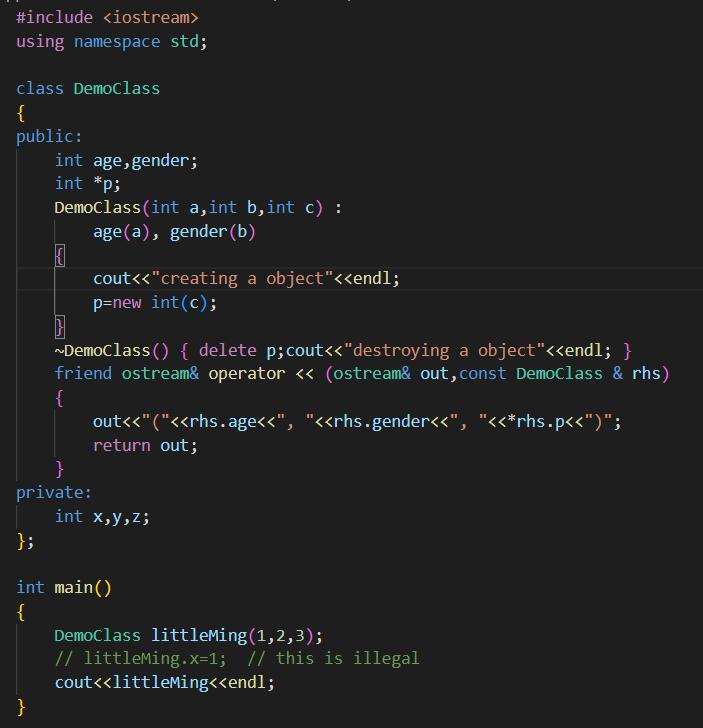
但是它显然并不能直接被计算机理解并执行, 我们的笨蛋计算机只能看懂0和1, 于是在我们打的C++代码与计算机之间有一个翻译官, 叫做编译器, 我们通过编译器来将我们写好的代码转换成计算机可以执行的.exe(01010)文件( 此后我们将专注于讲有关C++的东西, 这部分内容对于PYTHON和JAVA来说已经开始有所不同了 )
同时, 由于大型软件需要非常非常多的代码. 这通常需要很多人的协作编写才能完成, 有时是几百人, 有时是几万人, 同时有的时候我们需要用一些其他大佬已经写好的非常优秀的代码, 于是「可以在我们自己的代码里调用别人的代码」变得十分重要.
但是, 我们调用别人的代码时, 别人的代码有可能有几十万行, 而我们自己的代码仅有短短几十行, 或者说, 我们有一个几十万行的工程代码, 在经过编译器的翻译后( 通常这需要很久很久的时间, 比如一两个小时 )我们发现其中一点有一个小小的bug, 我们只需要修改一行的代码, 但我们又不想再去编译这几十万行的代码了, 所以编译器的工作流程分成了两个大步骤, 分别是编译和链接.
在编译过程, 它将不同文件的代码先进行初步编译, 形成目标文件, 这里不同的文件可以形成一一对应的目标文件, 这样我们就不必重复编译已有的代码了, 然后在链接过程中, 它组合不同目标文件, 加上我们调用的由其他代码形成的机器语言文件, 形成.exe可执行文件.
刚刚我们提到的其他代码形成的机器语言文件通常我们称作链接库, 链接库一般保存在系统的固定位置. 而配置我们的系统, 把链接库放到对应的位置, 以及一些其他工作, 来让我们的系统可以完成对C++文件的编译的过程称作配置语言环境. 一般来说配置语言环境是最折磨的步骤,也是因此Python获得了一个巨大的优点:基本上一键就能配置完成环境
同时链接库也分为动态链接库和静态链接库, 静态链接库.lib & .a是在最终生成.exe可执行文件的时候被加入到我们的.exe文件里, (这并不完美, 因为一个机器语言的库通常很大, 而常用的库就会被复制成百上千遍, 而且在一个库更新之后, 所有链接过的文件并不能及时更新), 而动态链接库.dll & .so并不加入到.exe文件, 而是在其运行的时候被系统调用, (Windows一般叫动态链接库, 而Linux上叫做共享库)
以上我们可以打一个非常恰当的比喻. 编程就好像是在造车, 一开始写代码就是在画图纸, 然后把图纸交给工人"编译器"来按照图纸生产车辆, 图纸肯定包含了很多部件, 我们的工人"编译器"就先阅读各个部件的蓝图, 进行初步的理解, 这就是第一步编译的过程, 而图纸中包含了一个非常牛逼的发动机, 这个是我们调用的已经编译好的代码, 工人就去市场(操作系统)中找, 找到了就买来并按照图纸安装在需要的位置(链接), 然后进行组装(生成.exe文件), 造出了一辆车.
所以在配置我们的C++或是OpenCV语言环境的时候, 我们分别需要: 获取编译器, 配置include库, 配置链接库
1. C++入门
配置C++语言环境 *
看我操作. 具体步骤请上网搜索. 搜索能力也是很重要的一环.
**作业: **请自行完成配置自己电脑的语言环境以及安装VScode
Hello World !
#include <iostream>
using namespace std;
int main()
{
cout<<"Hello World"<<endl; // 这是单行的注释
return 0;
}
/*
这是多行的注释
*/
// 注释会被计算机自动的忽略掉, 并不影响我们的程序
进行逐行的解读
#include <iostream> // 包含标准的输出输出, 有了它我们就可以用后文的输出了
using namespace std;
/* 这两行的作用会在之后的学习中揭晓, 目前可以单纯的记住需要这么打, 注意全部都是英文输入法, 并注意大小写 */
// 一定要注意英文输出法!!! 注意大小写!!!
int main()
{
// 这是我们程序的主体部分, 我们写在这里的内容才会被依次的进行
// main后面的() 以及 {} 注意不要忘了
}
int main()
{
cout<<"Hello World"<<endl; // cout是输出, 这里输出一个字符串, 字符串的内容是"Hello World"
// 在<<"Hello World"之后又输出了一个东西 <<endl即是用来给输出换行
return 0; // 结束程序的内容
// 在这里, 一行语句的末尾要加 ; 十分重要
}
变量
变量, 即变化的量, 与之对应的是常量. 变量可以理解成代码中的一个小盒子, 它里面存储的是用于计算相关的各种数据, 我们可以用唯一的一个名字来命名这个变量, 名字可以是数字,大小写字母以及_(下划线), 记住这个名字是唯一的, 不可以与任何东西重复, 我们需要通过这个名字来找到盒子里存储的内容.
变量的声明和赋值
我们的一个变量只有在声明之后才存在, 我们可以查找它的值, 可以给他赋值.
声明即是我们告诉计算机这个盒子的名字, 以及这个盒子是用来装什么类型的东西, 而赋值则是我们把一个内容装到盒子里.
在声明的同时进行赋值的操作叫做初始化.
变量的数据类型
值得注意的是, 计算机里的内容与我们的现实生活大不相同, 计算机里可以存贮的只有0和1, 我们这个盒子里亦然.
我们牛逼的前辈们提出了一种规则来利用许许多多的0和1表示我们需要的数字. 这套规则即是变量的数据类型, 它告诉了计算机应当怎样读取盒子里的内容, 又该怎样呈现给我们.
int & long & longlong
整型, 即用于存贮整数, int和另外两个的区别在于占用的空间不同, 也就是这个盒子的大小不同, 那他能装的整数的范围也就不一样.
int 可以存储的整数范围是 -2147483648 ~ 2147483647
int a=10;
int b=-23;
long c=2147483648;
long long d=214748364821474836;
**自行了解原码, 反码, 补码以及负数如何在计算机内存储 ***
float & double
浮点型, 用于存储小数, 他俩的区别同上.
float a=1.334;
double b=3.1415926535897932f;
**存储方式很独特, 有兴趣的可以自行了解. 附: 很有趣且很体现数学之美的应用 ***
bool
布尔类型, 用来表示对或错, 它只有True和False两种值, 但是可以通过强制类型转换转换成其他的类型, 只需记住 0代表 False, 其他值代表 True
bool a=true;
bool b=false;
char
字符类型, 用来存储单个字符. 注意, 需要表示的字符用 ' ' 括起来. 基础的char可以表示的字符可以找ASCII码.
char a='a';
char b='c';
char c='?';
struct
结构体, 我们可以自定义其中存储的东西, 先进行了解, 之后详细展开.
struct MY_STRUCT
{
int a;
float b;
bool c;
char d;
}; //特别注意这个 ;
struct MY_STRUCT myS=(MY_STRUCT){1, 1.2, true, 'b'}; // 声明也有一些不一样
数组
数组好比是我们把一串盒子按顺序的摆放了起来, 我们可以通过这个数组的名字和一个下标来找到我们想要的盒子, 然后查看盒子里的内容.
以上的所有数据类型都可以形成数组.
注意数组的下表是从 0 开始的, 如果一个数组有 n 个元素, 那么下标是 0 ~ n-1
int a[10];
a[0]=1;
a[3]=31;
a[10]=34; // 这是错误的
int b[4]={1,2};
int c[5]={0,};
int d[]={1,2,3,4};
字符串
其实字符串有两种形式, 一种是char类型的数组, 一种是C++相比于C独有的内容即string, 我这里简单提一下, 有对char[]感兴趣的可以自己尝试.
值得注意的是, 虽然用法基本上一样, 但是请不要把string当成一个普通的char[], 他是c++用类完全封装的一个东西.
也请不要尝试直接cin>>其他数组, 只有字符串有这个"特权".
string a="hello world";
cout<<a<<endl;
cout<<a[1]<<endl;
char b[]="hello world";
cout<<b<<endl;
cout<<b[1]<<endl;
变量运算
整形和浮点型的运算显然的包括普通的加减乘除, 但是要注意一点, \((int)1\div (int)2=(int)0\) 即: 在纯整形的除法里, 除法默认取整, 如果想要获取一个实数的结果需要这样$ (double) a\div b$或者 \(1.0*a\div b\)
还有一个很方便的功能, 我们可以用, a+=10 来代替 a=a+10, 这个也可以用在加减乘除取模
++--
一个变量++即是自加一, 同时它可以搭配在运算的位置形成复杂的语法方便我们代码的编写, 这个运算只能用于整形.
int a=10;
a++; cout<<a<<endl;
++a; cout<<a<<endl;
a--; cout<<a<<endl;
--a; cout<<a<<endl;
cout<<"before"<<a++<<" "; cout<<"after"<<a<<endl;
cout<<"before"<<++a<<" "; cout<<"after"<<a<<endl;
由上面的案例可以发现, ++a表示, 在我们打开盒子, 还没取到a的值时给a+1, 而a++则是, 在取到a的值了之后, 关上盒子的同时给a+1, -- 也是同样的道理.
位运算 *
位运算是对二进制的整数进行的运算. 请在了解了二进制以及整型变量存储之后, 自行学习这部分内容(建议去百度)
与(and) : &
0&n=0 1&1=1
或(or) : |
1|n=1 0|0=0
异或(xor) : ^
1^1=0^0=0 1^0=0^1=1
所以记住某一个数的多少次方并不是用 ^
取反(not) : !
!1=0 !0=1
然后以上运算都有对于每一位分别运算的按位与, 按位或... 运算, 其实那个符号是按位运算的符号
左移&右移
101<<3=101000 10100>>1=1010
变量修饰词
我们的变量在数据类型之外也可以有其他标识, 来达成需要的功能.
const
我们想要一个变量在声明并初始化之后不被修改, 比如 double pi=3.14于是有了 const 修饰符, 他告诉计算机后续任何对这个变量的修改都是不合法的操作.
const double pi=3.14;
pi=3.15; // illegal
输入输出
光有变量可不行, 我们还需要有对变量读取写入的操作
double a; int b; char c;
cin>>a>>b>>c;
cout<<"this is a:"<<a<<endl;
cout<<"this is b:"<<b<<'\n';
cout<<"this is c:"<<c<<endl;
打开文件 *
要读取或者写入一个文件, 需要用到打开文件, 然后对文件进行读写, 这部分由于并不是很重要, 所以请各位自行了解.
相对路径&绝对路径
对于一个系统中的文件, 有一个路径来找到它的位置, 可以分为相对路径和绝对路径, 绝对路径即在我们在任何位置都可以使用的一个绝对的路径表示, 但是一个问题在于它很长也不安全, 如果我们只想操作附近的文件我们可以用相对路径.
关键词
C++有很多用于标识语句的关键词, 这些关键词是不能用于命名变量, 函数的, 也就是说这些关键词都是有特殊含义的, 不能瞎用.
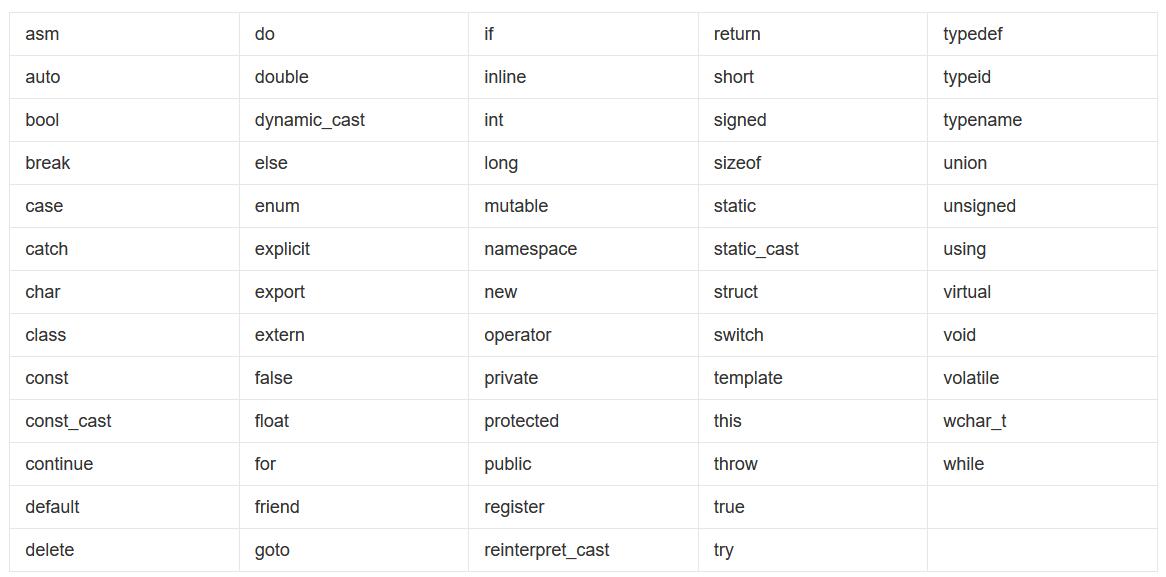
顺序语句
目前我们的代码已经有了变量和变量的输入输出, 在程序的主体部分顺序执行我们的代码已经初步有了不错的成效, 但它目前也只能当一个十分简陋的计算器. 如果想要更强大的功能, 需要引入更为强力的语句.
顺序语句即用来控制执行顺序的语句.
if else
int a;
cout<<"朋友, 快输入一个数字, 让我来判断一下它的大小"<<endl;
cin>>a;
if( a>5 /*条件*/ )
{
// 如果条件为 真 则执行这里的语句
cout<<"哦, 我的老朋友啊, 你给的这个值它一定大于5"<<endl;
}
else
{
// 如果条件为 假 则执行这里的语句
cout<<"哦, 我的上帝啊, 我保证这个变量不大于5, 如果我说了谎就请让隔壁的老马丁用它的臭鞋来踢我的屁股"<<endl;
}
用于判断的条件可以是一个bool类型的变量(真/假), 或者是一个条件表达式
a>5 a==5 a<5 a>=5 a<=5 a!=5 // 这是一个普通的表达式
// 我们可以用一些条件的运算来组合普通的表达式
!(a==5) (0<a)&&(a<5) (a<5)||(a==6) ( !(a==5) )&&(a==5)
跟在if后面的else是可以不写的, 也可以换成 else if 进行连续判断
if(blabla)
{
sinpi=114514;
}
if(your_score>=90)
{
your_mom_will_say="good!";
}else if(your_score>=80)
{
your_mom_will_say="not bad!";
}else if(your_score>=70)
{
your_mom_will_say="what's wrong with you?";
}else if(your_score>=60)
{
your_mom_will_say="you'd better not have a next time";
}else
{
cout<<"Good Game"<<endl;
}
循环
循环正如其名, 如果在一个判断条件为真的时候, 反复的去执行一段命令.
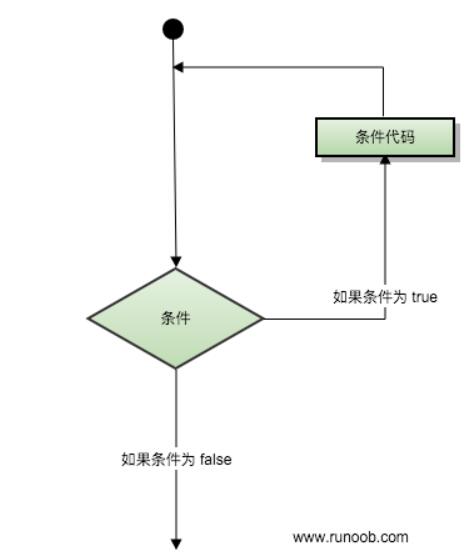
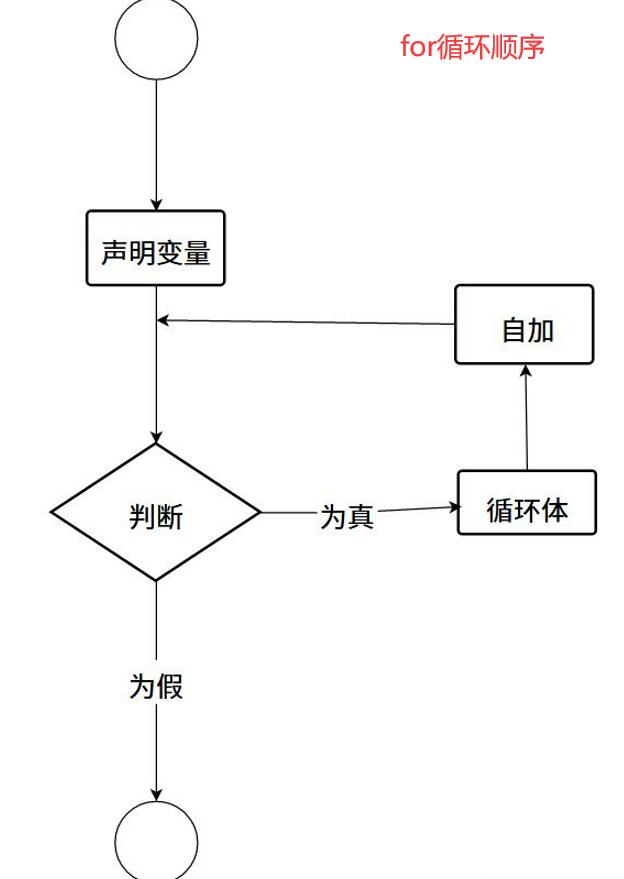
循环又有三种写法
for(int i=1; i<=10; i++)
{
cout<<i<<endl;
}
int i=0;
while(i<=10)
{
cout<<i<<endl;
i++;
}
int i=0;
do
{
cout<<i<<endl;
i++;
}while(i<=10)
实例: 九九乘法表
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
for(int i=1;i<=9;i++)
{
for(int j=1;j<=i;j++)
{
cout<<j<<"x"<<i<<"="<<setw(2)<<i*j<<" ";
}
cout<<endl;
}
return 0;
}
break&continue
在有了循环之后, 仍然有一些不足, 就好像我们在有一辆能跑的火车之后, 自然想要能让它随时的停下和变道.
break即是, 在执行到break; 语句的时候将当前最内层的循环中断
for(double hard_k=1.0;hard_k<=10;hard_k+=2)
{
double average_score=100-90/(12-hard_k);
cout<<"hard k="<<hard_k<<" aver_score="<<average_score<<endl;
for(int play_time=0;play_time<=24;play_time+=2)
{
double your_score=average_score-70/(10-play_time);
cout<<"play_time everyday: "<<play_time<<" your_score: "<<your_score<<endl;
if(your_score<=80)
{
cout<<"your mother will kill you"<<endl;
break;
}
}
}
而continue则是, 在执行到continue; 语句的时候, 跳过continue后面的语句, 直接开始最内层循环的下一轮.
for(int week_day=1;week_day<=7;week_day++)
{
cout<<'\n';
cout<<week_day<<endl;
cout<<"do homework"<<endl;
if(week_day<=5)
{
continue;
}
cout<<"surely play time"<<endl;
}
代码块 & 作用域 & 生命周期
在看了这些代码之后, 可能有细心的人已经发现一件事情了, 我们的代码里有很多的{ }, 其实一对大括号括住的结构叫做一个代码块.
在整个代码中, 由代码块形成的结构好比是套箱子, 首先有一个超大的箱子包裹在外面, 里面的第一层箱子是函数, 函数里面是各种循环判断之类. 我们在外层箱子声明的变量可以在同层以及内层使用, 但是不能在其外使用, 这个可以使用的范围即是作用域.
同时在这个箱子运行结束的时候, 这个箱子里声明的所有变量, 都会随之消失, 物理意义上的消失, 他会把占用的内存释放. 这既是变量的生命周期, 在被声明的时候诞生, 一般来说在作用域结束的时候消逝.
int a=10;
{
int b=10;
cout<<a<<" "<<b<<endl;
}
cout<<a<<" "<<b<<endl;
然后如果我们在一个内层的箱子声明了一个外层箱子已经存在的变量, 那么内层的变量会在它自己的作用域内顶替掉外层的那个, 但是十分不建议这么用, 能命名不一样的变量就不一样.
int a=10;
{
int a=20;
cout<<a<<" "<<endl;
}
cout<<a<<" "<<endl;
一定不要这么用, 在这里说这个语法只是帮助你们去debug. 请一定管理好自己声明的变量 !
static 关键字
static 是变量的另一个修饰词, (直到目前为止我们已经接触到两个修饰词了) , static修饰过的变量, 会在声明之后一直存在, 他的生命周期被延长了, 但是注意他的作用域并没有被延伸, 这个主要用于后面的函数内声明的变量. 有兴趣的可以之后自行尝试.
2. 函数
我们在高中已经学过函数的定义了, 他是从定义域到值域的一个映射. 而在编程里, 函数的定义和高中的并没有很大的区别, 从函数外面看, 它就像一个处理数据的黑盒, 通过输入一些数据, 经过计算, 返回输出. 值得注意的是, 这里的函数的内部处理方式是不限的.

特别的是, 函数的输入可以是任何支持的数据, 可以是一个int, 一个字符串, 甚至另一个函数, 然后输出亦然如此, 但是输出只能有一个"物体", 一个简单的函数是如下的样子.
prefix return_type function( parameter list /* 提供的参数 */)
{
// do something here
return return_type_value;
}
//在这里调用
blabla = function(parameter list);
- prefix 是对一个函数的修饰, 可以有很多也可以没有,
目前能用到的好像只有inline - return_type 是函数的返回类型, 可以是任何已有的类型, 也可以为
void, 即无返回 - parameter list 为输入的参数列表, 里面的每一个参数可以是任何已有的类型, 也同样可以没有输入
注意, return即是一个函数的结束, 一个函数如果执行了return指令, 那么无论return后面有什么语句都将被忽视, 就像是相对于函数的break, 以及有类似功能的是exit() , 他是一个程序的结尾, 程序在执行它后将立即终止.
函数的声明与定义
函数的声明即是向计算机说, 我有这样的一个函数, 函数在声明之后就可以被调用了, 在一个函数的声明之中, 应当包括函数的前缀修饰, 返回类型, 函数名和参数类型, 即需要包括上面代码里第一行中的所有东西, 但是参数的具体变量名称可以不加.
函数的定义就是向计算机说, 我的这个函数是长这个样子, 你应当这么去运行这个函数, 函数的定义需要包括上面代码的所有. 如果在函数定义时该函数没有被声明, 他将一同声明该函数.
int square(int x) // 声明+定义
{
return x*x;
}
int x=3, x2=square(x); // 调用
int pow_4(int); // 声明
int x4=pow_4(x); // 调用
int pow_4(int x) // 定义
{
return square(x)*square(x);
}
还有可以发现, 函数都是在最外层的代码块声明+定义的, 虽然有在main内声明的语法, 但是我建议只用这一种方式, 以及强烈推荐把声明和定义分开.
main的实质
细心的聪明脑袋瓜子可能会发现了, 我们的main长得和普通函数一模一样, 会不会有什么暗中的联系呢?
对的, main函数其实和任何普通函数一样, 任何函数有的它都有, 只不过C++钦定了长得和main函数一样的函数为一个可执行程序的入口, 任何的指令都从main函数被调用开始执行 .
函数的递归
其实递归并没有很多可以说的, 请不要把它当作一个很神秘的语法, 它仅仅是实现了一个函数该实现功能. 但是请给予它应有的重视. 它依然是一个非常优秀的编程思维.
递归是指我们可以在一个函数里面调用他自己, 从逻辑上使用这个函数产生的结果, 这样嵌套的进行.
一个例子是, 计算阶乘. 众所周知阶乘的定义: $$ n! = 1 \times 2 \times 3 \times ... \times n $$ , 进而有 $$n! = 1 \times 2 \times 3 \times ... \times n = (1 \times 2 \times 3 \times ... \times (n-1)) \times n = (n-1)! \times n$$ , 所以我们可以定义一个函数 f(n)来计算n!, 其中调用f(n-1)来计算(n-1)!
int f(int n)
{
if(n==1) return 1;
else return n * f(n-1);
}
只不过注意一下: 在里面那个被调用的他自己也有可能再次递归, 因此对 "一个有可能进行递归操作的函数" 来说最重要的是递归的终止条件. 还比如求最大公约数函数, 我们从数学公式了解到 a和b 的最大公约数等于 a%b和b 的最大公约数, 因此我们可以通过两个数字互相间反复取模来快速求得 gcd(a,b) .
int gcd(int a,int b)
{
if(b==0) return a;
else return gcd(b,a%b);
}
谨记, 只要我们在逻辑层面完成了这个函数, 就无需担心这个函数实际递归下去是什么样子.
如果还是很难理解, 我们可以从递归的底层来窥探这个高级的语法.
其实, 在调用函数时, 计算机找到这个函数所包含的指令, 把它需要的参数填入调用时的数值, 然后把这些指令复制一份到内存, 开始执行这个函数.
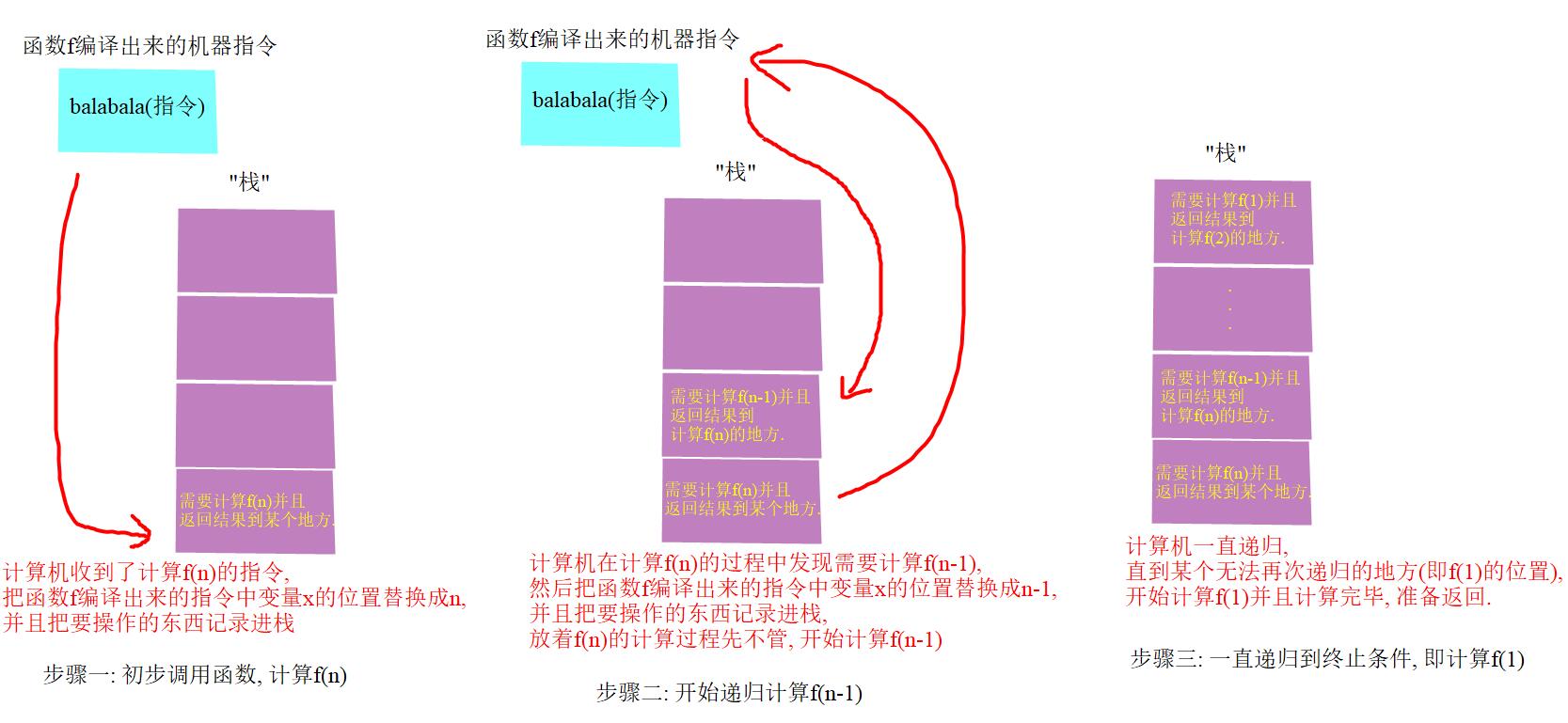
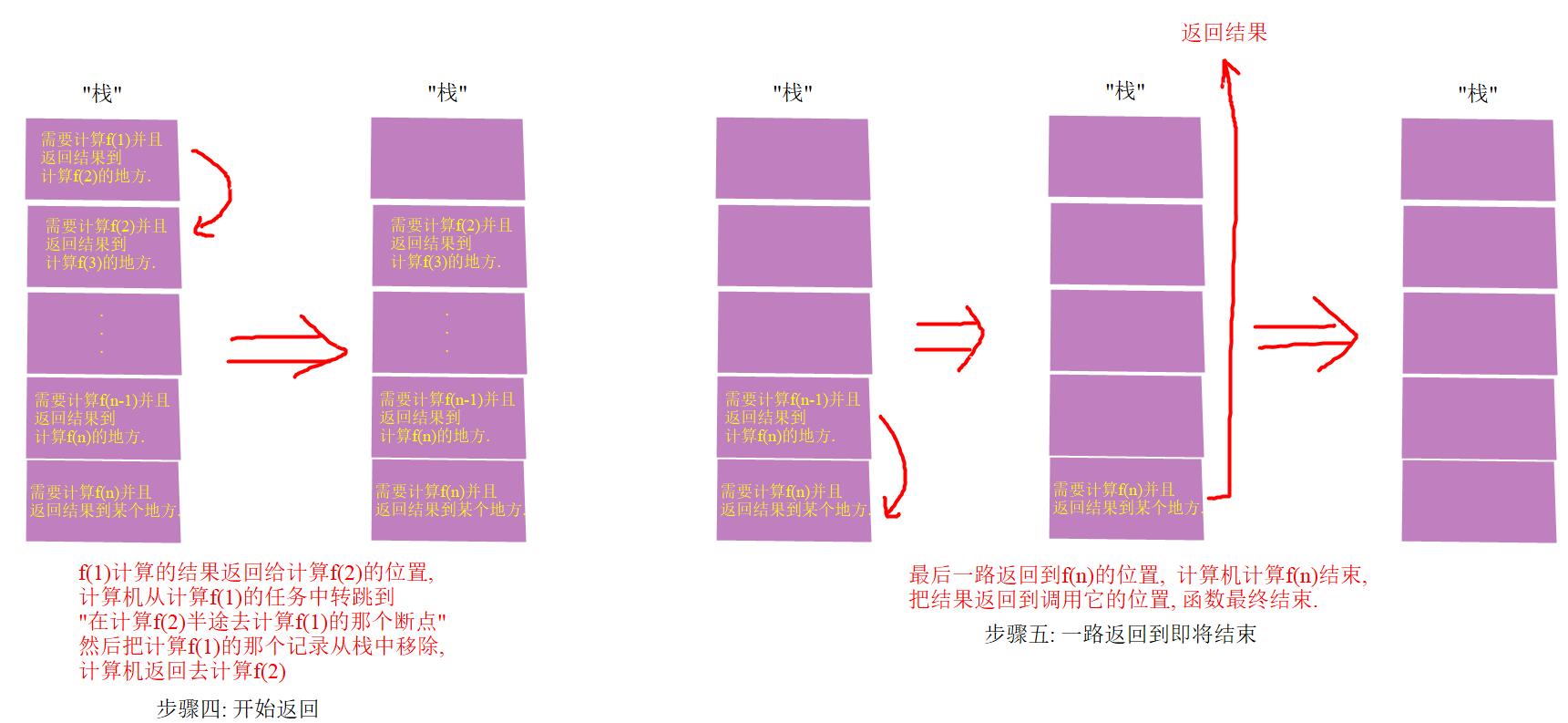
* 汉诺塔(可选)
一个经典的递归练习题目
函数的传参
C++对于传递参数的设计其实是很完美细致的, 但是不了解的确实会被坑.
对于一个传进去的参数, 他只会把这个参数所对应的值传进去, 而不传这个参数本身
#include <iostream>
using namespace std;
void test(int x,int y)
{
cout<<"x="<<x<<" y="<<y<<endl;
x=114, y=514;
cout<<"x="<<x<<" y="<<y<<endl;
}
int main()
{
int a=1,b=2;
cout<<"a="<<a<<" b="<<b<<endl;
test(a,b);
cout<<"a="<<a<<" b="<<b<<endl;
}
这是有好处的, 他隔绝了我们计算函数与实际数据使用的过程, 方便了编程. 这种传递参数方式叫做传递形参. 而在实际编程中我们也有传递这个参数本身的需要, 我们称为传递实参, 这可以通过以下两种方式解决.
地址和指针
这其实应该在变量后面讲的, 但是考虑到这个东西其实很难理解, 而且一般经常用于传参, 在这里讲会更方便理解.
在C++中的所有变量, 函数都有自己的地址, 这是在内存上的物理地址, 是直接给系统用的, C++为了更加细致入微地调用资源, 也给予了我们直接操作物理地址的能力, 对于一个变量我们可以通过 int object; int *pos=&object;来获取它的地址, 然后再对地址 *pos=114;来操作对应地址上的内容, 这个pos我们称为指针.
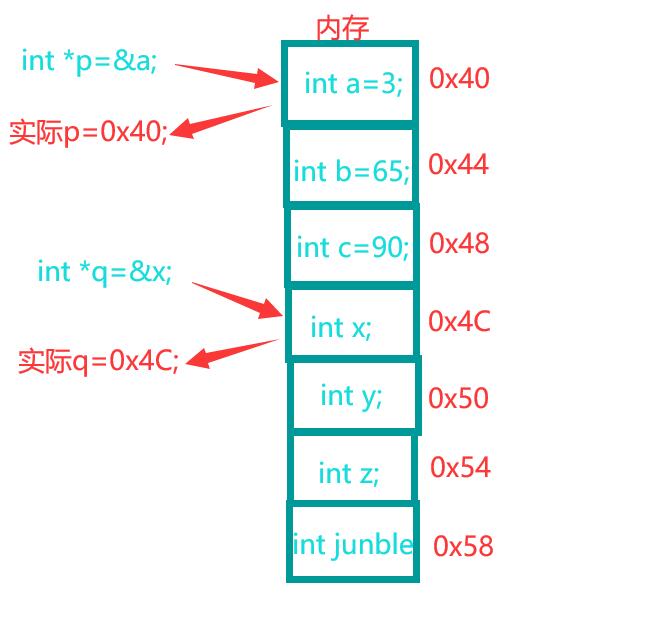
这一点我们可以用于传实参. 然后, 其实, 光一个函数名也是一个地址, 这点有兴趣的可以自行了解.
int a=10; int *pa=&a;
cout<<"a="<<a<<endl<<"&a="<<pa<<endl;
*pa=114514;
cout<<a<<endl;
int b=11;
scanf("%d",&b);
printf("%d\n",b); // 是新的输入输出方式
地址显然可以有更多的用处, 比如, 一个数组其实也是地址
#include <iostream>
using namespace std;
int main()
{
int a[100];
cout<<a<<endl;
a[10]=114;
cout<<a+10<<" "<<*(a+10)<<endl;
// 细节, 可以看一眼a+10的具体数值
}
其实指针我们可以理解为一个遥控器, 有他就可以通过摁按钮(*pos) 来获取实际的内容, 我们当然也可以获取这个指针的地址, 进行嵌套(虽然一般没用)
#include <iostream>
using namespace std;
void test(int *x,int *y)
{
cout<<"&x="<<x<<" &y="<<y<<endl;
*x=114, *y=514;
cout<<"x="<<*x<<" y="<<*y<<endl;
}
int main()
{
int a=1,b=2;
cout<<"a="<<a<<" b="<<b<<endl;
test(&a,&b);
cout<<"a="<<a<<" b="<<b<<endl;
}
引用
我们可以发现其实指针的功能很强大但是在大量地使用时很不方便, 于是c++加入了引用这个方便的东西.
int a=10;
int &b=a;
printf("%d %d\n",a,b);
b=14;
printf("%d %d\n",a,b);
引用同样相当于制造一个对象的遥控器, 它可以更加直接的方便的操作被遥控的对象 .
#include <iostream>
using namespace std;
void test(int &x,int &y)
{
cout<<"x="<<x<<" y="<<y<<endl;
x=114, y=514;
cout<<"x="<<x<<" y="<<y<<endl;
}
int main()
{
int a=1,b=2;
cout<<"a="<<a<<" b="<<b<<endl;
test(a,b);
cout<<"a="<<a<<" b="<<b<<endl;
}
命名空间
一个人的能力终究是有限的, 再怎么全能的人也不可能一天打出十万行的代码, 想要完成大型项目我们需要有多人协作的能力, 但是多人协作又不能单纯的把各个人的代码简单的拼接在一起, 那样的话可能小美声明了一个int target, 大美也声明了一个int target, 会引起变量的冲突, 当然我们可以在变量名前加上各自的名字 所以我们为了防止各种冲突出现, 也为了代码的美观与可读性, 提出了命名空间的概念.
我们可以用namespace来包裹一个代码块, 在其中声明的任何东西只能被命名空间内部的东西直接访问, 如果在命名空间外部想访问内部的东西, 需要连带着命名空间一起, 比如std::cin, 或者在某个代码块里声明使用该命名空间using namespace xxx;(注意这样的话命名空间对这部分代码块相当于没有), 不同的命名空间内的变量即便是完全相同也不会冲突.
#include <iostream>
#include <cstdio>
namespace LittleMei
{
int a=10;
double b=1.3;
void show()
{
std::cout<<a<<" "<<b<<endl;
}
}
namespace LargeMei
{
int a=11;
double b=3.1;
void show()
{
std::cout<<a<<" "<<b<<endl;
}
}
int main()
{
std::cout <<LittleMei::a <<LargeMei::a <<std::endl;
using namespace LittleMei;
std::cin>>a>>b;
show();
return 0;
}
可以发现, 冥冥之中有一个叫做std 的命名空间, 在里面的是cin和cout, 我们之前一直在写的using namespace std;即是如此, 马上就能介绍到了.
函数重载与模板
重载
前面我们提到过结构体struct, 我们把它当作一个普通的数据类型来讲解了, 但是各位在实际尝试的时候可能会有这样的问题 : 定义了一个复数结构体, 我们想要去做到让两个复数进行普通的运算, 比如加减乘除, 但是在运行编译的时候会出现error, 这其实是因为尚未定义实际的运算过程. 我们要怎么定义一个 " + " 函数呢, 这就提到函数重载.
函数重载其实严格来说, 是指C++允许在同一范围中声明几个功能类似的同名函数,但是这些同名函数的形式参数(指参数的个数、类型或者顺序)必须不同,也就是说用同一个函数完成不同的功能, 就比如我们已经有" + "这样一个运算, 但是这样的运算( 其实是函数 )并未定义如何去运算我们自己定义的struct, 我们如果想做到给自定义的复数结构体做加减法, 需要自己去定义如何运算.
struct MC
{
double x,y;
MC operator + (const MC & rhs) const;
MC operator - (const MC & rhs) const;
friend ostream& operator << (ostream &out,const MC & a)
{
out<<"("<<a.x<<", "<<a.y<<")";
return out;
}
friend istream& operator >> (istream &in,MC & a)
{
in>>a.x>>a.y;
return in;
}
};
MC MC::operator+(const MC & rhs) const
{
return (MC){this->x+rhs.x,this->y+rhs.y};
}
MC MC::operator-(const MC & rhs) const
{
return (MC){this->x-rhs.x,this->y-rhs.y};
}
函数重载也可以用于struct以外的地方.
int square(int x)
{
return x*x;
}
double square(double x)
{
return x*x;
}
float square(float x)
{
return x*x;
}
这样就可以方便的让同一个函数发挥出更大的功能.
模板
但是这样可能会有一个问题, 我们总不能有一个数据类型就写一个函数吧, 如果这个函数还是用于输出的, 那我们可能就真的是有一个数据类型就写一个函数了, 为了避免这样的事情发生, C++又提供了一个方便的功能. 模板
template<class T>
T square(T x)
{
return x*x;
}
我们可以通过模板来大大提高代码的复用性, 你甚至可以这样:
struct MC
{
double x,y;
// MC operator + (const MC & rhs) ;
// MC operator - (const MC & rhs) ;
MC operator * (const MC & rhs)
// 如果想在这里写一个复数和实数的乘法, 可能需要"限制模板泛化的类型", 有兴趣的可以自己了解
{
return (MC) { this->x*rhs.x-this->y*rhs.y, this->x*rhs.y+this->y*rhs.x};
}
friend ostream& operator << (ostream &out,const MC & a)
{
out<<"("<<a.x<<", "<<a.y<<")";
return out;
}
friend istream& operator >> (istream &in,MC & a)
{
in>>a.x>>a.y;
return in;
}
};
template<class T> T square(T x)
{
return x*x;
}
函数模板其实是编译器在每一个调用这个函数的地方进行了 "类型推断" , 然后现场生成了一个对应的函数, 然后再去调用这个新的函数, 这通常发生在代码的编译阶段. 而C++11之后好像就不是这样了(
还有一件事情是值得注意的, template并不是完全的等于传入的参数, 他是首先进行了类型推断, 然后用推断出来的类型生成一个函数, 至于这个推断的类型具体是什么, 他是怎么推断的, 这部分内容可以去看《Effective Modern C++》
库&STL
前面提到了, 我们提出了命名空间来辅助我们合并代码, 但是我们总不能各个人写完代码之后复制粘贴到一份文件里吧, 所以我们可以在多个文件里编写代码, 用文件的结构表示代码的大致结构, 然后通过调用库的方式引入其他的代码.
这里我们又可以解释一个东西了, 我们之前一直要写的#include <iostream> 即是C++的输入输出库, <cstdio> 即是C++中继承自C的输入输出库, <iomanip>即是输入输出的控制库, 我们的setw(int x)来控制输出场宽即是在这个库里面.
STL
而在C++的历史中, 曾有一群十分厉害的大佬, 他们合作编写了一些优秀的常用工具, 汇聚在了标准模板库STL (Standard Template Library) 里, 看名字就可以知道, 这是一个汇聚了很多常用工具模板的库, 可以说用C++而不用STL就少了90%的灵魂.
上文提到的using namespace std;即是C++标准库和STL所使用的命名空间, 每次我们加上std命名空间就可以在调用C++标准库和STL的时候少些一些std::xxx(但是在工程代码里建议使用后者的方式)
vector
包含在头文件<vector>中, 提供了一个可变大小的数组.
set
包含在头文件<set>, 在放进去变量的时候自动排序并且剔除重复的变量
stack
栈, 基本用不到(
map
包含在头文件<map>中, 映射, 如果要说的话, 这个更像是自定义数组
sort !!!
排序!!! 是很快很快的排序 包含在<algorithm>里
Debug的第『零』步
在这之前请各位找出这个代码里的bug
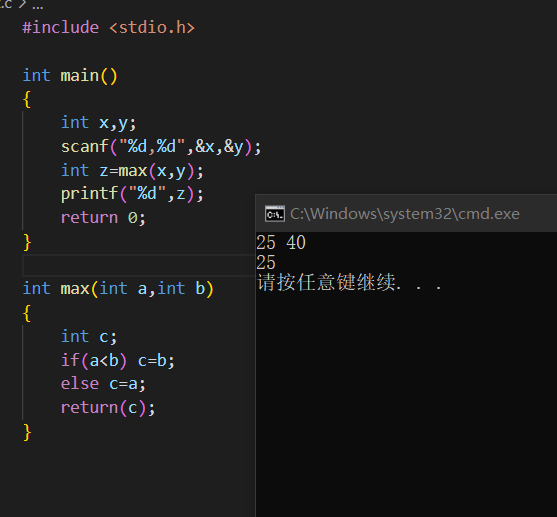
我们可以通过输出一些节点的内容来探清到底发生了什么(当然可以用调试模式来做到同样的事情)
#include <stdio.h>
int main()
{
int x,y;
printf("before hitting x=%d y=%d\n",x,y);
scanf("%d,%d",&x,&y);
int z=max(x,y);
printf("x=%d y=%d z=%d",x,y,z);
return 0;
}
int max(int a,int b)
{
int c;
if(a<b) c=b;
else c=a;
return(c);
}
当然这只是一个比较简单的案例, 这个案例告诉了各位在使用scanf的时候一定要慎重, (当然在正常使用的情况下一般不会出现问题).
在第一篇基础C++的结尾提到这个事情是为了让各位在debug的时候不要眼高手低, 很多bug是在我们很难用血轮眼瞪出来的, 如果出现了难以理解的bug就请上手调试, 一步一步了解程序的运行吧.
Undefined Behavior
在上述内容之后,再来了解另一件事情,即未定义行为(Undefined Behavior). 各位尝试去思考一下为什么我们可以称C++为一门[语言](语言其实是我们创造出来的, 大家所公认的一种规则, 它的生命依赖于使用它的人们, 因而C++其实可以算作一门语言, 只不过它有一个独特的听众: 编译器. 进而我们可以引出: 我们学习的C++其实是一种规则, 一种语言的规则, 而既然是种规则他就有漏洞). 未定义行为即并没有被写入规则的行为, 他就是漏洞.
#include <cstdio>
#include <iostream>
using namespace std;
int * createptr()
{
int x=2;
return &x;
}
int main()
{
cout<<*createptr()<<endl;
cout<<"here"<<endl;
return 0;
}
这就是一个典型的在生命周期之外的地方调用局部变量, 会产生悬置指针(很危险!)
3. 面向对象
以下的内容就不强求在短时间内掌握了, 但是对于编程能力的提高是很重要的, 如果有想法的话可以自行深入了解.
C++相较于C最明显的特征就是"更简单地"支持了面向对象编程. 面向对象编程是一种编程的想法, 它是指, 我们在实现某个功能的时候, 不再去考虑每个步骤或者每个细节是如何完成的, 而是在概念上创造一个对象, 赋予对象各种属性和行为, 最后相互组合完成一些复杂的功能.
比如, 如果我们要写一个贪吃蛇程序.
这可能对各位来说还是一个很大的工程, 去考虑全部的细节目前来说还是很难的一件事情. 于是 , 我们去拆分功能, 创造对象, 然后组合.
-
首先我们需要一条蛇, 这条蛇负责管理它自己的前进, 吃没吃到苹果, 以及更新状态, 而不需要考虑怎么把它画出来. 我们相当于定义一个struct , 它里面有几个成员函数:
moveForward(), eatApple(), update()之类的, 其余与游戏相关的内容可以交给其他对象去实现. -
然后是响应我们(玩家)的操作, 这个专门用一个
监听者对象来监测键盘的指令, 然后进行解释指令, 把需要的命令发送到蛇那里去. 我们定义一个struct, 然后它的成员函数是:keepListening(), translateAndCall() -
然后需要一个画布对象, 在这个画布上我们接收来自蛇的位置信息, 然后把这条蛇画出来, 再接收一个苹果的位置信息来画苹果, 最后把画布呈现在我们的黑框框里面. 那他的成员函数:
receiveSnake(Snake thisSnake), receiveApple(Apple appleList), update() -
最后就需要进行整个游戏的进行了, 我们有如下的伪代码:
Snake thisSnake; Apple appleList; Canvas canvas; while(GameRunning) { thisSnake.moveForward(); thisSnake.eatApple(appleList); thisSnake.update(); appleList.generateApple(); canvas.receiveSnake(thisSnake); canvas.receiveApple(appleList); canvas.update(); }
Class: a better choice
终于轮到我们面向对象的主角: class 了. 从结果来说, class其实是对struct的全方位升级, c++中对struct的实现好像是用class, 接下来我们细致的介绍一下类.
属性
这个其实是我自己对类的理解, 其沿用了Python的定义: 类中的所有东西, 无论是变量还是函数, 我们都可以用『这个类的属性』来称呼, 就好像这个类就是一个生动的实体, 它具有一些『属性』, 这些『属性』——无论是它是一种数值还是一种方法(函数), 都是我们用来刻画这个抽象的对象的方式.
以及给出如下定义:
- 对象/类 : 指我们的
class DemoClass{};代码, 这样所大致刻画的一个对象/类 - 实例 : 我们可以把它当作一个
DemoClass类型的变量, 但我们更喜欢叫他「一个对象的实例」
就像每个人都会有自己的隐私, 我们都不希望自己的一些事情被别人知道, 类也有一些不希望被其他类知道的属性, 这些称为private属性, 其余的为public属性. public的属性可以被类的外部发现, 这意味着我们可以在类的外部访问这个对象的属性; 而private 的属性不允许从类的外部访问, 它只能被这个类中的函数访问.
以及就像每个人都会生老病死, 每个类固定的具有两个函数, 构造函数与析构函数, 这两个函数自然存在而无需我们定义声明, 但是我们可以自己重载他们 . 构造函数会在一个类的实例被生成的时候自动调用, 我们可以通过访问public的构造函数来对一个新的实例进行初始化, 而析构函数则是在一个实例的生命周期结束的时候被自动调用, 它用来告诉计算机如何销毁这个实例.
class DemoClass
{
public:
int age,gender;
int *p;
DemoClass(int a,int b,int c) :
age(a), gender(b) // use this to initialize things faster
{
cout<<"creating a object"<<endl;
p=new int(c);
}
~DemoClass() { delete p;cout<<"destroying a object"<<endl; }
friend ostream& operator << (ostream& out,const DemoClass & rhs)
{
out<<"("<<rhs.age<<", "<<rhs.gender<<", "<<*rhs.p<<")";
return out;
}
private:
int x,y,z;
};
int main()
{
DemoClass littleMing(1,2,3);
// littleMing.x=1; // this is illegal
cout<<littleMing<<endl;
}
继承
一个类可以通过「继承」来获得另一个类中的属性, 被继承的类称为基类或者父类, 继承过来的类称为派生类或者子类. 同时我们可以在继承的时候加上public/protect/private来指定获得的属性的访问权限. 「继承」的功能很好的支持了代码的复用, 以及我们可以通过类的继承来组织代码的结构, 就像是大楼中的钢筋骨架.
这里出现了一个新的词protect, 这个修饰其实和private差不多, 一个类中的属性经过protect修饰后就可以被自己和子类访问, 但不能被其他位置访问. 具体的访问权限如下:
| 访问 | public | protect | private |
|---|---|---|---|
| 同一个类 | √ | √ | √ |
| 派生类 | √ | √ | x |
| 外部的类 | √ | x | x |
| 同时一个类也可以继承自许多父类 |
#include <iostream>
using namespace std;
class Shape // 基类 Shape
{
public:
void setWidth(int w) { width = w; }
void setHeight(int h) { height = h; }
protected:
int width;
int height;
};
class PaintCost // 基类 PaintCost
{
public:
int getCost(int area) { return area * 70; }
};
class Rectangle: public Shape, public PaintCost // 派生类
{
public:
int getArea() { return (width * height); }
};
int main(void)
{
Rectangle Rect;
int area;
Rect.setWidth(5);
Rect.setHeight(7);
area = Rect.getArea();
// 输出对象的面积
cout << "Total area: " << Rect.getArea() << endl;
// 输出总花费
cout << "Total paint cost: $" << Rect.getCost(area) << endl;
return 0;
}
一个派生类继承了所有的基类方法,但下列情况除外:
-
基类的构造函数、析构函数和拷贝构造函数。
-
基类的重载运算符。
-
基类的友元函数。
友元函数
这部分直接看菜鸟教程好了, 讲的很清楚
拷贝构造函数
拷贝构造函数, 可能看名字就大概了解了, 他是一种构造函数, 但是他是通过获取另一个实例来初始化另一个实例, 在我们做如下操作的时候就会调用拷贝构造函数.
class DemoClass
{
public:
int getData( void );
DemoClass( int data ); // 简单的构造函数
DemoClass( const DemoClass &obj); // 拷贝构造函数
~DemoClass(); // 析构函数
private:
int *ptr;
}
DemoClass a;
// a=blablabla
DemoClass b(a);
DemoClass c=a; // 这两个都是调用了拷贝构造函数
DemoClass::DemoClass(int data)
{
cout<<"调用了构造函数"<<endl;
this->ptr = new int(data);
}
DemoClass::DemoClass(const DemoClass &obj)
{
cout<<"调用了「拷贝」构造函数"<<endl;
this->ptr = new int(*obj.ptr);
}
int DemoClass::getData()
{
return *ptr;
}
DemoClass::~DemoClass()
{
cout<<"调用了析构函数"<<endl;
delete this->ptr;
}
至于拷贝构造函数有什么用呢, 这就要牵扯到我们想要做什么事情了.
比如, 刚刚我们的这个类里面的指针指向的不是一个int而是一个int数组, 由于构造数组需要很大的开销, 我们希望这几个democlass的实例能够共享这个数组, 同时在没有实例使用这个数组的时候, 自动地删除.
#include <iostream>
#include <cstdio>
#include <vector>
using namespace std;
class MyPoolManager
{
private:
vector<int*> ptrs;
vector<int> size;
vector<int> refs;
public:
int getNewInstance(int len)
{
int * newArray = new int[len];
ptrs.emplace_back(newArray);
int idx = ptrs.size()-1;
size.emplace_back(len);
refs.emplace_back(1);
printf("creating pool with idx %d\n",idx);
return idx;
}
int getOldInstance(int idx)
{
refs[idx]++;
printf("copying pool with idx %d\n",idx);
return idx;
}
void deleteInstance(int idx)
{
printf("deleting pool with idx %d and refs=%d\n",idx,refs[idx]-1);
if(refs[idx]==0)
{
cout<<"deleting an instance that doesn't exit"<<endl;
exit(1);
}
refs[idx]--;
if(refs[idx]==0)
{
delete [] (ptrs[idx]);
ptrs[idx]=nullptr;
size[idx]=0;
printf("successfully free memory with idx %d\n",idx);
}
}
int * get(int idx)
{
if(refs[idx]==0)
{
cout<<"accessing an instance that doesn't exit"<<endl;
exit(2);
}
return ptrs[idx];
}
};
class DemoClass
{
public:
DemoClass(int len)
{
dataIdx = DemoClass::myPoolManager.getNewInstance(len);
dataSize = len;
}
DemoClass(const DemoClass & obj)
{
dataIdx = DemoClass::myPoolManager.getOldInstance(obj.dataIdx);
}
~DemoClass()
{
printf("deleting DemoClass with idx %d ...\n",dataIdx);
DemoClass::myPoolManager.deleteInstance(dataIdx);
}
private:
static MyPoolManager myPoolManager;
int dataIdx;
int dataSize;
};
MyPoolManager DemoClass::myPoolManager;
int main()
{
DemoClass a(10);
{
DemoClass b=a;
{
DemoClass c(b);
puts("here \n");
}
}
}
这里通过指针共享一个实例的功能会在后续学习到更简单的实现方式.
以及OpenCV里对图片对象 Mat 中实际的图片数组也是用这种方式实现内存管理的.
this指针
前面在拷贝构造函数中第一个DemoClass那里应该已经见过了, 在一个对象的成员函数中, 里面凭空出现了一个this指针, 这个this指针好像还指向的是我们调用这个函数的实例, 是不是哪里的语法没有介绍, this是个新东西吗???
其实是因为, 对象的成员函数和其他普通函数没有很大区别, 如果这个成员函数需要通过实例来调用, 那么他会隐含的传入一个this参数, this是指向调用这个函数的实例的指针, 如此来操作这个实例.
如果各位在日后有用到函数指针, 可能会需要对象中的某个函数, 甚至需要这么一个函数指针: 它的实体是某个成员函数, 但是它固定的操作某一个实例, 这就先挖一个坑好了, std::bind()各位总会有一天需要用到这个东西的.
静态成员
同样是, 前面的拷贝构造函数里也见过了, 在一个对象中可以有一个所有实例共同的属性, 可以是函数也可以是变量(但是变量的话需要在外部全局地声明出来, 否则就会出现undefined reference to报错) . 我们可以通过像访问命名空间一样去访问一个对象的静态成员.
注意: 虽然这个静态属性可以被任何实例共同访问, 但是它严格意义上说是隶属于这个对象的
多态
咕, 应该讲不到这里
也是看菜鸟教程吧
移动构造函数
又是一个构造函数, 但是它好像并没有被提及过, 还有为什么构造函数为什么要放在最后???
因为它并不是这部分的鸭, 他是C++11的.
4. Effective Modern C++
前面我们所讲述到的都只是98年制定的C++标准, C++98中的内容, 他支持了"C With Class"大部分内容, C++98的内容已经相当实用, 但是仍有很多值得改进的地方, 为了更加便捷的开发大型项目, 以及在细节之处进一步优化, 我们有了C++11 & C++14. (这部分的C++已经很难再说是一个简单的C的升级版了)
概括的说, Modern C++完善了类型推导, 增加了语法auto以及其衍生用法, 提出了智能指针, 完善了右值的相关语法并支持了完美转发, 支持了lambda语法, 提供了并发API.
在这里只做简单介绍一些用法, 具体的实现还请各位自行深入研究, 详见《Effective Modern C++》.其实是我也不会
auto
前面在函数模板的时候已经提到过了类型推断, 这是在c++98已经有的东西, 在c++11中, 万能的程序员们为了方便编程, 提出了给我们声明的变量进行类型推断的功能, 大大方便了编程但也增加了一些隐形bug的可能
int func(int x)
{
return x;
}
double func(double x)
{
return x*x;
}
auto a = func(1);
auto b = func(1.2);
注意, auto能且仅能用于声明一个变量并且需要在声明的同时进行初始化, 而且这个初始化的类型是可以被推断的.
但这也有隐性bug的可能, 因为有一些库中的函数实际返回的是其他类型的变量, 然后通过强制转换, 变成我们想要的类型, 比如这样:
#include <iostream>
#include <cstdio>
#include <cstdlib>
#include <cmath>
using namespace std;
class DemoClass
{
private:
double i,j;
public:
DemoClass(double ii,double jj): i(ii),j(jj) { }
operator int() { return sqrt(i*i+j*j); }
operator double() { return sqrt(i*i+j*j); }
operator pair<double,double>() { return make_pair(i,j); }
};
DemoClass getComplax(double i,double j)
{
return DemoClass(i,j);
}
int main()
{
double a = getComplax(1,2);
cout<<a<<endl;
int b = getComplax(2,3);
cout<<b<<endl;
auto len = getComplax(2,3); // compile error
cout<<len<<endl;
}
这里提供了一个复数向double和int的转换, 目的是方便运算, 但是直接用auto接收的话会出错, 所以auto建议使用在你明确知道会发生什么的地方.
auto也可以与for each配合使用
int a[]={1,2,3};
char ss[][6]={"1223","233","234"};
for(auto x:a) cout<<x<<endl;
for(auto str:ss) cout<<str<<endl;
decltype()
这真的是个好东西(, 它覆盖了auto无法触及到的需要类型推断的地区. decltype(val)来指代变量val的类型, 有如下的使用方式
auto varname = value;
decltype(exp) varname = value;
decltype(exp) varname;
exp可以为一个变量, 一个包含变量的表达式, 甚至是一个函数返回参与在内的表达式
可以发现decltype有明显的两个优势, varname可以直接设置成与它所等于的值无关的类型, 它避免了一些隐形的未知的类型转换导致auto推断出错, 以及它不需要被初始化
但是还有一个很重要的功能: 返回值后置
int& foo(int& i);
float foo(float& f);
template <typename T>
auto func(T& val) -> decltype(foo(val)) //在val作为参数出现之前是无法进入表达式的
// decltype(foo(val)) func(T& val) 即这是不合法的
{
return foo(val);
}
它与auto及模板相配合, 即可做到很大程度的函数自动判断类型返回
智能指针
各位在使用指针的时候想必有体会到指针的优点, 我们可以很好的区分开内存中的实例与我们可操作的实例, 但也会感觉到自行申请内存, 删除内存的麻烦, 于是我们有了「智能」指针(这个其实在其他高级面向对象语言里也有, 甚至更早出现).
所谓智能指针, 即在我们可以把它当作指针的同时, 它完成了对普通指针的封装并且实现了很多常用的功能.
unique_ptr
就运行效率来说, unique_ptr几乎和普通指针一模一样, 如果没有特殊需要可以把所有的普通指针用它来代替.
unique_ptr作为指针, 它所指向的实例唯一地被这个指针所有, 可以想象成一个遥控器唯一地匹配一个电视, 同时这个电视也唯一地被这个遥控器支配, 但是以上的前提都是我们完全使用unique_ptr而不是交叉使用它和普通指针.
他是通过禁用了unique_ptr的拷贝构造函数并且只能通过移动其他unique_ptr实例 或者 构造函数来获得.
并且在unique_ptr这个唯一指向实例的指针被销毁的时候, 同时销毁指向的实例. (也就是帮我们省事了)
class DemoClass
{
public:
DemoClass()
{
cout<<"构造函数"<<endl;
}
~DemoClass()
{
cout<<"析构函数"<<endl;
}
};
int main()
{
{
unique_ptr<DemoClass> a(new DemoClass());
}
}
以及unique_ptr对数组进行了重写, 可以方便地把它当作整个对象来使用.
#include<iostream>
#include <cstdio>
#include <memory>
using namespace std;
int * ar;
unique_ptr<int[]> create()
{
int n = 9;
int * array = new int[n];
ar = array;
for(int i=0;i<n;i++)
array[i] = i;
unique_ptr<int[]> ptr(array);
return ptr;
}
int main()
{
{
unique_ptr<int[]> ptr = create();
for(int i=0;i<9;i++)
cout<<ptr[i]<<" ";
}
cout<<endl;
for(int i=0;i<9;i++)
cout<<ar[i]<<" ";
}
shared_ptr
它的运行效率比上者稍低一些.
它即我们在拷贝构造函数一章所提及的方便的进行对内存的管理. 它与unique_ptr不同的是shared_ptr指向的实例可以被多个shared_ptr实例共享, 只有在所有shared_ptr实例都被销毁的时候, 他所指向的内容才会被销毁.
不过, 想要实现shared_ptr实际的效果, 需要全篇的使用shared_ptr, 如果有一处被转换成普通指针或者是unique_ptr, 那么将功亏一篑(
class DemoClass
{
public:
DemoClass()
{
cout<<"构造函数"<<endl;
}
~DemoClass()
{
cout<<"析构函数"<<endl;
}
};
int main()
{
{
shared_ptr<DemoClass> a(new DemoClass());
{
puts("is it in b?");
shared_ptr<DemoClass> b=a;
{
puts("is it in c?");
shared_ptr<DemoClass> c=b;
puts("out of c");
}
puts("out of b");
}
}
cout<<"complete"<<endl;
}
shared_ptr如果想指向一个数组的话, (因为他没有重写) . 只能自己实现一个deleter传入.
#include<iostream>
#include <cstdio>
#include <memory>
using namespace std;
int * ar;
shared_ptr<int> create()
{
int n = 9;
int * array = new int[n];
ar = array;
for(int i=0;i<n;i++)
array[i] = i;
auto Deleter=[](int *ptr){ delete[] ptr; };
shared_ptr<int> ptr(array,Deleter);
return ptr;
}
int main()
{
{
shared_ptr<int> ptr = create();
for(int i=0;i<9;i++)
cout<<ptr.get()[i]<<" ";
}
cout<<endl;
for(int i=0;i<9;i++)
cout<<ar[i]<<" ";
}
还有一些新的指针就请自行了解吧( 才不是因为我也不会
lambda
提到lambda那就不得不重新了解一下函数这个老朋友
函数指针
可能于各位所理解的有所区别, 函数其实也可以被看成我们所定义的变量, 我们可以通过一个函数指针来访问这个类似于对象的实例一样的东西.
#include <iostream>
#include <cstdio>
#include <map>
#include <vector>
#include <algorithm>
#include <memory>
using namespace std;
int func0(int x) { return 1; }
int func1(int x) { return x; }
int func2(int x) { return x*x; }
int func3(int x) { return x*x*x; }
int ((*funcs[10])(int)); //这是一个 很复杂的东西
int main()
{
funcs[0]=func0;
funcs[1]=func1;
funcs[2]=func2;
funcs[3]=func3;
for(int i=0;i<=3;i++)
{
cout<<(funcs[i])(i)<<endl;
}
}
由此我们可以大致感觉到, 这个函数其实和变量很像, 我们可以把它当作一个实例, 至于它的类型, 则是按照如下考虑:
- 我们需要用这个类型来判断函数应当接收什么样的参数, 并进行怎样的返回(c++中所有的类型推断都是在编译期间进行的, 在运行期间是没有类型推断发生的, 这与python这种解释语言就有很大不同)
- 那我们就需要我们的函数指针事先标识以上我们需要的东西, 即: 函数的参数和函数的返回值类型.
- 于是函数指针需要我们这么去定义
return_type (* func_name)(parameter list);
// * 这里就是在声明 func_name 是一个指针
int (* func)(int,double); int afunction(int x,double y);
void (* func1)(void); void bfunction();
int (* func2)(int(*)()); int cfunciton(int (*a)());
//没错我们在套娃
// 这里注意我们在指明参数列表的时候只需要且只能标明参数的类型
注意这和我们声明函数的时候还有所不同, 在我们声明函数的时候我们需要做如下考虑:
- 一个函数的所有前缀修饰(像函数的返回值, inline修饰符等) 均不能用于区分两个函数
- 可以区分开两个函数只能通过: 函数的名称, 和函数的参数列表, 并且如果函数存在缺省值, 判断条件就更加复杂
- 我们可以通过「如何调用这个函数」来判断两个函数是否可以进行区分.
int func1(int x,int y=1)
{
cout<<"int"<<endl;
return x+y;
}
double func1(int x,double y=1.0)
{
cout<<"double"<<endl;
return x;
}
int main()
{
cout<<func1(1); // ambiguous
}
或许各位已经有一点感觉了, 那就是函数指针实际上, 他好像就是这个函数本身, 它并不像我们的变量指针一样严格的区分出指针与实例, 函数指针和函数本身似乎就是一体的.
那我们把函数也变成一个实例又有什么用呢?
首先一点我们可以意识到, 我们在代码中所有接触到的东西都变成了对象, 而不再是单纯的一个个函数, 我们可以这么说: 我们的main函数是各个对象相互交互组成的, 他是个面向对象的代码! 这显然是有助于我们培养一个面向对象的思维. 『请把相关的功能组合在一个对象里』
其次, 我们可以把函数也作为参数传入其他函数, 或者把它赋值给某个实例的属性里. 前者我们可以通过这个设置回调函数, 后者我们可以让实例变得生动起来.
#include <iostream>
#include <cstdio>
#include <map>
#include <vector>
#include <algorithm>
#include <memory>
using namespace std;
void mouse_click(int x,int y,vector<void *(*)(int,int,void *)>_callbacks,vector<void*>inputs)
{
if(_callbacks.size()!=inputs.size()) { cout<<"blabla"<<endl; return ; }
int size = _callbacks.size();
for(int i=0;i<size;i++)
{
_callbacks[i](x,y,inputs[i]);
}
}
void * callback1(int x,int y,void * other_input)
{
string things = *(static_cast<string*>(other_input));
cout<<"clicked 1 ("<<x<<","<<y<<")"<<things<<endl;
}
void * callback2(int x,int y,void * other_input)
{
int things = *(static_cast<int*>(other_input));
cout<<"clicked 2 ("<<x<<","<<y<<")"<<things<<endl;
}
int main()
{
while(1)
{
int x,y; cin>>x>>y;
string a = "output1";
int b = 1;
mouse_click(x,y,{callback1,callback2},{static_cast<void *>(&a) , static_cast<void *>(&b)});
}
}
lambda函数
终于到我们的主角了 前面的代码虽然已经挺不错的了 (可以传入一些自定义的回调函数, 并且回调函数还可以有由用户确定的传入参数), 但是还是会有一些问题, 比如我们要有一连串的回调函数(比如几十个), 我们如果要把所有函数都确定一个名字(从0到114)那就太麻烦了, 而且很狼狈, 不优雅, 这些函数只用于回调, 我们能不能不去起名字?
而lambda就是我们的生成匿名函数的一大法宝.
我们可以把上面的代码改成这样.
void mouse_click(int x,int y,vector<void *(*)(int,int,void *)>_callbacks,vector<void*>inputs)
{
if(_callbacks.size()!=inputs.size()) { cout<<"blabla"<<endl; return ; }
int size = _callbacks.size();
for(int i=0;i<size;i++)
{
_callbacks[i](x,y,inputs[i]);
}
}
int main()
{
while(1)
{
int x,y; cin>>x>>y;
string a = "output1";
int b = 1;
mouse_click(x,y,
{
[](int x,int y,void *other_input) -> void *
{
string things = *(static_cast<string*>(other_input));
cout<<"clicked 1 ("<<x<<","<<y<<")"<<things<<endl;
},
[](int x,int y,void *other_input) -> void *
{
int things = *(static_cast<int*>(other_input));
cout<<"clicked 2 ("<<x<<","<<y<<")"<<things<<endl;
}
},
{static_cast<void *>(&a) , static_cast<void *>(&b)});
}
}
我们通过一些个魔法生成了很独特的东西 lambda现场生成了我们需要的函数然后传入, 显然我们的回调函数只会在这里被使用, 那我们直接在这里声明并且定义函数可以很好的提高了代码的可读性.
那我们再来介绍lambda的用法:
lambda 表达式定义了一个匿名函数,并且可以捕获一定范围内的变量。lambda 表达式的语法形式可简单归纳如下:
[ capture ] ( params ) opt -> ret { body; };
其中 capture 是捕获列表,params 是参数表,opt 是函数选项,ret 是返回值类型,body是函数体。
而params, ret, body在前面已经演示过了, 下面是关于capture的演示
int main()
{
int a = 1;
auto func = [a](int x,int y) -> void { printf("%d %d %d\n",a,x,y); };
while(1)
{
int x,y; cin>>x>>y;
func(x,y);
}
}
可以看到我们定义的存在于main函数内的局部变量a 也可以出现在func内部并且被使用. 理论上甚至我们可以在lambda里使用一些局部变量, 然后再局部变量的作用域之外的地方调用lambda.
int main()
{
// int a = 1;
// auto func = [a](int x,int y) -> void { printf("%d %d %d\n",a,x,y); };
void (*func) (int ,int);
{
int * a = new int(2);
func = [a](int x,int y) -> void { printf("%d %d %d\n",*a,x,y); };
}
while(1)
{
int x,y; cin>>x>>y;
func(x,y);
}
}
但是这段代码会报错, 因为我们不能把一个捕捉过变量的lambda表达式赋值给函数指针. 而至于怎么解决嘛, 请左转搜索: c++11 函数对象function
还有一些细致的规则就请自行了解吧, c++11的东西实在是太多啦 C++11 lambda表达式精讲
列表初始化
前面在介绍函数指针的时候就用到了这样一个一个一个好动系.
对于任何可以进行迭代的容器, 我们都可以使用列表初始化. vector, map, set, 数组, 甚至是一个类.
而我们只需要往大括号里面填东西就行了, 如果出问题程序会主动报错的.
class DemoClass
{
public:
int x;
double y;
char z;
}aa = {1,1.2,'c'};
vector<int> bb = {1,2,3,4};
int cc[] = {1,2,3,4};
int * ptr = new int [ 6 ] {1,2,3,4};
至于我们如果想自定义 列表初始化 初始化类的方式
class DemoClass
{
public:
std::vector<int> vec;
DemoClass(std::initializer_list<int> list)
{
for (auto it = list.begin(); it != list.end(); it++)
vec.push_back(*it);
}
};
int main()
{
DemoClass a { 1, 2, 3, 4, 5, 6 };
DemoClass b { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
return 0;
}
显然我们可以通过它来快速给一个对象初始化.
多线程
在这之前我们先来介绍许许多多的概念:
-
进程
狭义定义:进程是正在运行的程序的实例(an instance of a computer program that is being executed)。
广义定义:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。(复制自百度)
-
线程
通常在一个进程中可以包含若干个线程,它们可以利用进程所拥有的资源,在引入线程的操作系统中,通常都是把进程作为分配资源的基本单位,而把线程作为独立运行和独立调度的基本单位,由于线程比进程更小,基本上不拥有系统资源,故对它的调度所付出的开销就会小得多,能更高效的提高系统内多个程序间并发执行的程度。
说人话就是, 一个运行的程序可以被称为一个进程, 而在它是由许许多多个线程组成的, 每个线程之间可以独立地运行一些耗时任务, 同时线程也可以使用系统分配给进程的资源, 每个线程也有独属于自己的资源( 比如支持函数间互相调用所使用的栈 ), 线程之间也可以(指自己想办法实现)进行通讯. 但是请了解一些事情, 比如进程之间的通讯一般是比较耗时的, 通常是线程间通讯的好几倍甚至好几十倍. (血淋淋的教训).
多线程的优势在哪里呢? 很显然的一点是, 如果我们在main函数里有一个比较耗时的任务(比如循环个1e9次)但是我们并不着急需要这个循环的结果, 我们甚至还有很多耗时任务等待完成, 那么我们可以把这个耗时任务分配给另一个线程进行, 这样我们的主线程就可以该干什么干什么去, 等到需要这个结果的时候大概率子线程已经运算完毕可以直接使用结果了.
- 在一个进程发起后, 首先会进入一个缺省的线程, 通常称这个线程为主线程, C++中的主线程就是通过main函数进入的线程. 而由主线程衍生的线程称为从线程或子线程, 子线程也可以有自己的入口函数, 作用相当于主线程的main函数. 一般子线程的入口函数由用户指定, 而这个入口函数, 正如main函数会有参数与返回值的限制一样, 子线程的入口函数一般也有固定的格式要求. (但是好像在C++11里增加了参数列表这一新功能后, 可以给子线程传递任意参数)
talk is cheap, show you the code!
#include <iostream>
#include <thread>
#include <chrono>
void foo()
{
std::cout << "foo is started\n";
// 模拟昂贵操作
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "foo is done\n";
}
void bar()
{
std::cout << "bar is started\n";
// 模拟昂贵操作
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "bar is done\n";
}
int main()
{
std::cout << "starting first helper...\n";
std::thread helper1(foo);
std::cout << "starting second helper...\n";
std::thread helper2(bar);
std::cout << "main start sleeping\n";
std::this_thread::sleep_for(std::chrono::seconds(5));
std::cout << "main sleeping ended\n";
std::cout << "done!\n";
}
刚刚在实现了新功能的同时, 程序输出了一个奇怪的东西. 那是因为还有事情没有介绍完全.
-
在一个线程的生命周期内, 它可以在多种状态中切换, 在不同操作系统中有不同的线程模型, 但大体上线程都包含了以下几种状态:
就绪: 参与调度, 等待被执行, 一旦被调度选中立即开始执行.
运行: 占用CPU, 正在运行中.
休眠: 暂不参与调度, 等待特定事件发生.
终止: 已经运行完毕, 「等待」回收线程资源 (注意加粗内容, 后面会有坑)
-
常见的线程模型中, 除了主线程比较特殊之外, 其他线程一旦被创建相互之间就是对等的, 不存在隐含的层次关系. 这里主线程的特殊之处在于, 无论子线程执行完毕与否, 一旦主线程执行完毕退出, 所有子线程都会被终止. 这会导致整个进程结束或僵死 ( 部分线程保持一种终止执行但还未被销毁的状态, 而进程必须在所有线程销毁后销毁, 这时进程进入僵死状态).
-
需要强调的是, 线程无论是执行完毕退出, 亦或是其他奇怪的原因终止, 进入终止状态, 系统为线程分配的资源未必得到释放, 而且可能在系统重启之前一直都不能释放. 终止态的线程仍作为一个线程实体存在于操作系统中, 而什么时候销毁线程取决于线程的属性.
-
这种线程的终止方式肯定不是我们所期望的结果, 而且如果子线程是因为主线程结束而被终止的, 子线程因为运行所申请的资源也不一定被释放( 比如网络端口, 持有的设备, 申请的动态内存等 ).
所以针对以上的问题, 主线程与子线程通常定义两种关系:
- 可会合( joinable ) 在这种关系下, 主线程需要明确的执行等待操作, 在子线程执行结束后主线程的等待操作才算结束, 子线程与主线程会合, 主线程继续做它的任务. 需要强调的是, 即使子线程在主线程调用等待操作之前就执行完毕, 并进入终止态, 也必须执行会合操作, 否则系统永远不会主动销毁子线程.
- 相分离( detached ) 在这种关系下主线程无需与子线程会合. 在这种关系下, 子线程一旦进入终止状态, 系统会立即销毁线程回收资源. 需要注意一点, 在分离前, 主线程可以访问子线程的一些属性( 比如线程id或句柄 ), 而分离后主线程就与子线程再无瓜葛.
了解了这些后, 我们再审视上面的代码:
#include <iostream>
#include <thread>
#include <chrono>
void foo()
{
std::cout << "foo is started\n";
// 模拟昂贵操作
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "foo is done\n";
}
void bar()
{
std::cout << "bar is started\n";
// 模拟昂贵操作
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "bar is done\n";
}
int main()
{
std::cout << "starting first helper...\n";
std::thread helper1(foo);
std::cout << "starting second helper...\n";
std::thread helper2(bar);
std::cout << "main start sleeping\n";
// std::this_thread::sleep_for(std::chrono::seconds(5));
helper1.join();
helper2.join();
std::cout << "main sleeping ended\n";
std::cout << "done!\n";
}
它大致完成了我们需要的任务.
再来介绍一些事情.
-
一些设备( 比如通讯的接口, 键盘的输入, 命令行的输出 )有些是明确的只能被一个线程占有(比如通讯端口), 而有一些并没有被明确的声明说只能被单独占有, 但是在被多个线程使用时可能会出现问题. 比如两个线程都在输出. (但是现在测试反而没有问题了...)
#include <iostream> #include <vector> #include <thread> #include <chrono> using namespace std; int athread(int a,int b) { cout<<"this is thread a "<<a<<" "<<b<<endl; this_thread::sleep_for(std::chrono::seconds(1)); } int bthread(int a,int b) { cout<<"this is thread b "<<a<<" "<<b<<endl; this_thread::sleep_for(std::chrono::seconds(1)); } int main() { cout<<"calling thread a"<<endl; thread ta(athread,1,2); cout<<"calling thread b"<<endl; thread tb(bthread,2,3); this_thread::sleep_for(std::chrono::seconds(3)); ta.join(); tb.join(); return 0; } -
多个线程在同时操作一段内存时, 也会出问题. 所以在多线程通信时要注意一下.
-
阻塞 : 有的时候, 可能因为一个线程需求某个资源, 而其他线程正在持有该资源, 亦或者因为一个线程调用了一个函数, 等待它的返回, 使得该线程进入等待状态. 我们一般把这个线程「卡」在这一步上的状态称为阻塞.
mutex
有这么一个类, 互斥锁( mutex ), 它提供了一些成员函数,
- lock() 上锁, 在调用这个函数的线程会 " 从名义上 " 拥有这个锁实例. 而任何其他线程尝试上锁的行为都会使得其线程进入阻塞状态. 直到持有这个锁的线程解锁
- unlock() 如上所说的解锁
而我们可以自行的把这个锁与某一些行为进行关联, 比如在对某个变量修改前尝试上锁, 这样所有对变量的修改行为都会严格意义上持有锁, 进而使得这个变量『线程安全』.
原子变量
一些操作系统(比如linux)提供了原子量级的变量操作, 使得线程在操作原子变量的时候是严格互斥的, 一般可以用来线程间的状态同步.
还有很多可以做到互斥的东西(比如条件变量个人认为还挺好用的), 有兴趣的话可以自行了解.
多线程想要使用的透彻一般需要了解的不只在于编程语言, 还需要对底层有充足的了解, 所以这里的介绍仅作为引入, 如果后续有需要深入了解请一定找一些大部头的书好好学学.
左值右值
(以下内容主要与性能的优化有关, 由于这部分内容与语法密切相关, 可能我讲的不会很好, 听完之后还是很迷的话就去搜搜了解一下吧 ,QAQ)
左值与右值的定义
很通俗但不一定正确的说, 左值就是可以出现在 = 左边的值, 右值就是出现在 = 右边的值. (好像说了些废话)
好像有了一个初步的认知, 但是什么可以被放在=的左边, 什么可以被放在右边呢?
int a = 5, b = 40, cc=b;
char ss[] = "saoisejf";
int c = a+b+1;
double d = fabs(-0.45);
可以看到, ( 在不考虑引用和指针时 )所有我们能放在=左边的一般都是一个变量, 而右边的可以是个常量, 可以是个表达式( 函数, 变量, 常量的组合 ) , 同时一个左值也可以是一个右值, 而右值就只能是右值.
它们之间似乎有什么区别. 如果我们运行下面的代码, 会产生什么结果?
int * a = &abs(-5);
一件稍加思索就可以确认的事情是, 无论是左值还是右值, 它的这个数值肯定在计算机里的某个位置, 不然总不能是CPU从虚空中构造了一串01码然后赋值到我们的左值所在的内存地址里了吧. 但是既然这个数值确实存在, 他就在计算机的某个地方存储, 为什么我们无法寻找它的地址? (小知识: 一般一些中间变量会被CPU存储在寄存器中, 在下一步赋值的时候再将它从寄存器中复制到目标内存位置)
所以我们需要承认, 我们作为用户只能接触到一部分的地址, 而确实存在一部分变量, 我们只能接触到它的数值. 而对于左值和右值又有了如下的理解.
- 左值是指具有「对应的」、「可由用户访问的」存储单元,并且能由用户改变其值的量。如一个变量就是一个左值,因为它对应着一个存储单元,并可由编程者通过变量名访问和改变其值。而右值是能由用户读取它的数值。
从 C++ Primer 中的定义来说, 或许更易理解:
变量和文字常量都有存储区, 并且有相关的类型. 区别在于变量是可寻址的( addressable ). 对于每一个变量都有两个值与其相关联:
- 它的数据值, 存储在某个地方当中, 有的时候这个值也称为对象的右值( rvalue ). 我们也可以认为右值的意思是被读取的值( read value ). 文字常量和变量都可以被用作右值.
- 它的地址值, 即存储数据值的那块内存的地址. 它有时被称为变量的左值( lvalue ), 我们也可以认为左值的意思是位置值( location value ). 文字常量不能被用作左值.
一个典型的例子:
a++ 先读取a的值, 再给a加1, 作为右值
int temp = a;
a = a + 1;
return temp;
++a 先给a加1, 再读取a的值, 为左值
a = a + 1;
return a;
与此同时, 虽然在c++98中临时对象不能作为左值, 但是可以作为常量引用, 即 const &
然后我们亲爱的C++11又将右值做了进一步的细分:
-
纯右值 : 非引用返回的临时变量( int func(void) )、运算表达式产生的临时变量(b+c)、原始字面量(2)、lambda表达式等。
-
将亡值 : 将要被移动的对象、T&&函数返回值、std::move返回值和转换为T&&的类型的转换函数的返回值。
将亡值可以理解为通过“盗取”其他变量内存空间的方式获取到的值。在确保其他变量不再被使用、或即将被销毁时,通过“盗取”的方式可以避免内存空间的释放和分配,能够延长变量值的生命期。
这里先下定义, 具体的阐释会在后面进行, 目前我们所认识的右值就是C++11中的纯右值.
左值引用和右值引用
左值引用就是我们所熟悉的引用, 我们再看一眼我们的老朋友
int a=6;
int &ref_a = a;
ref_a = 10;
cout<<a<<endl;
现在我们已经十分熟悉这段代码了(大概). 左值引用其实就是被引用对象的一个别名,
右值引用为了强调它仍是一种引用, 所使用的记号和左值引用很像, 右值引用只能获取一个右值.
int &&a=6;
cout<<a<<endl;
a=7;
cout<<a<<endl;
const int & a= 6;
需要注意的是, 这里并不是创造了一个叫做a的变量, 而只是把原本即将消逝掉的一个右值「捕获」起来. 通过右值引用进行「捕获」, 这个即将消逝的右值又"重获新生", 它的生命周期变得和这个引用一样长, 只要这个右值引用还活着, 这右值临时变量就会一直存在, 我们可以通过这个特性来进行一些性能的优化.
还有一点, 任何引用都不拥有所绑定对象的内存, 只是改对象的一个别名, 因此两种引用都是在声明的同时进行初始化.
还有一个比较特殊的东西, 常量左值引用, 它既可以接收左值, 也可以接受右值, 不过常量左值引用所引用的右值在它的"余生"中都只是可读的.
右值通常不能绑定到任何左值, 但是我们可以通过 std::move(var)来将一个左值强制转换成右值.
int a;
int &&r1 = a; // 编译失败
int &&r2 = std::move(a); // 编译通过
以及在move后, 原本那个左值所持有的内存一般来说已经易主了, 就是这个左值被"掏空了", 所以尽量不要在再次赋值前访问.
#include <iostream>
#include <utility>
#include <vector>
#include <string>
int main()
{
std::string str = "Hello";
std::vector<std::string> v;
//调用常规的拷贝构造函数,新建字符数组,拷贝数据
v.push_back(str);
std::cout << "After copy, str is \"" << str << "\"\n";
//调用移动构造函数,掏空str,掏空后,最好不要使用str
v.push_back(std::move(str));
std::cout << "After move, str is \"" << str << "\"\n";
std::cout << "The contents of the vector are \"" << v[0]
<< "\", \"" << v[1] << "\"\n";
}
还有一个比较坑的一点, 如果你在模板里尝试使用右值引用
template<class T>
void func(T&& x) { }
int& a;
func(a); x => int & x;
func(1); x => int && x;
实际上, 它并不代表右值引用, 它代表的是万能引用. 至于其中的类型推断是怎么进行的 以及 引用折叠规则, 这些请去看《Effective Modern C++》,其中介绍的十分清楚, 有关C++11的内容它也做了很多机理上的叙述, 从而引导我们如何去优美地编写现代化的代码.
然后我们考虑, 右值及右值引用是有何作用? 显然, 一个引用是右值引用的时候, 我们清楚的知道它所引用的物体不久后即将消逝, 而如果我们需要把它的数值传递给别的对象的话, 那就趁现在把它掏空是最佳的选择. 右值引用的标记保障了这个值可以随意被销毁. 这样的初级应用是对象的移动构造.
#include <iostream>
#include <vector>
using namespace std;
class DemoClass
{
public:
DemoClass(int array[],int len)
{
puts("调用构造函数");
data.reserve(len);
for(int i=0;i<len;i++)
data.emplace_back(array[i]);
}
DemoClass(DemoClass& rhs)
{
puts("调用拷贝构造函数");
int len = rhs.data.size();
data.reserve(len);
for(int i=0;i<len;i++)
data.emplace_back(rhs.data[i]);
}
DemoClass(DemoClass&& rhs)
{
puts("调用移动构造函数");
data = std::move(rhs.data);
}
void output()
{
for(auto x:data)
cout<<x<<" ";
puts("");
}
private:
vector<int> data;
};
int main()
{
int num[] = {0,1,2,3,4,5,6,7,8,9};
int len = 10;
DemoClass a(num,len);
a.output();
DemoClass b(a);
a.output();
b.output();
DemoClass c(std::move(a));
a.output();
c.output();
}
补充知识
Cmake
这是一个高级编译工具, 因为用过的人都说爽, 所以你们之后"必须"说爽了.(doge
我这里有一个markdown的教程, 各位也可以自行搜索教程, 并不是一个很难的东西.
这里稍微用Hello World演示一下.
# CMakeLists.txt
PROJECT (HELLO_WORLD)
SET(SRC_LIST main.cpp)
ADD_EXECUTABLE(hello ${SRC_LIST})
最后的最后
学习编程最重要的不是学会编程, 而是学会怎么学习
还是那句话, 现在互联网上资源是很多的, 实在不行花点钱, 大概率都能找到需要的资源. 新赛季的规则大家也看见了, 改动很大, 不确定这个规则在今年的试水后会不会再有变动, 但可以肯定的是, 各位今后的道路都不会简单. 4节课对于培训来说太少太少, 希望各位能做到主动学习, 在自己的人生道路上不断的前进.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号