
【Spark SQL】Join连接条件使用or导致运行慢
现象
运行的SQL示例如下
select
t1.*
from edw.a t1
left join edw.b t2
on (t1.id = t2.id or ((t1.id is null or t2.id is null) and t1.phone = t2.phone))
and t1.province = t2.province
and t1.city = t2.city
and t1.type = t2.type
where t2.type is null
;
提交运行后发现部分task时间非常久。
在Spark UI上观察执行情况,发现join上的数据超过1000亿。
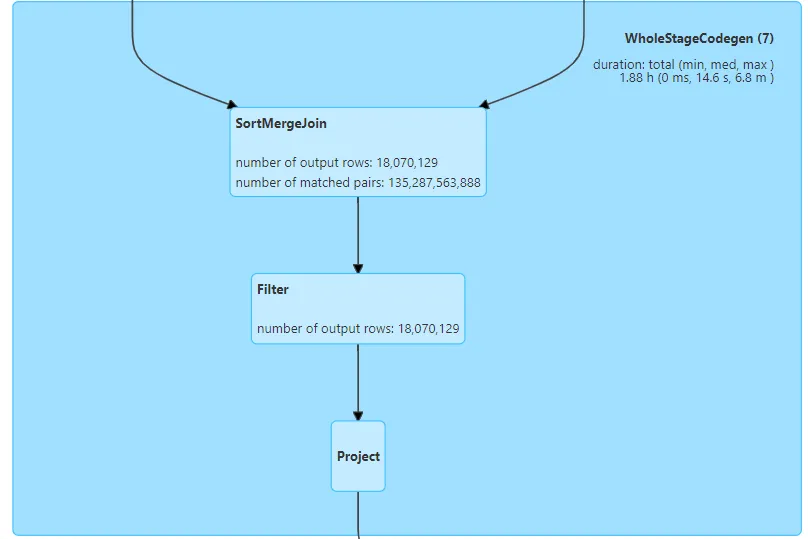
检查执行计划,发现分区过程只用到了city、type、province三个字段,没有用到id和phone字段。

由于city、type、province三个字段重复值特别多,导致关联上的数据特别多。
解决方案
修改SQL
错误改法:使用union把两部分合并
因为这里用到了or,容易想到进行union操作
select
t1.*
from edw.a t1
left join edw.b t2
on t1.id = t2.id
and t1.province = t2.province
and t1.city = t2.city
and t1.type = t2.type
where t2.type is null
union
select
t1.*
from edw.a t1
left join edw.b t2
on (t1.id is null or t2.id is null)
and t1.phone = t2.phone
and t1.province = t2.province
and t1.city = t2.city
and t1.type = t2.type
where t2.type is null
;
执行之后发现结果不符合预期,最后输出的结果就是edw.a表的全量数据。
问题在于逻辑中是取没有匹配上的数据t2.type is null,操作等于取两个条件并集的补集,而合并后是取两个条件补集的并集,最后得到了全集。
正确改法:使用两个join关联
select
t1.*
from edw.a t1
left join edw.b t2
on t1.id = t2.id
and t1.province = t2.province
and t1.city = t2.city
and t1.type = t2.type
left join edw.b t3
on (t1.id is null or t3.id is null)
and t1.phone = t3.phone
and t1.province = t3.province
and t1.city = t3.city
and t1.type = t3.type
where t2.type is null
and t3.type is null
;
改动后
- join中会用到id和phone作为shuffle的条件,匹配到的数据量减少,执行速度大幅提高。
- 输出的数据符合预期。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号