正则表达式-基础知识
正则表达式
正则表达式,是一种独立的工具独立的语言,不依赖于python.只和字符串打交道,从大段的内容中找到符合规则的内容
是一种专门用来做字符串匹配的工具,能够在某些情况下让字符串的处理变得简单.
在线测试网址 http://tool.chinaz.com/regex/
[0-9a-zA-Z]表示所有的数字和大小写字母
一.元字符:
\w 匹配数字字母下划线 word关键字 [a-zA-Z0-9_](难以区分所要取的值,不好用)
\d 匹配所有的数字 digit [0-9]
\s匹配所有的(空字符 回车 /换行符 制表符 空格) space[\n\t]
- \n 匹配换行符 回车
- \t 匹配制表符 tab
- 匹配空格
\W和\w取反
\D和\d取反
\S和\s取反
\b表示单词的边界
- [\s\S][\w\W][\d\D]是三组全集 意思是匹配所有字符
- (一般我们不希望匹配所有字符,不好用,只是了解一下)
二.边界修饰符
^表示匹配以某字符串为开头;匹配行首的字符要使用抑扬字符(^)——有时也被叫做插入符
$表示匹配以某字符串为结尾
三.量词(匹配次数):
* 表示 0-多次(任意次数都可以)
+ 表示 一次或者多次(至少一次)
? 表示0次或者一次
.点 表示匹配除“\n”和"\r"之外的任何单个字符。要匹配包括“\n”和"\r"在内的任何字符,请使用像“[\s\S]”的模式。
{}
{n}表示匹配到n次
{n,}表示匹配到至少n次
{n,m}表示匹配到n-m次
四.贪婪与惰性(非贪婪)
表达式 .* 就是单个字符匹配任意次,即贪婪匹配.
表达式 .*? 是满足条件的情况只匹配一次,即最小匹配.
默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
贪婪:在能匹配成功的前提下,匹配次数选最多的
- (+、、?、{n,m}、{n,}、{,m})
- 很单纯的量词,后面没有?
非贪婪:在能匹配成功的前提下,匹配次数选最少的
- .? 匹配 除换行符之外的0-1次
- .* ? 匹配 除换行符之外的任意多次
- .+? 匹配 除换行符之外的1-多次
- +? 匹配 除换行符之外的1-多次
- {n}? 匹配n次
- {n,m}? 匹配n次
- {n,}? 匹配n次
- {,m}? 匹配n次
出现n-m次,前面要加一个.点, 不然数据会多一位
举个栗子
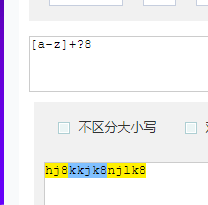
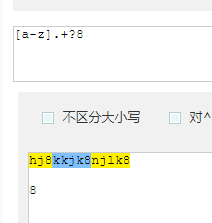
[a-z].+?8和[a-z]+?8结果是一样的
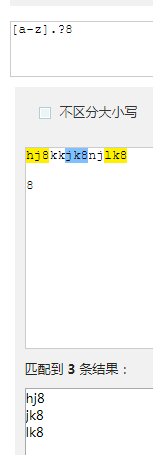
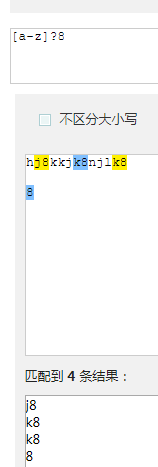
[a-z].?8和[a-z]?8结果是不一样的, .去掉了换行符以外的8;因为. 代表的是匹配除换行符之外的
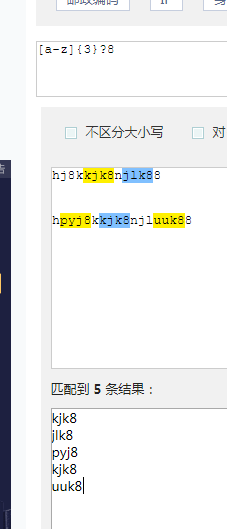
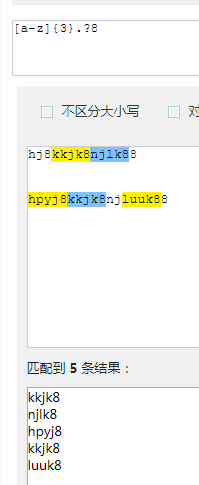
[a-z]{3}.?8和 [a-z]{3}?8结果不一样,有.的结果是我们想要的,一定要在?前面加上. 否则结果就不对,会多一位数.
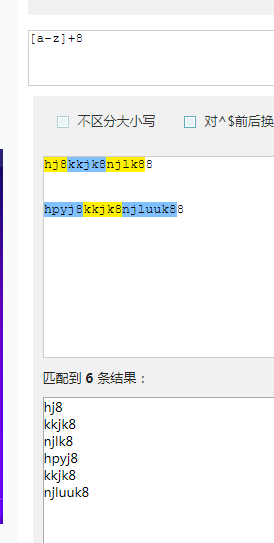
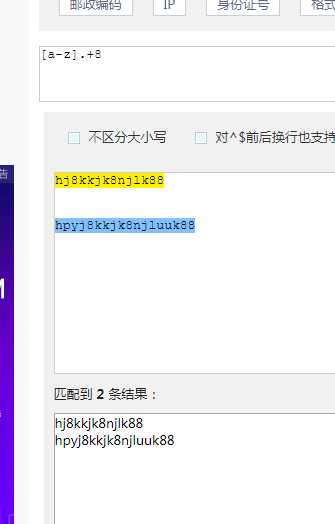
[a-z].+8和[a-z]+8结果是不一样的, .去掉了换行符以外的8;因为. 代表的是匹配除换行符之外的
五.分组
1.() 分组中的内容优先被匹配
举个栗子:
<head>wahaha</head>
如何获取wahaha
(wahaha)
2.整体操作次数
举个栗子:
(a-zA-Z0-9){2-3} 表示字母或者数字出现的次数为2-3次
正则匹配
.是元字符 匹配任意字符
第一个?是两次 标识匹配0-1次
第二个?是约束惰性匹配的标志表示.的匹配应该尽可能少匹配
后面的和约束了.的匹配必须多匹配一个字斗则就没有匹配的结果了;
惰性匹配:如果在量词的后面加?且在这一组正则之后没有其他的匹配需求了,那么这个问号的意思就是尽量少匹配.
如果在这一组正则之后还有其他条件,那么这个问号的意思就是在能匹配上的基础上尽量少匹配
|
正则 |
待匹配字符 | 匹配结果 | 说明 |
| [0123456789] | 8 | TRUE | 在一个字符组里枚举合法的所有字符,字符组里的任意一个字符和"待匹配字符"相同都视为可以匹配 |
| [0123456789] | a | flase | 由于字符组中没有"a"字符,所以不能匹配 |
| [0-9] | 7 | true | 也可以用-表示范围,[0-9]和[0123456789]是一个意思 |
| [a-z] | s | true | 同意的如果要匹配所有的小写字母,直接用[a-z]就可以表示 |
| [A-Z] | B | true | [A-Z]表示所有的大写字母 |
| [0-9a-fA-F] |
e |
true | [A-Z]表示所有的大写字母 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号