

知识图谱表示学习与关系推理(2016-2017)(一)
笔者:整理2016-2017年ACL、EMNLP、SIGIR、IJCAI、AAAI等国际知名会议中实体关系推理与知识图谱补全的相关论文,供自然语言处理研究人员,尤其知识图谱领域的学者参考,如有错误理解之处请指出,不胜感激!(如需转载,请联系本人:jtianwen2014,并注明出处)
ACL 2016
Unsupervised Person Slot Filling based on Graph Mining
- 作者:Dian Yu, Heng Ji
- 机构:Computer Science Department, Rensselaer Polytechnic Institute
本文的任务为槽填充(Slot Filling),即从大规模的语料库中抽取给定实体(query)的被明确定义的属性(slot types)的值(slot fillers)。对于此任务,本文叙述目前主流的方法可以分为两类:有监督的分类方法,设计分类器识别给定的实体与值所属的关系类型,分类器的训练往往使用如活动学习、利用距离监督的噪声标注等方法;模式匹配方法,从文本中自动或半自动地抽取和生成词法或句法的模式,以用于关系的抽取,但因为关系所表述的方式千差万别,这种模式匹配方法无法拥有较好的召回率。
本文认为,以上两类方法都无法很好的应对新的语言或是出现新的关系类型的情况,即移植性不强;而且,两种方法都只是专注于实体和候选值之前的平坦表示,并没有考虑到它们之间的全局结构关系,以及语句中其他的关系事实的影响。本文重要的算法思想基于以下两个观察:
- 在句子的依存图中,触发词结点(trigger)经常是和实体(query)与值(filler)结点都很相关的,并且是图中的重要节点;
- 当实体(query)与值(filler)结点通过一个关系明确的触发词强关联起来,往往意味着存在一定的关系(slot type)。
基于以上两个观察,本文的提出了一种基于图的槽填充的方法:首先,利用简单的启发式规则,从句子中识别出候选实体与属性值;然后,对于给定候选实体与属性值对,利用PageRank图算法和AP(Affinity Propagation)聚类算法自动识别触发词;最后,根据识别的触发词对属性类型(slot type)进行分类。
下图为利用PageRank算法对候选触发词结点打分:
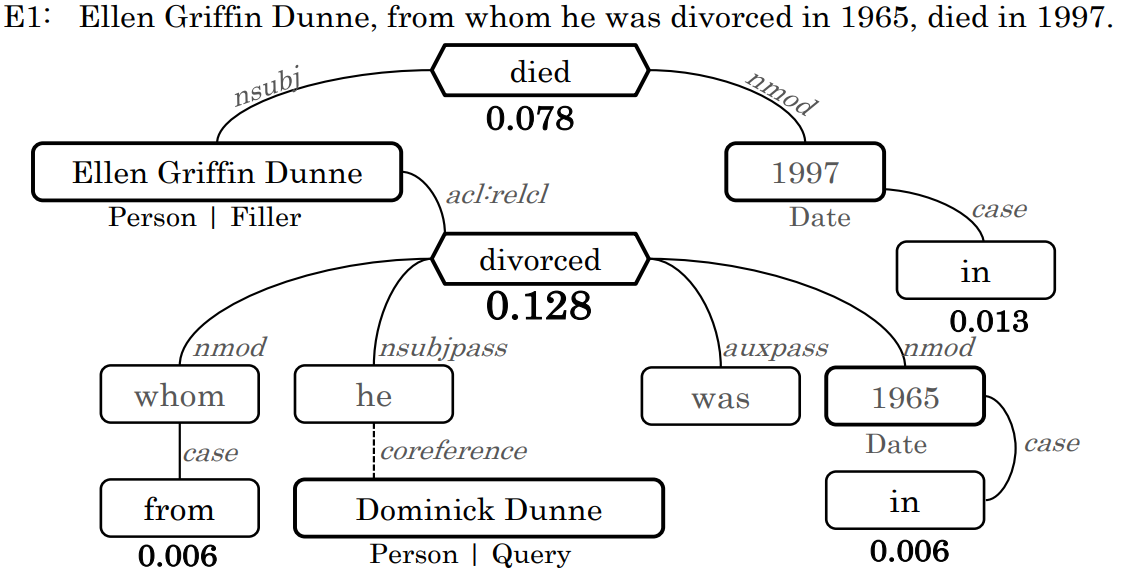
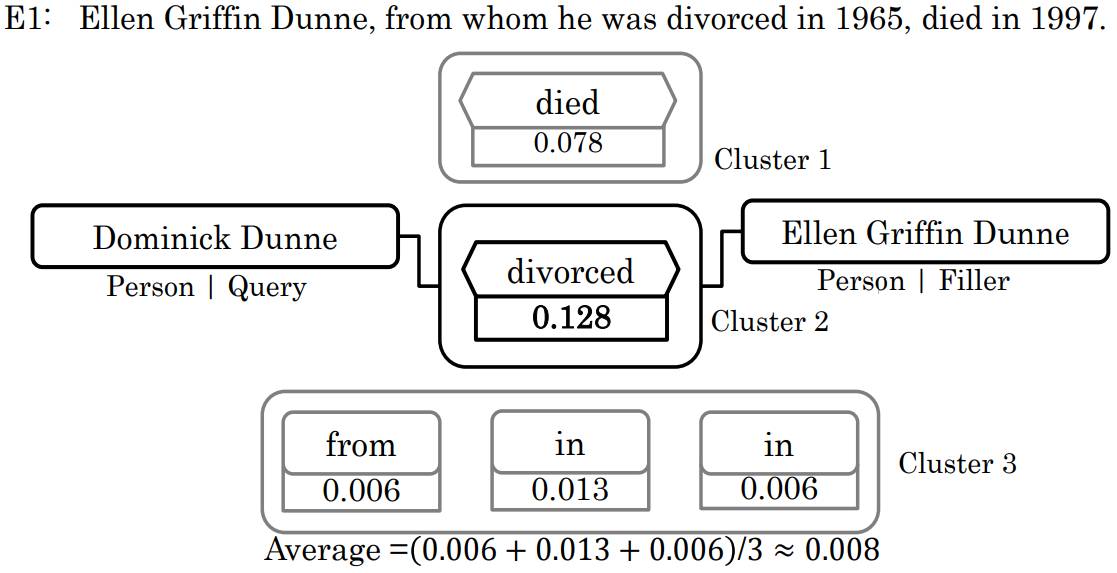
下图为利用AP算法对候选触发词进行聚类(关系触发词可能不止一个单词),以选定最终触发词。如下图最终选定“divorced”为最终触发词。
笔者:本文主要的思想与创新点在于,以属性触发词为切入点进行关系的挖掘,将PageRank算法与AP算法引入其中,将槽填充问题转换为图上的挖掘问题。候选实体与属性值的识别、属性类型的分类这两个部分使用了启发式的规则与外部的词典资源。但这中图挖掘的方法,由于应用句法依存与PageRank算法有可能在计算复杂性上存在问题。
Knowledge Base Completion via Coupled Path Ranking
- 作者:Quan Wang†, Jing Liu‡, Yuanfei Luo†, Bin Wang†, Chin-Yew Lin‡
- 机构†:Institute of Information Engineering, Chinese Academy of Sciences
- 机构‡:Microsoft Research
本文的任务为知识库补全,即通过考察知识库中已经存在的事实,自动推理出丢失的事实。本文叙述这项任务的方法大体分为三种:
- Path Ranking 算法(PRA),通过连接实体的已有路径来预测实体间的潜在关系;
- 基于表示学习的模型,将实体和关系映射为空间中的向量,通过空间中向量的运算来进行推理(如TransE);
- 概率图模型,如马尔科夫逻辑网络及其衍生物。
由于PRA方法具有较好的解释性,并且不需要额外的逻辑规则,本文主要使用PRA方法对其改进。在利用PRA进行关系推理时,以往的方法都是在推理阶段,利用PRA为每个关系独立建模,也就是为每个关系学习一个独立的分类器。
本文的初衷是:如果使用PRA对某些关系集体建模是否会得到更好的效果,尤其是当这些关系彼此紧密联系的时候,比如,“出生”和“生长于”这两个关系极有可能共同拥有一些关系路径:“国籍->首都”等。很多研究表明这种多任务学习相比单任务学习而言,往往具有更好的效果。本文提出CPRA的方法,该方法所要解决两个问题:(1)哪些关系需要组合在一起学习?(2)如何组合在一起学习?
(1)哪些关系需要组合在一起学习?本文提出了一种基于公共路径的相似度度量方法,并在此基础上将关系聚成不同的组,同组的关系共同学习。公共路径的相似度具体值依据两个关系(或簇)的路径交集数量占比。
(2)如何组合在一起学习?依循多任务学习的原则,对于共同训练的分类器使用两部分参数,即共享参数和私有参数。共享参数可以体现相似关系之间的得共性,私有参数用于描述不同关系之间的特性。这两类参数在训练过程中是联合学习的。
笔者:PRA的方法的应用可能存在局限,比如对于开放域知识图谱,如Reverb等,其关系类型多样且未事先定义,则无法对于每个类别训练分类器;而且这种每个类别训练分类器的方法消耗实在较大,更不利于给定实体对的关系推理。是否可以统一为一个分类器,或者不是分类器,而是生成器,生成给定实体对的可能关系,这样就应用于关系类型体系未知的开放域知识图谱。
Compositional Learning of Embeddings for Relation Paths in Knowledge Bases and Text
- 作者:Kristina Toutanova, Xi Victoria Lin∗, Wen-tau Yih, Hoifung Poon, Chris Quirk
- 机构:Microsoft Research
- 机构∗:University of Washington
本文的任务为知识图谱补全,推理预测实体间潜在的关系。本文叙述,当前的一些学者将关系路径信息融入到知识库嵌入式表示中,取得了非常显著的结果。知识库嵌入式表示,指的是将知识库中实体和关系映射到低维稠密的空间中,知识的推理转化为实体与关系所关联的向量或矩阵之间的运算。这种嵌入式的表示,操作花销较小,推理的效率较高。为了进一步提升基于嵌入式表示的关系推理,一些学者将关系路径信息融入其中。
本文发现,目前的将关系路径融入知识库的嵌入式表示方法存在如下问题:首先,当关系的路径总类增多时,时间开销较大,严重影响推理的效率;另外,目前的方法只考虑了路径信息,没有考虑结点的信息,即使是相同路径,包含不同结点也拥有不同的信息。本文提出了一种动态规划的方法,可以高效地将关系路径融入到知识库的嵌入式表示,并且同时对路径上的关系类型和结点进行表示。
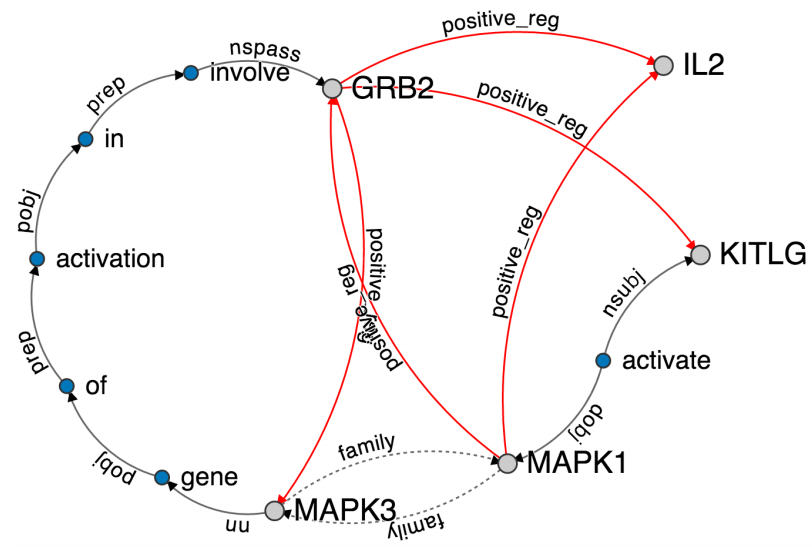
本文以基因调控网络为例,网络的节点是基因,边为两个关键的关系:正调控、负调控,为了联合表示文本信息,将基因共现的文本语句的依存关系嵌入到网络中,所下图所示,红色边为原网络的调控关系,灰色边为文本依存信息:
基本的知识图谱嵌入式表示学习的方法是,首先学习实体和关系的向量(或矩阵)表示,然后一用学习到的参数\(\theta\)和函数\(f(s,r,t|\theta)\)为可能的三元组进行打分。其中,双线性模型(BILINEAR)用矩阵表征关系,向量表征实体,打分函数\(f\)定义为:\(f(s,r,t|\theta)=x_s^{\rm T}W_rx_t\)。
另外,为了减少参数,本文介绍了另一种模型双线性-对角模型,即将关系矩阵\(W\)替换为对角矩阵。
将关系路径引入嵌入式表示一般有两种方法:(1)利用关系路径生成辅助的三元组用于训练(通过随机游走获得路径,端点实体的关系用关系路径代替);(2)将关系路径作为特征用于打分,打分函数替换为\(f(s,r,t|\theta,\prod_{s,t})\),\(\prod_{s,t}\)为路径上关系嵌入式表示的加权求和。对于双线性模型,关系路径\(\pi\)的嵌入式表示一般为:\(\Phi_{\pi}=W_{r_1}...W_{r_n}\)。
本文更偏向于第二种方法,因为其对路径上的关系进行剪枝。本文对\(f(s,r,t|\theta,\prod_{s,t})\)做了详细设计与定义:用\(F(s,t)\)代表\(\prod_{s,t}\),用\(P(t|s,\pi)\)代表头实体经过路径到达尾实体的概率,令:\(F(s,t)=\sum_{\pi}w_{|\pi|}P(t|s,\pi)\Phi(\pi)\)。最终\(f(s,r,t|\theta,\prod_{s,t})\)定义为:
其中\(F(s,t)\)的计算时间消耗较大,本文通过使用动态规划的方法ALL-PATH高效学习与计算该打分函数,使得可以高效地将关系路径融入到知识库的嵌入式表示,并且同时对路径上的关系类型和结点进行表示。本文用参数\(w_{e_i}\)用于表示对经过实体\(e_i\)路径的影响,对于双线性模型:\(\Phi_{\pi}=W_{r_1}tanh(w_{e_1})...W_{r_n}tanh(w_{e_n})\)。用\(F_l(s,t)\)表示实体\(s\)和\(t\)之间长度为\(l\)的路径的加权和,则有:
其中,\(F_l{s,t}=\sum_{\pi \in P_l(s,t)}P(t|s,\pi)\Phi_{\pi}\),\(P_l(s,t)\)表示实体\(s\)和\(t\)之间长度为\(l\)的路径。
动态规划算法如下图所示:

笔者:本文针对以往融合路径信息的嵌入式表示方法的时间复杂度进行优化,并加入节点信息,旨在高效运算并融入更充分的信息。本文的方法ALL-PATH在时间和效果上优于之前的方法。本文的方法的实现基于的是双线性模型,这里应该只是示例,完全可以将双线性替换为其他模型,这种关系路径集成的思想可以应用于很多已有的嵌入式表示学习方法,所以本文的最大亮点应该在于动态规划的提出,用以高效的计算。
TransG : A Generative Model for Knowledge Graph Embedding
- 作者:Han Xiao, Minlie Huang, Xiaoyan Zhu
- 机构:Dept. of Computer Science and Technology, Tsinghua University
本文的任务为知识图谱表示学习,旨在将知识图谱映射到低维稠密的向量空间里。与以往研究工作不同,本文将目光聚焦于“多语义关系”,即同一名相的关系可能具有不同的语义含义,如对于关系“HasPart”,对于实体“桌子”和“桌腿”有这种关系,对于“英国”和“伦敦”也同样具有这样的关系,但二者所表达的含义却不尽相同。
不止于感性层面上,本文对TransE的知识图谱向量表示进行可视化(PCA降维):抽取四种不同关系,将具有给定关系的实体对向量相减(据TransE思想,可以得到关系的向量),将结果向量展示在二维空间里。理想情况下,对于每个关系应该只和一个簇对应,但真实的结果是每个关系不止一个簇,而是多个明显分开的簇。这也从另一个角度说明了关系的多语义性质。
针对这一问题,本文提出TransG模型,利用贝叶斯非参数无限混合嵌入式表示模型来生成关系的多语义表示。TransG可以自动发现关系的多语义簇,并且利用关系的混合语义对实体对进行翻译操作,以进行关系推理。
本文利用了两个重要的模型和算法,分别是贝叶斯非参数无限混合嵌入式表示模型和中餐馆过程算法。具体的实体与关系嵌入式表示生成过程如下:

通过该过程会获得初始化的实体与关系向量,三元组的打分函数为:
不同于以往的方法,本文对于关系的描绘更为细化,对于实体对,可以确切获得多语义关系的明确语义:
学习过程是是的正例的分数不断提高,负例的分数不断减少,最终获得实体与关系的表示。
笔者:本文的切入点是多语义关系存在于知识库中,而之前的模型没有考察并解决这一问题。本文使用非参数贝叶斯模型,借助CRP算法用于对关系多语义的识别与生成。本文主要的贡献在于提出了多语义关系的问题,并借助CRP解决这一问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号