
JavaSE
-
String str ="";System.out.print(str.split(","length);输出结果为 1
/**String split 这个方法默认返回一个数组,如果没有找到分隔符,会把整个字符串当成一个长度为1的字符串数组返回到结果,所以此处结果就是1 */
String str = "12,3";
String str2 = "123";
System.out.print(str.split(",").length); ===>2
System.out.print(str2.split(",").length); ===>1 -
java8中,下面哪个类用到了解决哈希冲突的开放定址法 C
LinkedHashSet HashMap ThreadLocal TreeMap
ThreadLocalMap中使用开放地址法来处理散列冲突,而HashMap中使用的是分离链表法。之所以采用不同的方式主要是因为:在ThreadLocalMap中的散列值分散得十分均匀,很少会出现冲突。并且ThreadLocalMap经常需要清除无用的对象,使用纯数组更加方便。
hreadlocal 使用开放地址法 - 线性探测法:当前哈希槽有其他对象占了,顺着数组索引寻找下一个,直到找到为止
hashset 中调用 hashmap 来存储数据的,hashmap 采用的链地址法:当哈希槽中有其他对象了,使用链表的方式连接到那个对象上 -
关于Java中参数传递的说法,哪个是错误的?D
A. 在方法中,修改一个基础类型的参数不会影响原始参数值 B. 在方法中,改变一个对象参数的引用不会影响到原始引用 C. 在方法中,修改一个对象的属性会影响原始对象参数 D. 在方法中,修改集合和Maps的元素不会影响原始集合参数
解析: 注意!Java中方法的参数传递都是值传递
public static void main(String []args){
t i = 5 fu(i);
Systemut.pntln(i);
}
static vo nc(int j){
j =10;
} /输出结5在主方法调用func(int j) 时 , 参数i是实际参数 , 值为5 , 参数j是形式参数 , 值是i给的 , 也是5 , i和j没有任何关系 , 是两个独立的参数 , 所以修改j的值时与i没有关系 , 仍然输出5。
B. 在方法中,改变一个对象参数的引用不会影响到原始引用
public static void main(String []args){
User rabbiter = new User();
rabbiter.setName("rabbiter");
func(rabbiter);
System.out.println(rabbiter.getName());
}
static void func(User user){
user = new User();
user.setName("zhangsan");
} //输出结果rabbiter在主方法调用func(User user) 时 , 对象rabbiter保存的是一个地址值 , 在方法体中,有重新new了一个User(), 所以并不违反值传递的理论。
C. 在方法中,修改一个对象的属性会影响原始对象参数
public static void main(String []args){
User rabbiter = new User();
rabbiter.setName("rabbiter");
func(rabbiter);
System.out.println(rabbiter.getName());
}
static void func(User user){
user.setName("zhangsan");
} //输出结果zhangsan在主方法调用func(User user) 时 , 对象rabbiter保存的是一个地址值 , 本质上就是把rabbiter的地址值给了形参user , 所以此时实参rabbiter和形参user指向在堆中的同一个对象 , 他们的地址值相同 , 指向的对象一致 , 所以并不违反值传递的理论。
D. 在方法中,修改集合和Maps的元素不会影响原始集合参数
-
在面向对象编程里,经常使用is-a来说明对象之间的继承关系,下列对象中不具备继承关系的是?D
手机与小米手机 企业家与雷军 编程语言与Java 中国与北京
用is a来说明对象之间的继承关系:
小米手机 is a 手机;
雷军 is a企业家;
Java is a 编程语言;
北京 is not a中国。 -
为什么String不可变
-
字符串常量池的需要
字符串常量池(String pool, String intern pool, String保留池) 是Java堆内存中一个特殊的存储区域, 当创建一个String对象时,假如此字符串值已经存在于常量池中,则不会创建一个新的对象,而是引用已经存在的对象。
如下面的代码所示,将会在堆内存中只创建一个实际String对象.
String s1 = "abcd";String s2 = "abcd";假若字符串对象允许改变,那么将会导致各种逻辑错误,比如改变一个对象会影响到另一个独立对象. 严格来说,这种常量池的思想,是一种优化手段.
请思考: 假若代码如下所示,s1和s2还会指向同一个实际的String对象吗?
String s1= "ab" + "cd";String s2= "abc" + "d"; ==>true*2. 允许String对象缓存HashCode* Java中String对象的哈希码被频繁地使用, 比如在hashMap 等容器中。
字符串不变性保证了hash码的唯一性,因此可以放心地进行缓存.这也是一种性能优化手段,意味着不必每次都去计算新的哈希码. 在String类的定义中有如下代码:
private int hash;//用来缓存HashCode**3. 安全性*
String被许多的Java类(库)用来当做参数,例如 网络连接地址URL,文件路径path,还有反射机制所需要的String参数等, 假若String不是固定不变的,将会引起各种安全隐患。
假如有如下的代码:
boolean connect(string s){
if (!isSecure(s)) {
throw new SecurityException();
} // 如果在其他地方可以修改String,那么此处就会引起各种预料不到的问题/错误
causeProblem(s);
} -
-
为什么char数组比Java中的String更适合存储密码?
1.由于字符串在Java中是不可变的,如果你将密码存储为纯文本,它将在内存中可用,直到垃圾收集器清除它。并且为了可重用性,会存储在字符串池中,它很可能会保留在内存中持续很长时间,任何有权访问内存转储的人都可以以明文形式找到密码,从而构成安全威胁。
2.Java本身建议使用JPasswordField的getPassword()方法,该方法返回一个char[]和不推荐使用的getTex()方法,该方法以明文形式返回密码。
3.使用String时,总是存在在日志文件或控制台中打印纯文本的风险,但如果使用Array,则不会打印数组的内容而是打印其内存位置。虽然不是一个真正的原因,但仍然有道理。
-
**hashMap在jdk1.7和jdk1.8区别
1如果链表的长度超过了8,那么链表将转换为红黑树。(桶的数量必须大于64,小于64的时候只会扩容)
2发生hash碰撞时,java 1.7 会在链表的头部插入,而java 1.8会在链表的尾部插入
3在java 1.8中,Entry被Node替代(换了一个马甲)。
jdk1.8中第一次添加元素的时候,默认初期长度为16,当往map中继续添加元素的时候,通过hash值跟数组长度取“与”来决定放在数组的哪个位置,如果出现放在同一个位置的时候,优先以链表的形式存放,在同一个位置的个数又达到了8个(代码是>=7,从0开始,及第8个开始判断是否转化成红黑树),如果数组的长度还小于64的时候,则会扩容数组。如果数组的长度大于等于64的话,才会将该节点的链表转换成树。在扩容完成之后,如果某个节点的是树,同时现在该节点的个数又小于等于6个了,则会将该树转为链表。
因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
-
HashMap的知识
1)、HashMap的构造方法:①、无参构造;②、有一个参数构造;③、两个参数构造
值得注意的是,当我们自定义HashMap初始容量大小时,构造函数并非直接把我们定义的数值当做HashMap容量大小,而是把该数值当做参数调用方法tableSizeFor,然后把返回值作为HashMap的初始容量大小:该方法会返回一个大于等于当前参数的2的倍数,因此HashMap中的table数组的容量大小总是2的倍数。
/**
Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}2)、(1)Hash桶、哈希表、哈希值、碰撞的概念
(2)jdk1.7里的HashMap:
☆☆☆☆☆
①默认初始容量必须是2的幂,为什么?
在通过indexFor(),把hashCode和容量进行按位与计算,即hash&(length-1),length-1 = 2^n-1,列如:2^n是1000,2^n-1 = 111,对其进行按位与可以快速获取数组下标。可以减少碰撞的发生,并且让散列尽可能的均匀分布。
默认构造函数初始容量(哈希桶的个数)为16,注:是在第一次往里面加的时候创建的。
②java7中遇到的问题:
1). 安全问题:碰撞退化成链表
2). 并发环境容易死锁:线程不安全:
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
do {
Entry<K,V> next = e.next; // <--假设线程一执行到这里就被调度挂起了
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while(e != **null**);而我们的线程二执行完成了。于是我们有下面的这个样子。
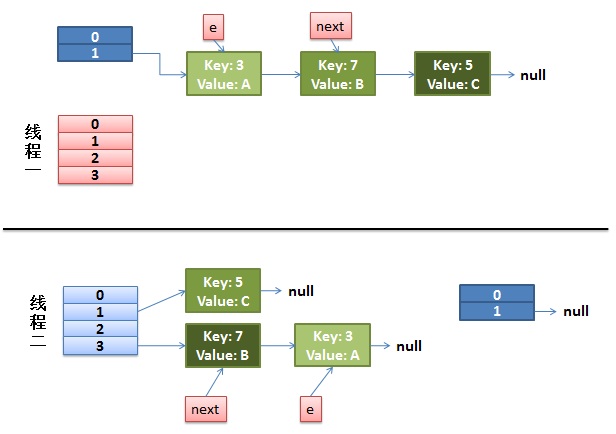
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
-
先是执行 newTalbe[i] = e;
-
然后是e = next,导致了e指向了key(7),
-
而下一次循环的next = e.next导致了next指向了key(3)
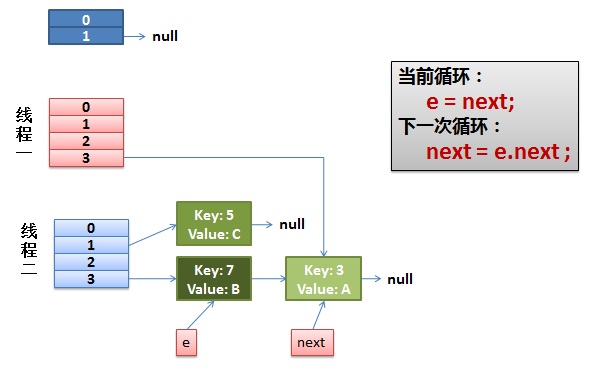
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
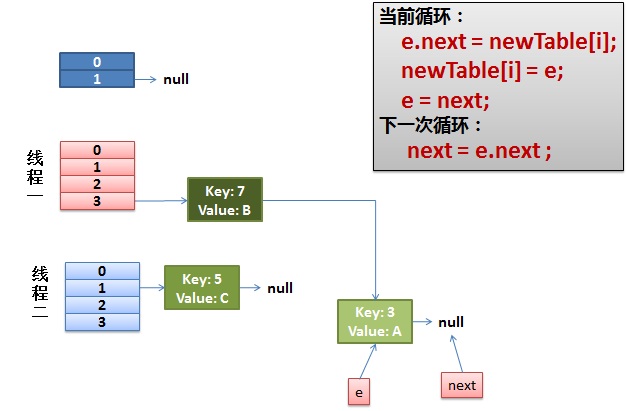
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
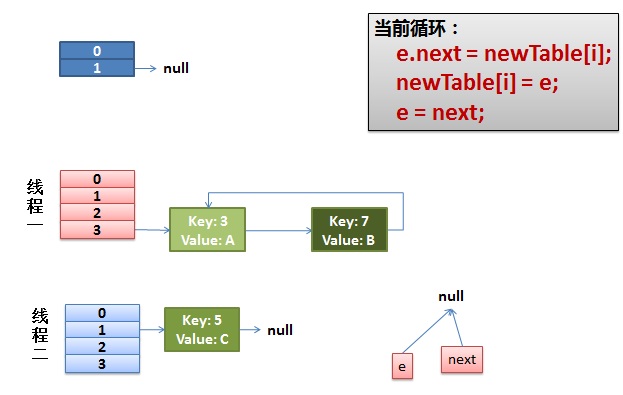
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
(3)Java8里的HashMap
①为什么TREEIFY_THRESHOLD(树化的阈值)是8?
因为符合泊松分布,超过8的概率已经非常小了。
(4)何时扩容 : >LOAD_FACTOR * CAPACITY时(16 * 0.75f = 12)
-
-
ArrayList实现了List接口,常见方法有: add(); contains(); get(); indexOf():定位对象所处的位置; remove(); size(); toArray(); toString();//转换为字符串
LinkedList也实现了List接口外,可以实现上述ArrayList中的常用方法,此外: 1.LinkedList还实现了双向链表结构Deque,可以很方便的在头尾插入删除数据。 LinkedList<class> link = new LinkedList<>(); 常用方法:addFirst(); addLast(); getFirst(); getLast(); removeFirst(); removeLast();
2.LinkedList除了实现了List和Deque外,还实现了Queue接口(队列),Queue是先进先出队列 FIFO。 Queue<class> queue = new LinkedList<>(); 常用方法:poll()取出第一个元素; peek()查看第一个元素; offer()在最后添加元素,可用add()替换;
先进后出FILO Stack栈: Stack<class> stack = new Stack<>(); 常用方法:push();可用add();代替 pop();输出末尾的元素相当于LinkedList中的removeLast(); peek();查看最后一个元素,相当于getLast();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号