手工不完全恢复
手工不完全恢复
1 基本概念
1.1 不完全恢复的特点
- 必须停机,在mount下运用重做日志
- 必须以sysdba身份连接进行不完全恢复
- 让整个database回到过去某个时间点,不能避免数据丢失
1.2 不完全恢复(Incomplete recover)适用环境
- 在过去的某个时间点重要的数据被破坏
- 最小化备份测试
- 在做完全恢复时,丢失了部分归档日志或当前online redo log(考点)
- 当误删除了表空间时(使用备份的控制文件)
1.3 不完全恢复的基本类型
- 基于时间点(until time) 使整个数据库恢复到过去的一个时间点前
- 基于scn(until change) 使整个数据库恢复到过去的某个SCN前
- 基于cancel(until cancel) 使整个数据库恢复到归档日志或当前日志的断点前(断档恢复)
- 基于误删除表空间(使用备份的controlfile) 使整个数据库恢复到误删除表空间前
2 不完全恢复的步骤
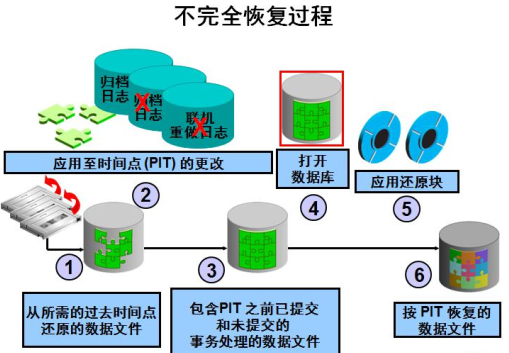
1)利用logminer工具,找出在某个时间点所作的DDL或DML误操作(包括:时间点、scn、sql语句)
2)做当前数据库的最新全备
3)使用还原点前的备份还原数据文件
4)运用日志恢复所有数据文件,前滚至需要的时间点前停止
5)使用resetlogs方式打开数据库
要执行用户管理的不完全恢复,请按以下步骤进行操作:
- 关闭数据库
- 还原数据文件
- 装载数据库
- 恢复数据库
- 使用RESETLOGS选项打开数据库
3 使用当前控制文件做不完全恢复【实验】
3.1 基于时间点的不完全恢复
恢复过去某个时间点误删除的table
3.1.1 环境准备
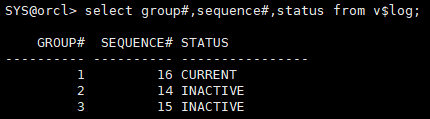
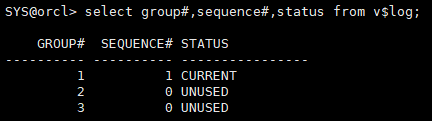
查看当前日志组
select group#,sequence#,status from v$log;
3.1.2 模拟误删除了test表,drop table purge
drop table test purge;

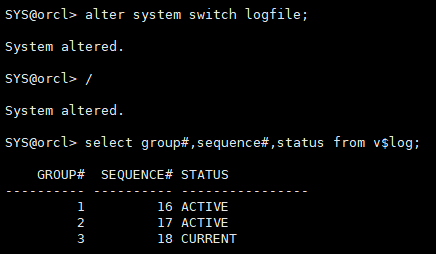
alter system switch logfile; / select group#,sequence#,status from v$log;
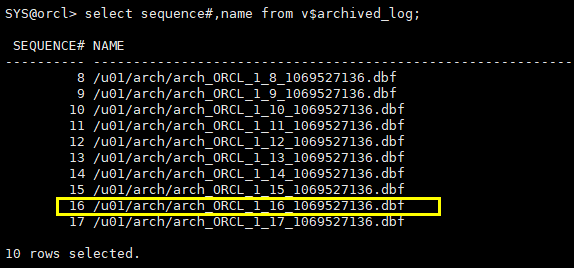
col name for a60 select sequence#,name from v$archived_log;
3.1.3 logmnr挖误操作时间(新方法)
通过logmr找出误操作的ddl命令的timestamp或scn,然后做不完全恢复
3.1.3.1 创建目录存放需要的数据字典信息
mkdir /u01/logmnr ls -ld /u01/logmnr/

CREATE DIRECTORY "dir" AS '/u01/logmnr';

3.1.3.2 添加database补充日志
如果不添加补充日志,最后查询结果的username字段会显示unknown或者为空值
alter database add supplemental log data;

3.1.3.3 通过logmnr包指定使用的目录
EXECUTE dbms_logmnr_d.build(dictionary_location=>'dir',dictionary_filename=>'dictionary.ora',options => dbms_logmnr_d.store_in_flat_file);

3.1.3.4 向logmnr工具添加分析的日志
第一次添加使用下面命令:
execute dbms_logmnr.add_logfile(logfilename=>'/u01/arch/arch_ORCL_1_16_1069527136.dbf',options=>dbms_logmnr.new)

注意:日志文件选择第一次切换日志生成的:/u01/arch/arch_ORCL_1_16_1069527136.dbf
第二次添加使用下面命令(此处只挖掘一个日志,故第二次不再执行,命令如下,修改日志文件名称即可):
exec dbms_logmnr.add_logfile(logfilename=>'/u01/arch/arch_ORCL_1_17_1069527136.dbf',options=>dbms_logmnr.addfile);
注意:不仅可以添加归档日志(select name from v$archived_log),也可以添加联机重做日志(online redo logfile,使用命令select member,type from v$logfile;查询)
3.1.3.5 启动logmnr工具分析日志
exec dbms_logmnr.start_logmnr(dictfilename=>'/u01/logmnr/dictionary.ora',options=>dbms_logmnr.ddl_dict_tracking);

3.1.3.6 查看日志挖掘的结果
select username,scn,to_char(timestamp,'yyyy-mm-dd hh24:mi:ss') time,sql_redo from v$logmnr_contents where lower(sql_redo) like 'drop table test%';

挖掘出来删除时候的scn号为2791824,时间为2021-06-07 16:17:42
3.1.3.7 结束日志挖掘
execute dbms_logmnr.end_logmnr;

3.1.4 关闭数据库,准备做不完全恢复
shutdown abort;
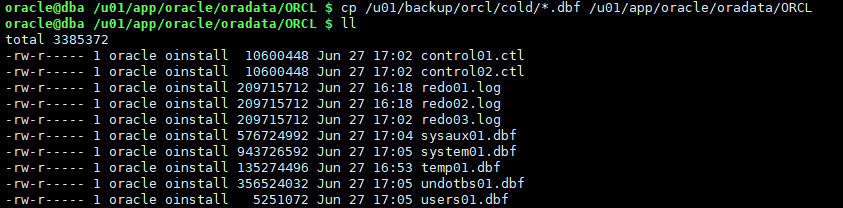
3.1.5 还原所有备份的数据文件
cp /u01/backup/orcl/cold/*.dbf /u01/app/oracle/oradata/ORCL ll /u01/app/oracle/oradata/ORCL
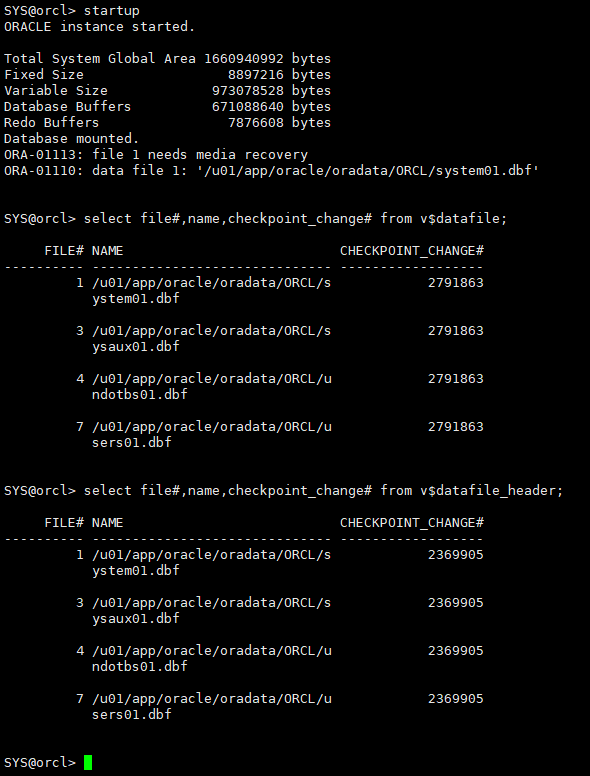
3.1.6 根据log miner提供的信息,做基于时间点(SCN)的不完全恢复
startup select file#,name,checkpoint_change# from v$datafile; select file#,name,checkpoint_change# from v$datafile_header;
前面挖掘出来的scn号为2791824,时间为2021-06-07 16:17:42
接下来开始恢复
recover database until change 2791824;
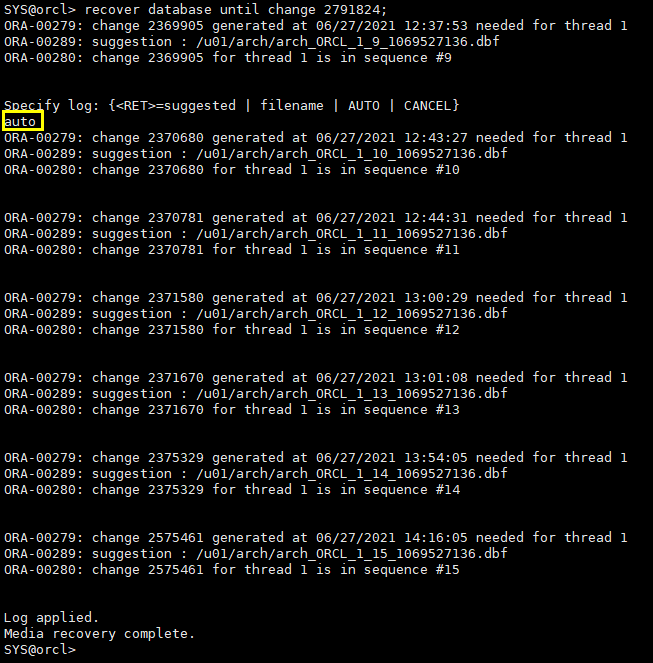
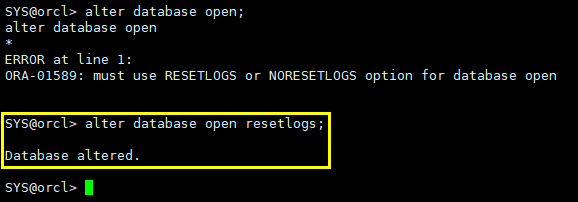
3.1.7 resetlogs方式打开数据库
alter database open; alter database open resetlogs;
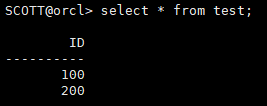
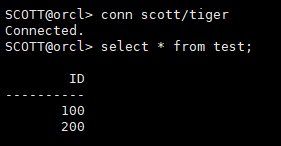
3.1.8 验证数据表
select * from test;
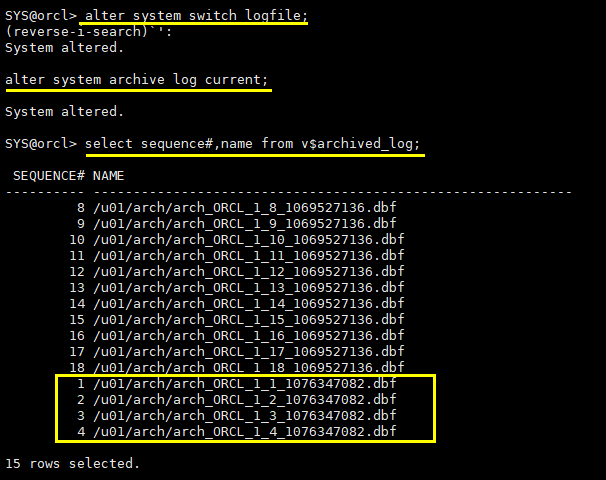
3.1.9 resetlogs后日志sequence重置
select group#,sequence#,status from v$log;
alter system switch logfile; alter system archive log current; select sequence#,name from v$archived_log;
3.2 基于取消的不完全恢复
当前日志组损坏,造成数据库崩溃
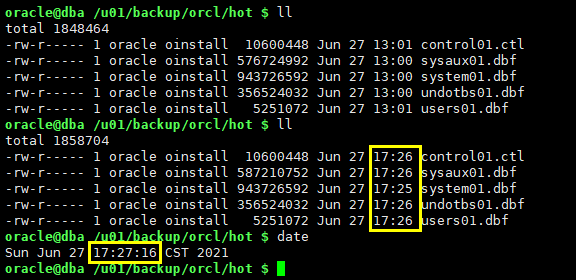
3.2.1 open resetlogs后做一次热备份备用
@/u01/backup/orcl/hot.sql
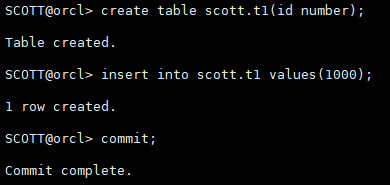
3.2.2 创建测试表
create table scott.t1(id number); insert into scott.t1 values(1000); commit;
alter system archive log current;

insert into scott.t1 values(2000); commit; select * from scott.t1;
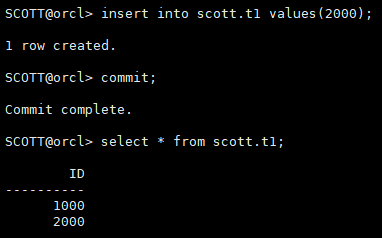
第一行对应日志已经归档,第二行对应日志在当前日志中,没有归档
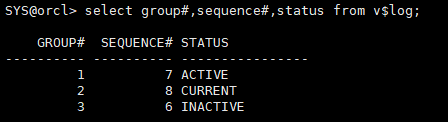
3.2.3 删除当前日志组,shutdown abort关库
select group#,sequence#,status from v$log;
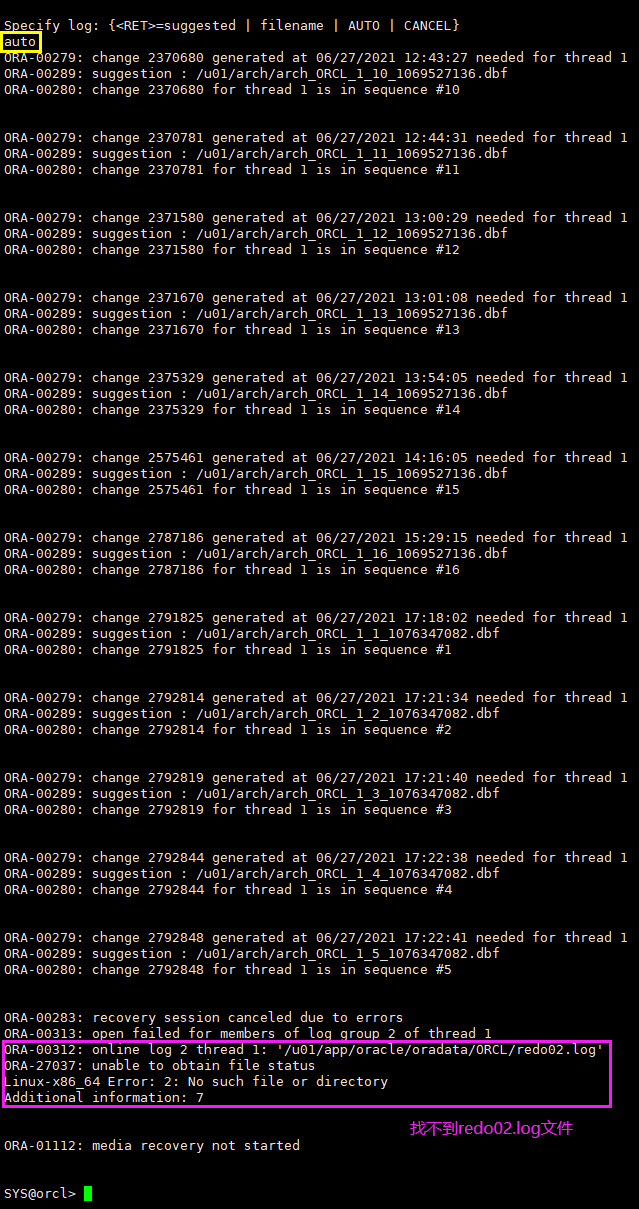
rm /u01/app/oracle/oradata/ORCL/redo02.log
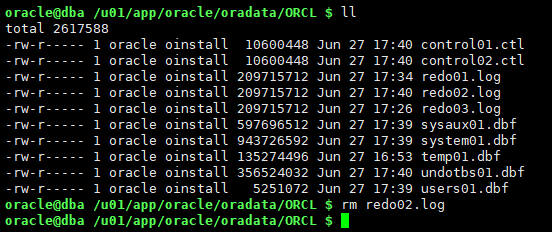
shutdown abort;
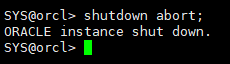
3.2.4 转储所有数据文件
cd /u01/app/oracle/oradata/ORCL cp /u01/backup/orcl/cold/*.dbf . ll
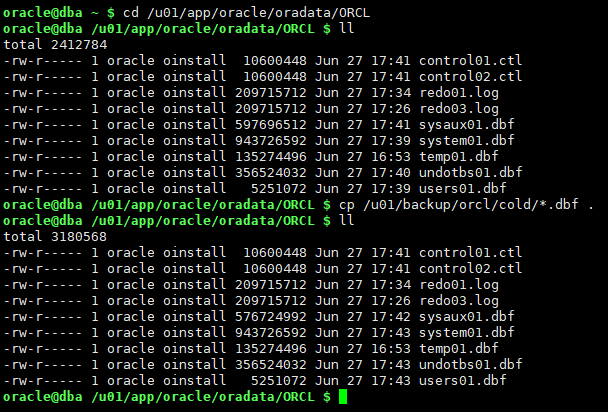
startup
3.2.5 recover database【报错】
redo丢失,报错无法恢复
recover database
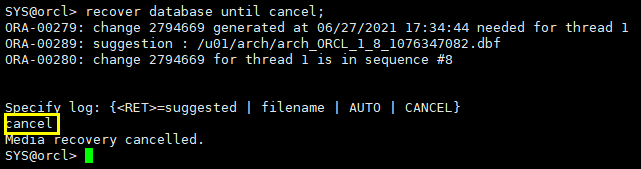
3.2.6 recover database until cancel
recover database until cancel;
3.2.7 open resetlogs开库
alter database open resetlogs;

3.2.8 验证表数据
select * from scott.t1;
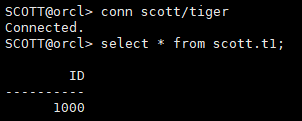
注意:虽然第二次插入数据(ID=2000)也进行了commit,但是未切换日志,而且正好redo02日志文件丢失,数据也丢失,只能恢复到这个阶段(不完全恢复)
4 使用备份的控制文件做不完全恢复【实验】
4.1 当前控制文件丢失、使用冷备恢复
4.1.1 环境准备:冷备数据库
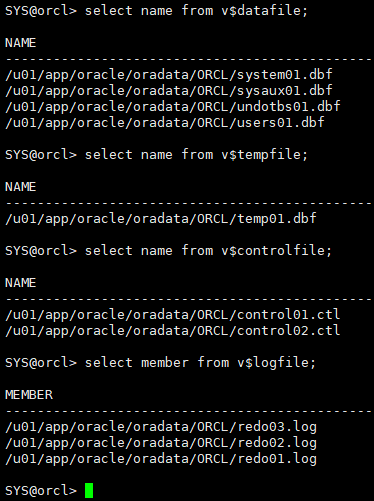
清理表空间,手工做冷备
select name from v$datafile; select name from v$tempfile; select name from v$controlfile; select member from v$logfile;
正常关库
shutdown immediate
备份数据文件、控制文件
cd /u01/app/oracle/oradata/ORCL/ cp *.dbf /u01/backup/orcl/cold cp *.ctl /u01/backup/orcl/cold

备份参数文件、密码文件
cd $ORACLE_HOME/dbs cp orapworcl /u01/backup/orcl/cold cp spfileorcl.ora /u01/backup/orcl/cold

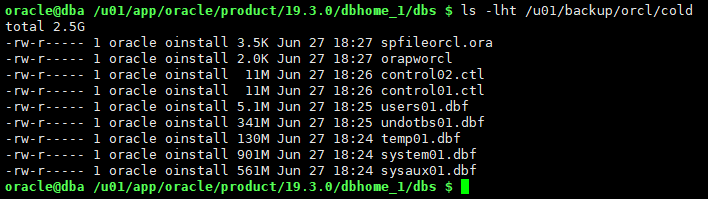
查看备份文件
ls -lht /u01/backup/orcl/cold
4.1.2 开库,模拟备份后续事务操作
开库、创建表、第一次插入数据、提交、切日志组
startup drop table scott.test purge; create table scott.test as select * from scott.emp; insert into scott.test select * from scott.emp; commit; select count(*) from scott.test; alter system switch logfile;
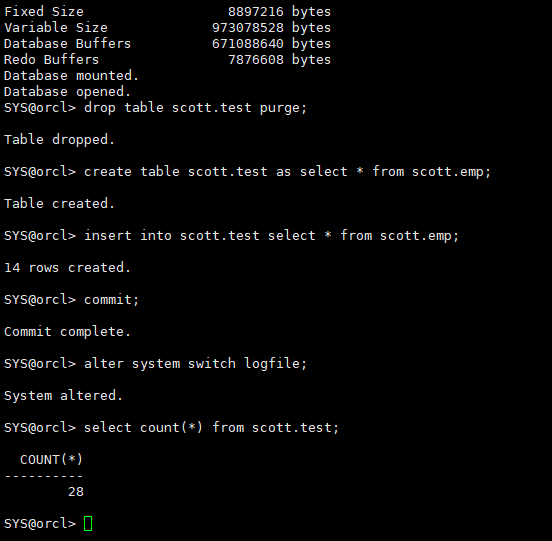
第二次插入数据,提交,不切日志组
insert into scott.test select * from scott.emp; commit; select count(*) from scott.test;
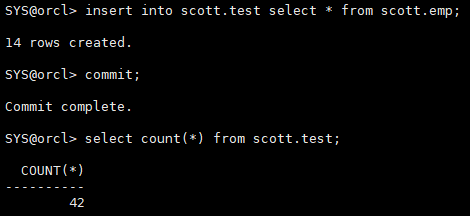
第三次插入数据,不提交,模拟实例崩溃
insert into scott.test select * from scott.emp; select count(*) from scott.test; shutdown abort;
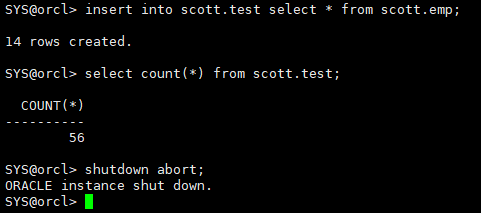
4.1.3 mv日志文件备用(模拟日志文件丢失。为了后面模拟归档文件、日志组文件未损坏时进行完全恢复)
cd /u01/app/oracle/oradata/ORCL/ mv redo01.log redo01.log.bak mv redo02.log redo02.log.bak mv redo03.log redo03.log.bak

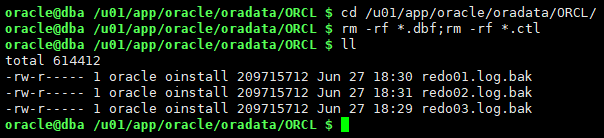
4.1.4 模拟介质故障,删除所有数据文件、控制文件,日志文件已丢失
cd /u01/app/oracle/oradata/ORCL/ rm -rf *.dbf;rm -rf *.ctl ll
如果参数文件、密码文件损坏,可以利用备份恢复,若备份中没有,可以重建密码文件、参数文件
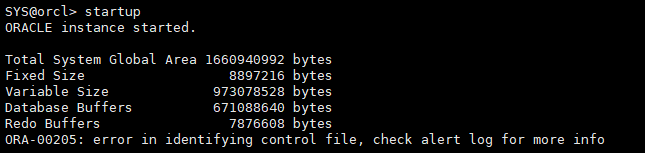
启动数据库实例报错
startup
4.1.5 转储(还原)控制文件、数据文件
cd /u01/backup/orcl/cold cp *.ctl /u01/app/oracle/oradata/ORCL/ cp *.dbf /u01/app/oracle/oradata/ORCL/

alter database mount; select file#,checkpoint_change#,last_change# from v$datafile; select file#,checkpoint_change# from v$datafile_header;
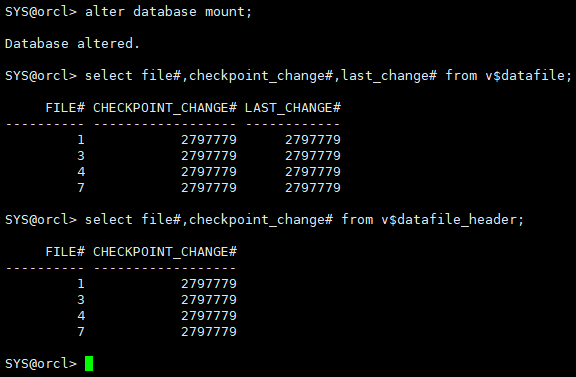
由于还原使用的是冷备(一致性备份)的数据文件和控制文件,这种状态下是可以open开库的,但开库只能回到备份时的状态,缺少了recover利用日志进行恢复的步骤
4.1.6 read only开库查看
alter database open read only; select count(*) from scott.test;
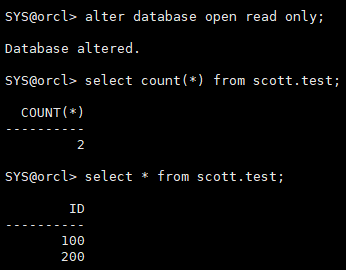
缺少利用日志recover恢复的过程,备份之前有2行数据,但是备份之后的事务数据丢失
关库,重新启动到mount状态
shutdown immediate; startup mount;
4.1.7 使用旧的控制文件进行恢复
recover database using backup controlfile;
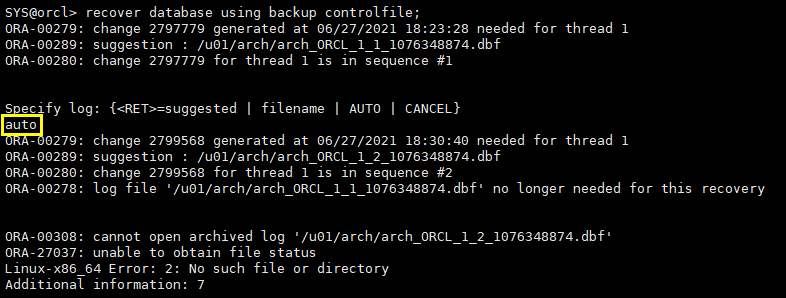
recover database using backup controlfile until cancel; alter database open resetlogs;
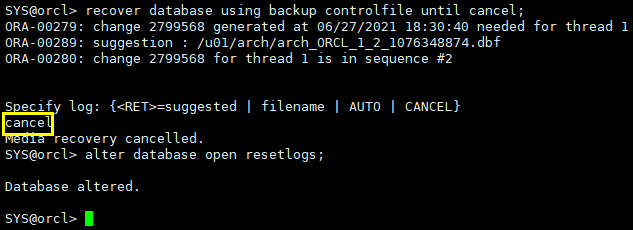
由于当前日志文件损坏,使用旧的控制文件做基于取消的不完全恢复
select count(*) from scott.test;
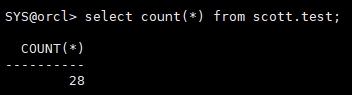
第二次、第三次插入操作已经提交,但对应日志在当前日志组中的数据丢失
4.1.8 模拟归档日志文件、redo日志文件均未损坏
shutdown abort;
cd /u01/app/oracle/oradata/ORCL/ rm *.ctl;rm *.dbf;rm *.log
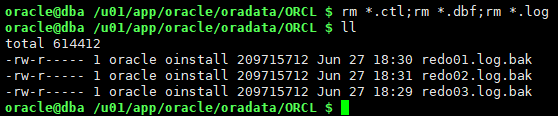
mv redo01.log.bak redo01.log mv redo02.log.bak redo02.log mv redo03.log.bak redo03.log
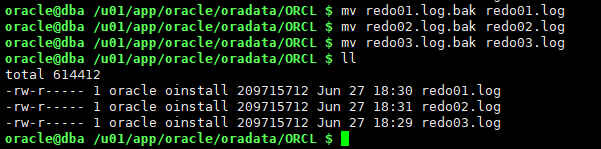
这些是shutdown abort时的日志组文件,包含了插入并提交数据后42行状态的当前日志组
4.1.9 转储数据文件、控制文件
cd /u01/backup/orcl/cold cp -p *.ctl /u01/app/oracle/oradata/ORCL/ cp -p *.dbf /u01/app/oracle/oradata/ORCL/ ls -lht /u01/app/oracle/oradata/ORCL/

数据文件和控制文件是备份时的,redo日志文件是实例崩溃时的
4.1.10 利用旧的控制文件进行恢复
startup mount; select file#,checkpoint_change#,last_change# from v$datafile; select file#,checkpoint_change# from v$datafile_header;
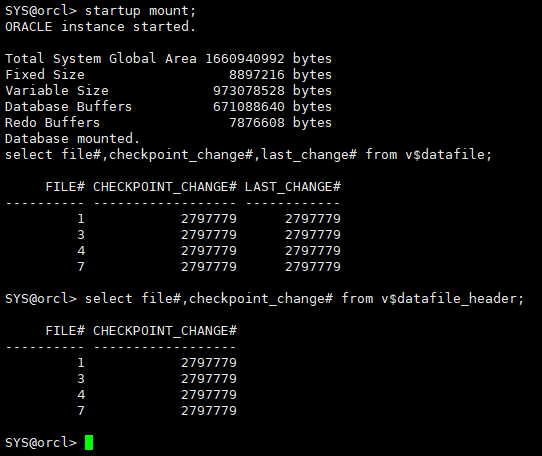
recover database using backup controlfile;
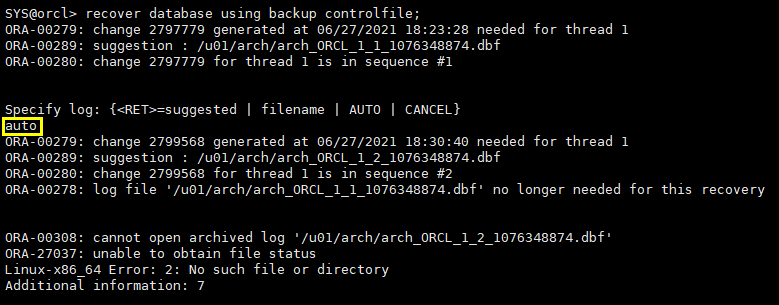
利用归档日志进行了recover
继续追加redo日志组文件
select member from v$logfile;
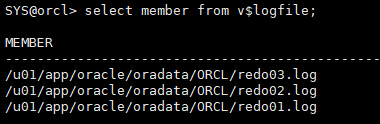
recover database using backup controlfile; recover database using backup controlfile; recover database using backup controlfile;
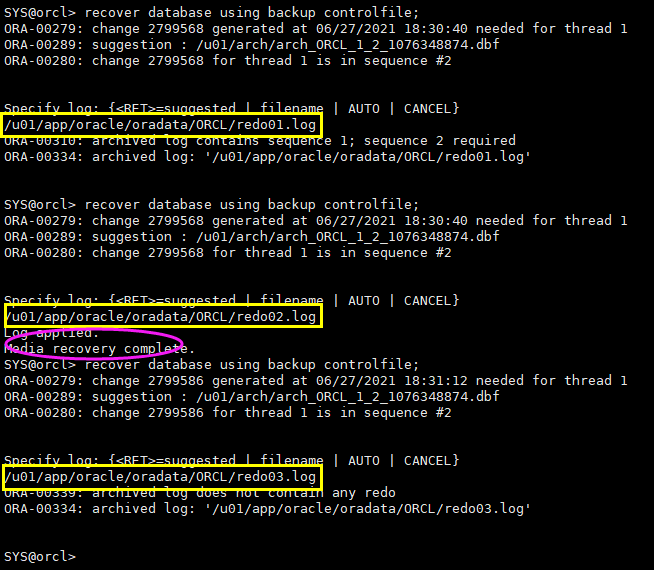
select file#,checkpoint_change#,last_change# from v$datafile; select file#,checkpoint_change# from v$datafile_header;
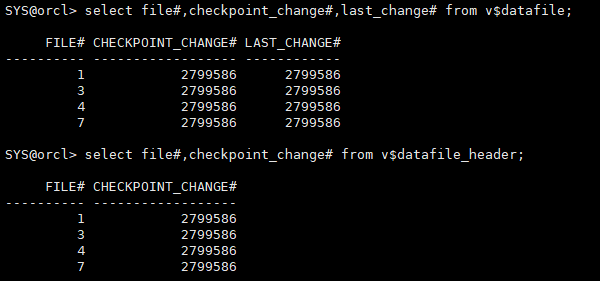
由于归档日志连续,redo日志文件正常,从备份到实例崩溃之前所有日志均存在最终利用旧的控制文件(备份中的)进行了完全恢复
alter database open resetlogs; select count(*) from scott.test;
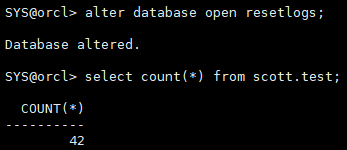
第二次插入数据操作提交,数据为42行,第三次插入数据操作未提交,故操作已回滚
归档日志连续、当前日志组文件正常,最终实现完全恢复,保证commit的数据没有丢失
4.2 利用旧控制文件和备份恢复新建的表空间
4.2.1 环境准备,利用tar命令打包冷备数据库
shutdown immediate;
cd /u01/app/oracle/oradata/ORCL/ cp *.dbf /u01/backup/orcl/cold cp *.ctl /u01/backup/orcl/cold cd $ORACLE_HOME/dbs cp orapworcl /u01/backup/orcl/cold cp spfileorcl.ora /u01/backup/orcl/cold ll /u01/backup/orcl/cold

使用tar命令打包备份数据文件、控制文件、参数文件、密码文件
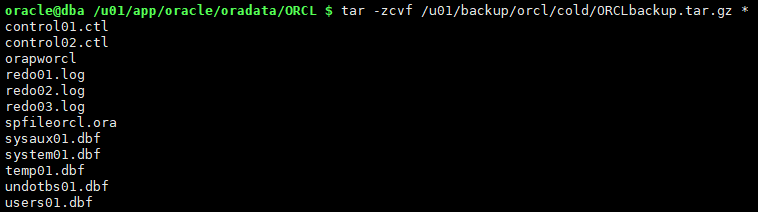
tar -zcvf /u01/backup/orcl/cold/ORCLbackup.tar.gz *
4.2.2 模拟备份后新建表空间、事务操作
起库
第一次:建表,切日志组
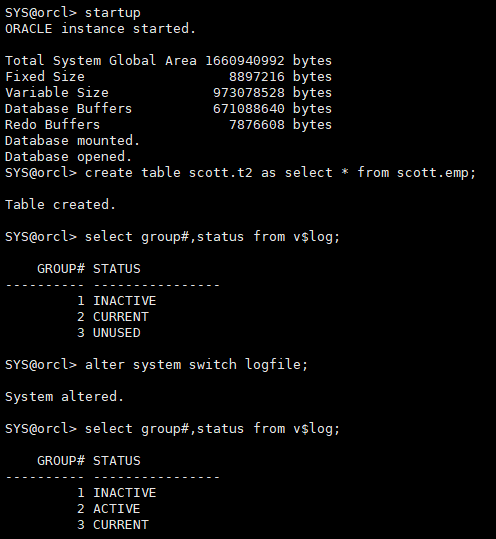
startup create table scott.t2 as select * from scott.emp; select group#,status from v$log; alter system switch logfile;
第二次:创建表空间,创建表,切日志组
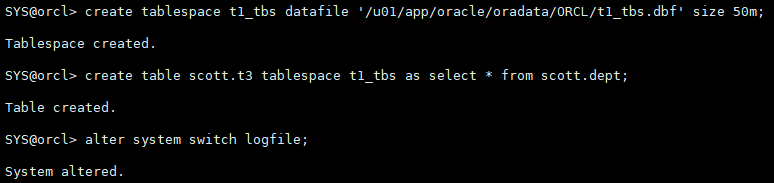
create tablespace t1_tbs datafile '/u01/app/oracle/oradata/ORCL/t1_tbs.dbf' size 50m; create table scott.t3 tablespace t1_tbs as select * from scott.dept; alter system switch logfile;
第三次:建表,切日志组,插入数据,提交,不切日志组
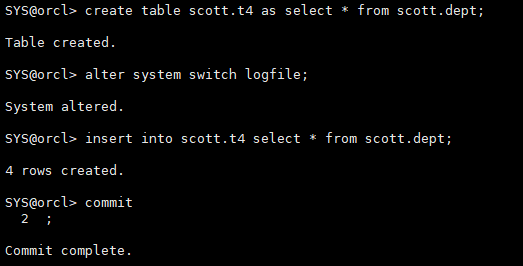
create table scott.t4 as select * from scott.dept; alter system switch logfile; insert into scott.t4 select * from scott.dept; commit;
select count(*) from scott.t2; select count(*) from scott.t3; select count(*) from scott.t4;

4.2.3 模拟实例崩溃,删除所有数据文件、控制文件、日志文件
关库、删除文件
shutdown immediate
cd /u01/app/oracle/oradata/ORCL/ rm -rf * ll
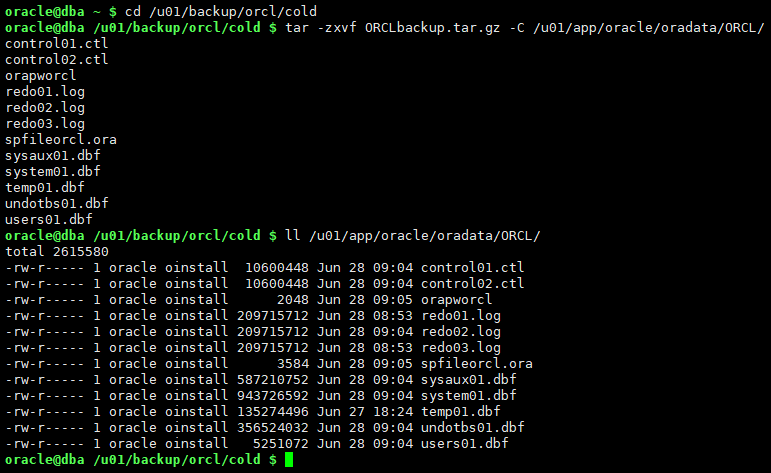
4.2.4 tar解包转储数据文件、控制文件
cd /u01/backup/orcl/cold tar -zxvf ORCLbackup.tar.gz -C /u01/app/oracle/oradata/ORCL/ ll /u01/app/oracle/oradata/ORCL/
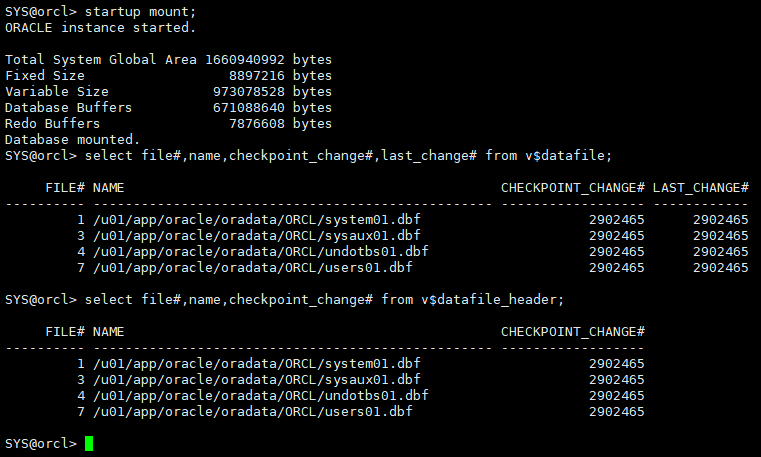
4.2.5 mount状态查看
startup mount; select file#,name,checkpoint_change#,last_change# from v$datafile; select file#,name,checkpoint_change# from v$datafile_header;
4.2.6 使用旧的控制文件做基于取消的不完全恢复
recover database using backup controlfile until cancel;
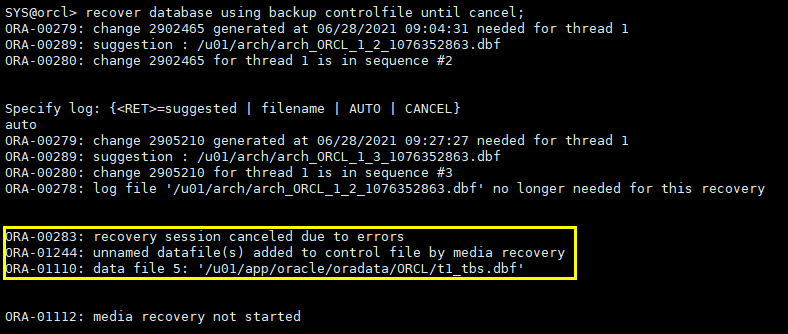
提示找不到数据文件t1_tbs.dbf
col name for a60 select file#,checkpoint_change#,last_change#,name from v$datafile; select file#,checkpoint_change#,name from v$datafile_header;
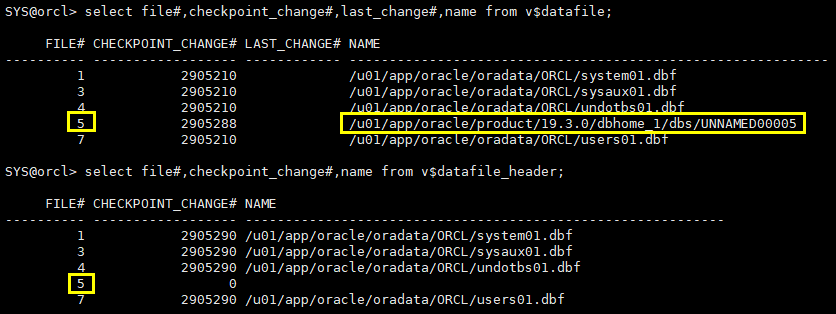
4.2.7 创建空数据文件
alter database create datafile '/u01/app/oracle/product/19.3.0/dbhome_1/dbs/UNNAMED00005' as '/u01/app/oracle/oradata/ORCL/t1_tbs.dbf';

ll /u01/app/oracle/oradata/ORCL/
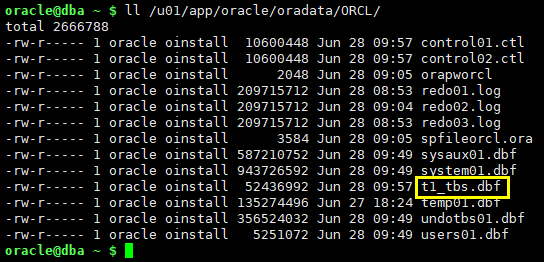
select file#,checkpoint_change#,last_change#,name from v$datafile; select file#,checkpoint_change#,name from v$datafile_header;
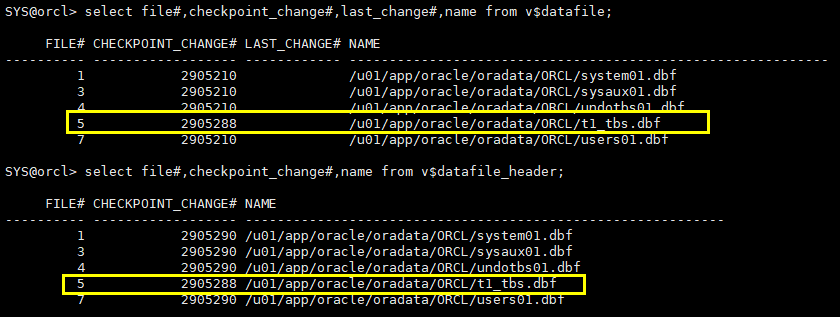
4.2.8 recover database
recover database using backup controlfile until cancel; recover database using backup controlfile until cancel;
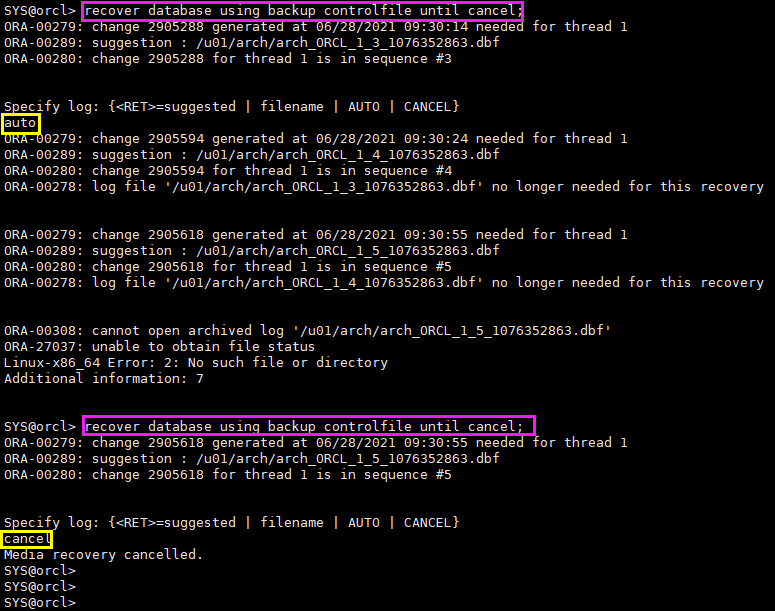
alter database open resetlogs;

4.2.9 验证表数据
select count(*) from scott.t2; select count(*) from scott.t3; select count(*) from scott.t4;
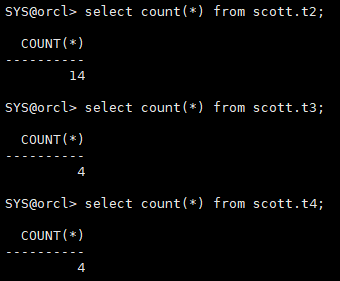
不完全恢复智能回复到切换日志之前

 浙公网安备 33010602011771号
浙公网安备 33010602011771号