
http://news.sohu.com/a/673735058_100110101
1 简介
Kafka 作为一个高吞吐的消息中间件,和传统的消息中间件一个很大的不同点就在于它的消息实际上是以日志的方式默认保存在/tmp/kafka-logs文件夹中的。
Kafka的持久化策略更像Redis——数据都在内存中,定期刷写到硬盘上持久化存储,以保证重启的时候数据不丢。
刷写策略由log.flush.*这些参数控制。
Kafka每个Topic可以存储于多个Partition,每个Partition在Kafka的log目录下表现为 topicname-id 这样的文件夹,如mytopic-0。Kafka队列中的内容会按照日志的形式持久化到硬盘上,每个日志文件称为”片段”(Segment)。
Kafka清理队列中过期消息的方式实际上就是删除过期的Segment,这种表现形式十分类似于日志滚动,因此控制Kafka队列中消息的保存时间的方式实际上就是日志文件定期分段,然后定期清理掉过期的段文件。
2 持久化的分段文件解析
每个Segment包含一个日志文件(.log后缀)和两个索引文件(.index和 .timeindex后缀)。
2.1 日志文件(log)
可以通过以下命令查看log文件中存放的是具体的每条消息
kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.log --print-data-log
其每条消息包含的内容如下

baseOffset:当前batch中第一条消息的位移。
lastOffset:最新消息的位移相对于第一条消息的唯一增量。
count:当前batch有的数据数量,kafka在进行消息遍历的时候,可以通过该字段快速的跳跃到下一个batch进行数据读取。
partitionLeaderEpoch:记录了当前消息所在分区的 leader 的服务器版本,主要用于进行一些数据版本的校验和转换工作。
crc:当前整个batch的数据crc校验码,主要用于对数据进行差错校验的。
compresscode:数据压缩格式,主要有GZIP、LZ4、Snappy三种。
Sequence、producerId、producerEpoch:这三个参数主要是为了实现事务和幂等性而使用的,其中producerId和producerEpoch用于确定当前 producer 是否合法,而起始序列号则主要用于进行消息的幂等校验。
isTransactional:是否开启事务。
magic:Kafka服务程序协议版本号。
CreateTime:数据创建的时间戳。
payload:实际存储的数据。
2.2 偏移量索引文件
使用kafka-run-class.sh kafka.tools.DumpLogSegments --files 00000000000000000000.index --print-data-log命令查看文件内容。

offset:这条数据在这个 Segment 文件中的位置,是这个文件的第几条。
position : 这条数据在 Segment 文件中的物理偏移量。
2.3 时间戳索引文件
查看文件的命令同偏移量索引文件查看命令。

timestamp:该日志段目前为止最大时间戳。
offset:记录的是插入新的索引条目时,当前消息的偏移量。
3 日志策略
3.1 分段策略属性

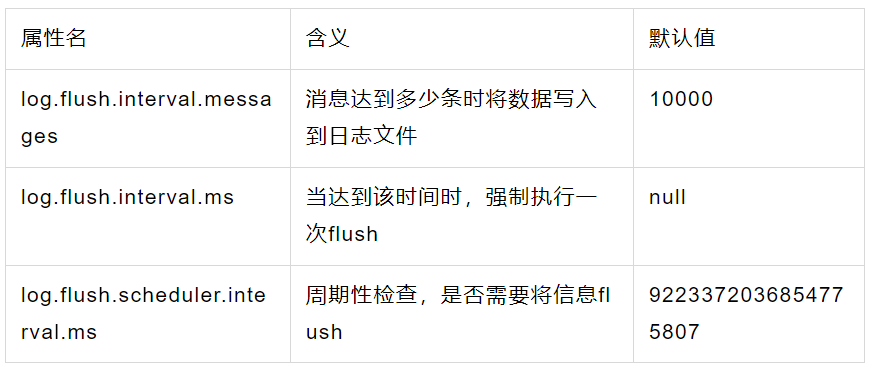
3.2 日志刷新策略
3.3 日志保存清理策略
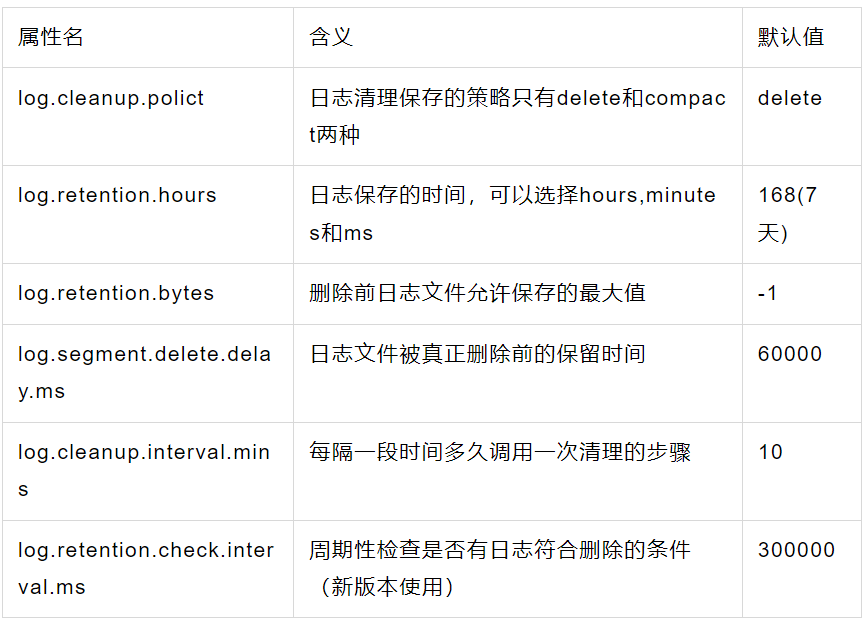
- 日志的真正清除时间。
- 当删除的条件满足以后,日志将被“删除”,但是这里的删除其实只是将该日志进行了“delete”标注,文件只是无法被索引到了而已。
- 但是文件本身,仍然是存在的,只有当过了log.segment.delete.delay.ms 这个时间以后,文件才会被真正的从文件系统中删除。
