oracle体系架构
oracle体系架构
1 【memory structures】内存结构
Fixed SGA:一个内部管理区域,包含关于数据库和实例状态的一般信息,以及进程之间通信的信息
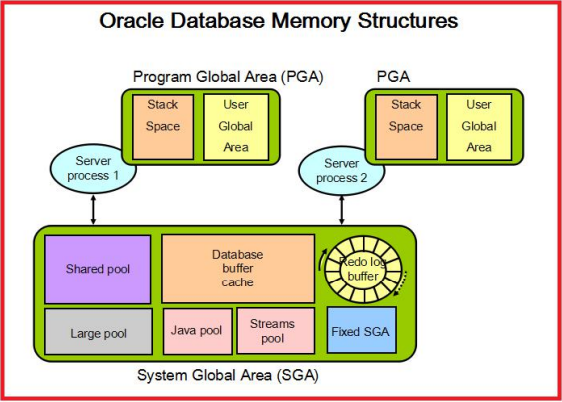
oracle memory = SGA + PGA
SGA:system global area 系统全局区,共享的,所有server process和background process共享
PGA:program global area 程序全局区,私有的,每一个server process和background process拥有自己的pga
1.1 SGA 系统全局区
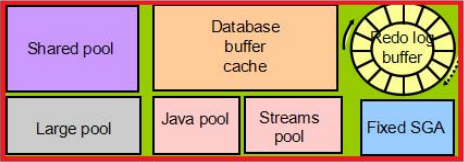
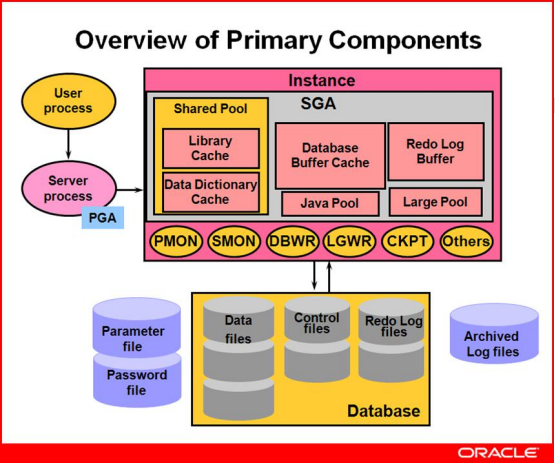
系统全局区(System Global Area)简称SGA,被所有server process和background process共享的内存区域,随着实例的启动而分配,一个实例只有一个SGA,共享给所有会话使用
SGA6个基本组件:
shared pool、database buffer cache、redo log buffer、large pool、java pool、streams pool
共享池 数据缓冲区 日志缓冲区 大池 java池 流池
1.1.1 shared pool共享池
共享池是对SQL、PL/SQL 程序进行语法分析、编译、执行的内存区域
共享池由库缓存(library cache)、数据字典缓存(data dictionary cache)、结果缓存 (result cache)等组成
共享池的大小直接影响数据库的性能
1.1.2 database buffer cache数据缓冲区
数据缓冲区(database buffer cache)也称buffer cache
功能:
① 缓存数据
用于缓存从磁盘数据文件中读入的数据块,为所有用户共享
服务器进程(server process)负责将数据文件的数据从磁盘读入到数据缓冲区中,当后续的请求需要这些数据时,如果在内存中找到,则不需要再从磁盘读取
② 延迟写数据文件
对数据的修改在内存缓冲区中进行,减少写磁盘的次数,提高I/O能力
数据缓冲区中被修改的数据块(脏块dirty block)由后台进程DBWR将其写入磁盘
数据缓冲区的大小对数据库的读取速度有直接的影响
1.1.3 redo log buffer日志缓冲区
功能:
执行DML、DDL操作时,产生对数据修改的变更向量(db buffer cache 中数据块变化),目的是为了数据库恢复recover
服务器进程server process 将对应的变更向量(change vector,CV)记录到redo log buffer中
日志条目(redo entries)记的不是sql本身,而是sql执行后对数据库中某个文件某个块做了什么修改(变更向量)
没commit的sql也记redo日志
执行commit命令后看到"commit complete",说明日子已经从日志缓冲区(redo log buffer)写入到联机日志文件(online redo log file),由后台进程LGWR负责写
1.1.4 large pool大池(可选)
为了进行大的后台进程操作而分配的内存空间,与shared pool管理不同,主要用于共享服务器模式的session memory(UGA)、RMAN备份恢复以及并行查询等操作。在共享模式下如果没有分配,large pool会占用shared pool空间
Oracle XA interface用于事务与多个数据库之间的交互
1.1.5 java pool java池(可选)
为java命令以及应用而分配的内存空间,包含所有session的JVM中JAVA代码和数据。可以通过不同的方式使用,取决于数据库当前运行的模式
1.1.6 streams pool流池(可选)
为了stream process而分配的内存空间
stream技术是为了在不同数据库之间共享数据,因此,streams pool对使用了stream数据库特性的系统是重要的
1.2 PGA 程序全局区
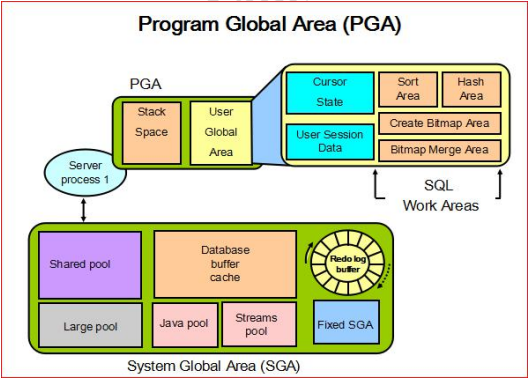
程序全局区(Program Global Area)简称PGA,主要用来缓存oracle服务器进程和后台进程的数据和控制信息,提供排序、hash连接。PGA在进程创建时被分配,进程终止时被释放
PGA是私有的,每一个server process和background process有自己的PGA
所有进程的PGA之和构成了PGA的总大小
pga_aggregate_target:PGA累计的最大值PGA的管理是比较复杂的,10g后Oracle推荐使用PGA自动管理,屏蔽了PGA的复杂性
专用服务器模式PGA组成:
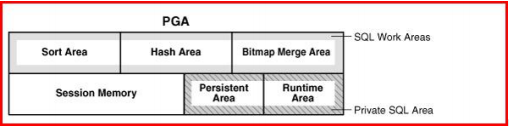
1)SQL 工作区(SQL Work Area):有几个子区Sort Area、Hash Area、Bitmap Merge Area
作用:排序操作(order by/group by/distinct/union 等),多表hash连接,位图连接,创建位图等
2)会话空间(Session Memory)
作用:存放 logon 信息等会话相关的控制信息
3)私有SQL区域(Private SQL Area)
作用:存储 server process执行SQL所需要的私有数据和控制结构,如绑定变量等。它包括固定区域和运行时区域
1.3 UGA 用户全局区
用户全局区(User Global Area)简称UGA,存放与用户会话相关信息,如登录信息、会话状态等
专用服务器模式下,UGA在PGA中;
共享服务器模式下,UGA在SGA 中大池(large pool),没有大池在共享池(shared pool)中
1.4 PGA和SGA的区别(理解)
PGA(程序缓存区)与SGA(系统全局区)类似,都是Oracle数据库系统为会话在服务器内存中分配的区域。不过两者的作用不同,共享程度也不同。SGA系统全局区顾名思义,是对系统内的所有进程都是共享的。当多个用户同时连接到一个例程时,所有的用户进程、服务进程都可以共享使用这个SGA区。为此这个SGA的主要用途就是为不同用户之间的进程与服务进程提供一个交流的平台。除了这个作用,另外有一个重要的作用就是各种数据库的操作也是在这个SGA区内完成的
而PGA程序缓冲区则主要是为了某个用户进程所服务的。这个内存区不是共享的,只有这个用户的服务进程本身才能够访问它自己的PGA区。做个形象的比喻,SGA就好像是操作系统上的一个共享文件夹,不同用户可以以此为平台进行数据方面的交流。而PGA就好像是操作系统上的一个私有文件夹,只有这个文件夹的所有者才能够进行访问,其他用户都不能够访问。虽然程序缓存区不像其他用户的进程开放,但是这个内存区仍然肩负着一些重要的使命,如数据排序、权限控制等等都离不开这个内存区
2 【process structures】进程结构

2.1 user process用户进程
user process:属于客户端的process,用来运行客户端的应用
登录数据库分为三种形式:
- sql*plus
- 应用程序:应用程序请求访问 Oracle 服务器
- web方式(OEM):使用OEM通过web方式登录、管理数据库。
2.2 server process服务进程
user process不能直接访问oracle,必须通过server process(前台进程),server process用来处理连接到实例的用户进程(user process)的请求。用户端连接到数据库时,oracle会创建一个服务器进程(server process),客户端通过和该进程通信完成SQL的执行
server process作用:
- 负责user process和实例之间的通信
- 调用cpu解析并执行sql、plsql语句,包括创建并执行执行计划(query plan)
- 读取sql数据修改database buffer cache中数据,如果缓存中没有,就从数据文件data files读取数据块到数据缓冲区database buffer cache
- 将对数据块修改的变更向量写成日志,记录到日志缓冲区redo log buffer
- 将结果返回给应用程序
2.3 连接和会话connection and session
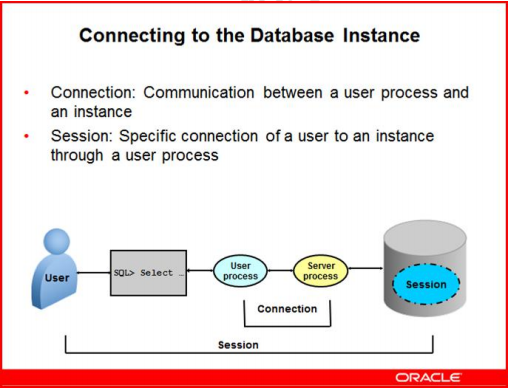
连接:connection指user process和oracle instance之间物理通信路径。通常是在user process和server process之间建立(dedicated server process 或 dispatcher)
会话:session指oracle实例内存中的一种逻辑实体,客户进程可以在会话上执行sql
基于一个连接connection,可以存在零个或多个会话session,各个会话之间是独立的,一个会话中的提交不会影响该连接上其他会话
2.4 专用连接模式dedicated和共享连接模式shared
server process连接server的时候有两种模式:
2.4.1 专用服务器模式
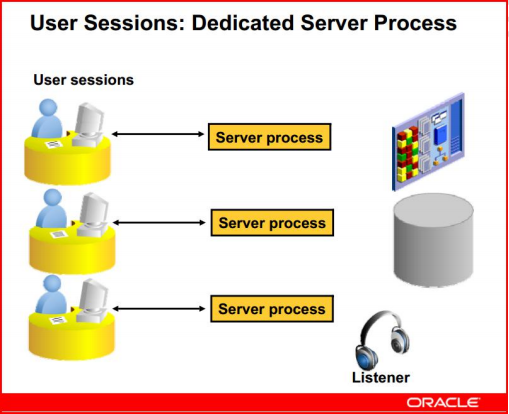
专用模式dedicated server process:user process与server process之间一对一的关系
对于客户端的每个user process,服务器端都会出现一个server process,会话与专用服务器之间存在一对一的映射
对专用连接来说,用户在客户端启动了一个应用程序,例如sql*plus,就是在客户端启动一个用户进程;与oracle服务器端连接成功后,会在服务器端生成一个服务器进程,该服务器进程作为用户进程的代理进程,代替客户端执行各种命令并把结果返回给客户端。用户进程一旦中止,与之对应的服务器进程立刻中止
专用连接的UGA在PGA中,Oracle缺省采用专用连接模式
2.4.2 共享服务器模式
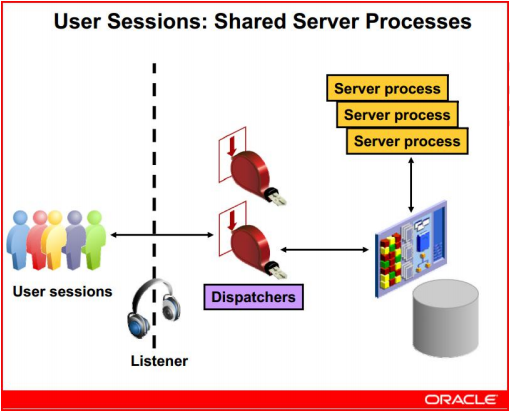
共享模式shared server process:user process与server process之间多对一的关系
多个user process共享一个server process。它通过调度进程(dispatcher)与共享服务器连接,共享服务器实际上就是一种连接池机制(connection pooling),连接池可以重用已有的超时连接,服务于其它活动会话。但容易产生锁等待。此种连接方式现在已经很少见了
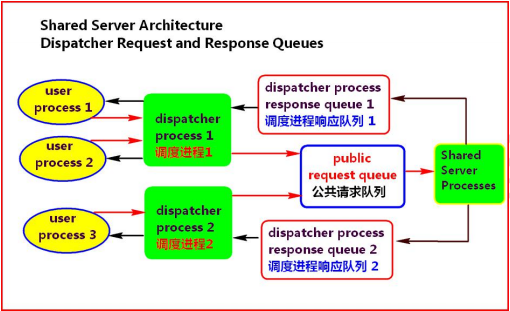
- 所有调度进程(dispatcher)共享一个公共的请求队列(resquest queue),但是每个调度进程都有自己的响应队列(response queue)
- 在共享服务器中会话信息存储在是在SGA中的(UGA),而不像专用连接那样在PGA中存储信息
- 会话与调度进程的连接在会话期间持久存在,而与监听程序 listener 的连接是短暂的
3 【storage structures】存储结构
3.1 物理存储结构

3.2 逻辑存储结构
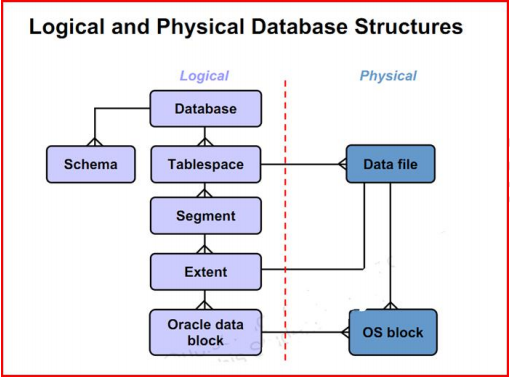
将逻辑存储与物理存储分开是关系数据库范例的要求之一。oracle数据库的数据的处理发生在instance(内存)中,但数据的存储发生在磁盘的database上。oracle数据库逻辑存储结构可分为数据库、表空间、段、区、块几个层次
database tablespace segment extent block
3.2.1 表空间和数据文件
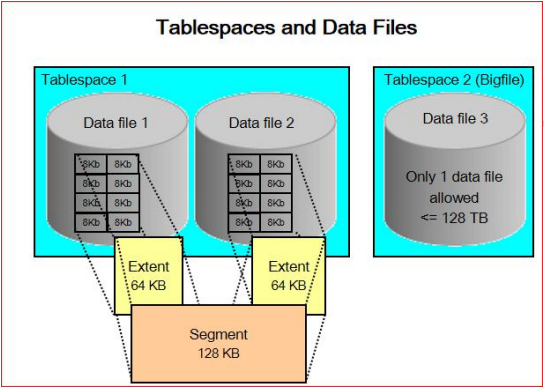

数据在物理上是存储在数据文件(data files)上,从逻辑上看数据存储在段(通常是表)中。 表空间是二者的抽象,是一个逻辑的概念
早期数据库中表、索引等对象(段)和文件(data file)之间是一对一的关系,缺点是当表比较多时,不便于系统管理员管理,再就是单个表的大小会受到操作系统单个文件最大大小的限制
表空间的使用解决了这个问题,消除了段和数据文件之间多对多的关系,一个表空间可能包含多个段(对象),并由多个数据文件组成。但一个数据文件只能对应一个表空间
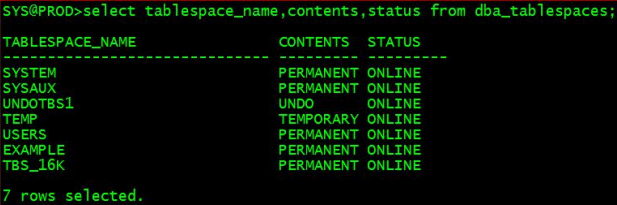
查看表空间信息
select tablespace_name,contents,status from dba_tablespaces;
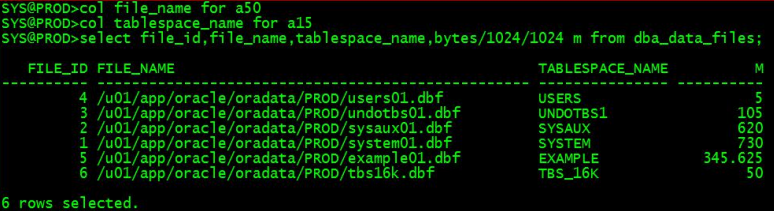
查看表空间对应数据文件
col file_name for a50
col tablespace_name for a15
select file_id,file_name,tablespace_name,bytes/1024/1024 m from dba_data_files;
3.2.2 段(segment)、区(extent)、块(block)
3.2.2.1 段(segment)
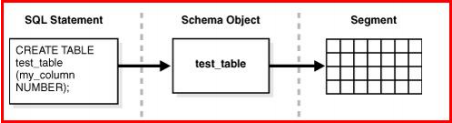
段是表空间中存储数据的数据库对象。表是典型的段,还有其他段类型比如索引段、undo段。任何一个段可以仅存在于一个表空间中,但表空间可以由多个数据文件组成。这样表的大小就不再受单个数据文件大小限制
段是模式对象,由具体某一个用户(模式)限定
注意:PL/SQL过程、视图、序列不是段,它们不存储数据,存在于数据字典中
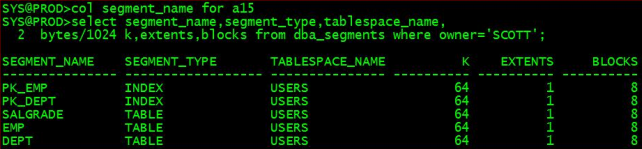
col segment_name for a15
select segment_name,segment_type,tablespace_name,bytes/1024 k,extents,blocks
from dba_segments where owner='SCOTT';
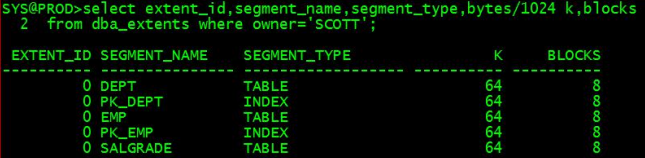
3.2.2.2 区(extent)
区是oracle空间分配的基本单元。区是一组连续编号的oracle块。这些区可能位于构成表空间的一个或多个数据文件中
select extent_id,segment_name,segment_type,bytes/1024 k,blocks from dba_extents where owner='SCOTT';
3.2.2.3 块(block)
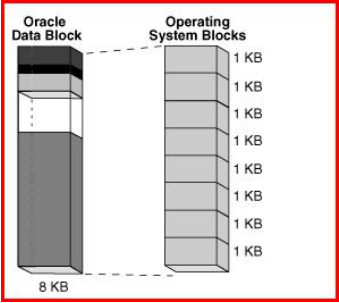
oracle块是数据库I/O的基本单位。数据文件设置为连续编号的oracle块
一个块中可能有多个行,但当会话需要某行数据时,是从磁盘将整个块读入到数据缓冲区。同样,dbwr写脏块时也是把整个块写入数据文件。
对表空间来说,块大小是固定不变的。11g默认标准块大小是8KB,在创建数据库时确定db_block_size参数,不能修改
从物理上讲,数据文件由操作系统块组成,操作系统块是文件系统I/O的基本单位。通常oracle块和操作系统块是一对多的关系,比如上图,oracle块是8KB,操作系统块大小是1KB
show parameter db_block_size

附:理解oracle体系
数据、重做日志写过程,归档日志生成过程:
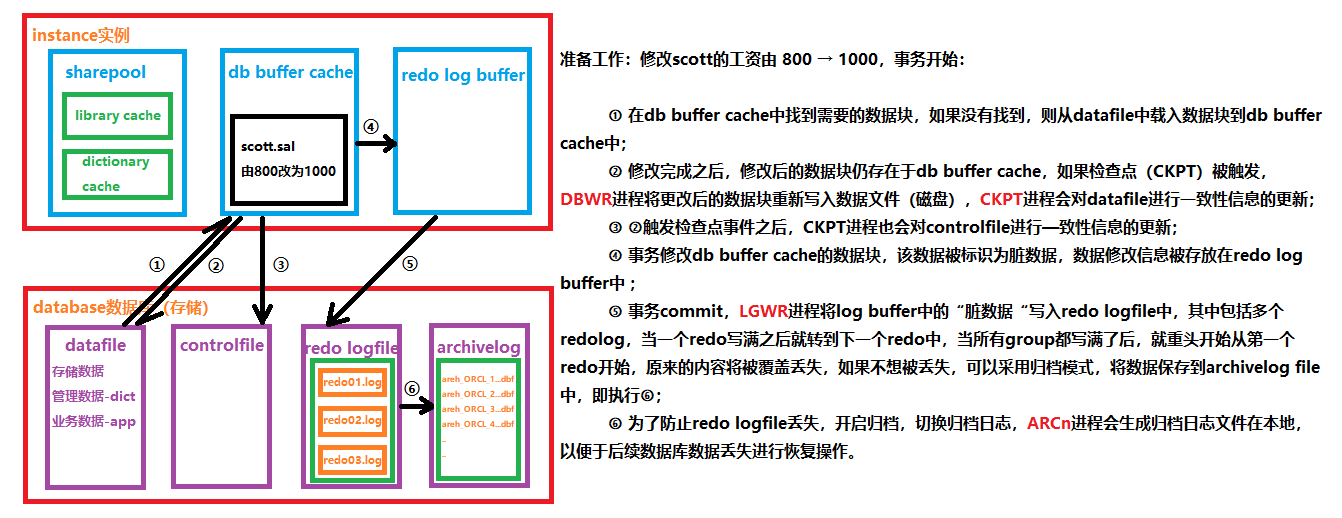
准备工作:修改scott的工资由 800 → 1000,事务开始:
① 在db buffer cache中找到需要的数据块,如果没有找到,则从datafile中载入数据块到db buffer cache中;
② 修改完成之后,修改后的数据块仍存在于db buffer cache,如果检查点(CKPT)被触发,DBWR/DBWn进程将更改后的数据块重新写入数据文件(磁盘),CKPT进程会对datafile进行一致性信息的更新,更新datafile的文件头中的信息;
③ ②触发检查点事件之后,CKPT进程也会对controlfile进行—致性信息的更新,即更新controlfile的文件头中的信息;
④ 事务修改db buffer cache的数据块,该数据被标识为脏数据,数据修改信息(脏数据)被存放在redo log buffer中;
⑤ 事务commit,LGWR进程将log buffer中的“脏数据“写入redo logfile中,其中包括多个redolog,当一个redo写满之后就转到下一个redo中,当所有group都写满了后,就重头开始从第一个redo开始,原来的内容将被覆盖丢失,如果不想被丢失,可以采用归档模式,将数据保存到archivelog file中,即执行⑥;
⑥ 为了防止redo logfile丢失,开启归档,切换归档日志,ARCn进程会生成归档日志文件在本地,以便于后续数据库数据丢失进行恢复操作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号