索引Index
索引Index
1 索引Index
索引:
- 是一个方案对象
- 通过指针加速Oracle服务器的查询速度
- 通过使用快速路径访问方法来快速定位数据,可以减少磁盘I/O索引与表相互独立
- Oracle服务器自动使用和维护索引
索引与优化调优非常密切
2 创建索引
在一个或者多个字段上创建索引:

提高对employees表中last_name列的查询访问速度:

create index emp_ename_idx on emp(ename);

3 B-tree索引的结构
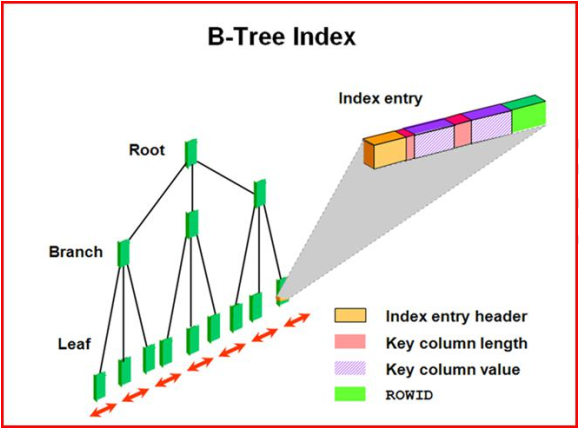
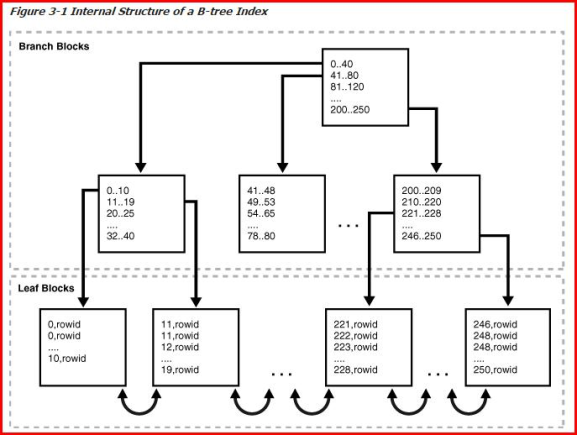
3.1 索引里的内容
列的值 (键值) + rowid
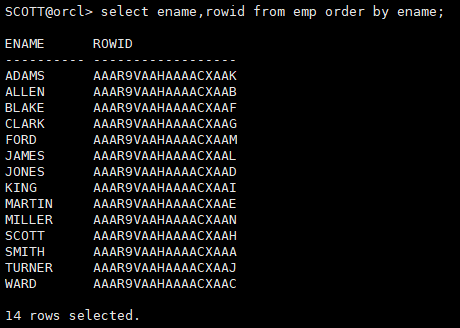
select ename,rowid from emp order by ename;
3.2 rowid
rowid是伪列,oracle专用的虚拟列,每个表的每一行都有rowid
每一行的rowid是全局唯一的(行的身份证号)
AAAR9VAAHAAAACXAAH SCOTT
rowid18位,64进制,包括:所在表的对象号、数据文件号、块号、块行号
6363:6位对象号,3位文件号,6位块号,3位行号
4 创建索引注意事项
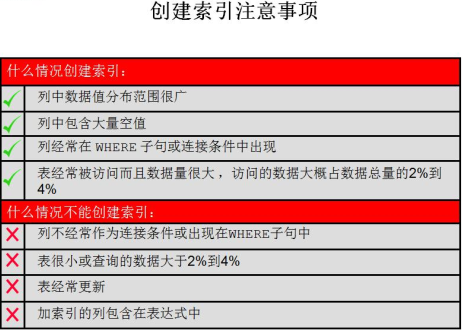
为了优化连接操作,可以在外键列上创建索引,加快匹配行的查找
索引能够提高select语句的效率,但执行DML语句时,oracle要维护索引,会做很多的递归操作,有维护成本
5 索引相关的数据字典视图
user_indexes 查看索引名字、类型、表名、是否唯一索引
user_ind_columns 查看索引名、表名、列名
col index_name for a20
col table_name for a20
select index_name,index_type,table_name from user_indexes;
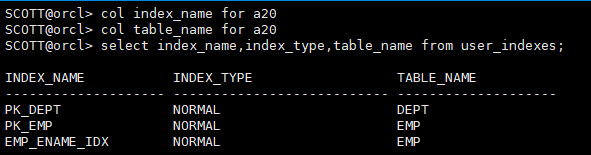
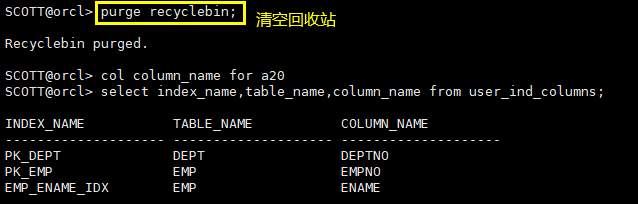
col column_name for a20
select index_name,table_name,column_name from user_ind_columns;
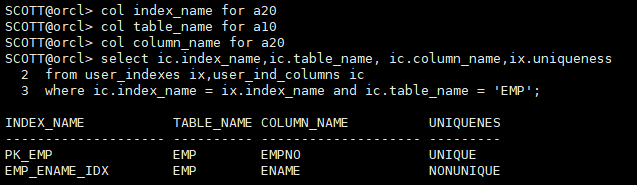
col index_name for a20
col table_name for a10
col column_name for a20
select ic.index_name,ic.table_name, ic.column_name,ix.uniqueness
from user_indexes ix,user_ind_columns ic
where ic.index_name = ix.index_name and ic.table_name = 'EMP';
6 常见B树索引创建语法
create table emp1 as select * from emp;
1)唯一索引,指键值不重复
SCOTT@orcl> create unique index empno_idx on emp1(empno);
2)非唯一索引
SCOTT@orcl> create index empno_idx on emp1(empno);
3)组合索引(Composite):基于两个或多个列的索引
SCOTT@orcl> create index job_deptno_idx on emp1(job,deptno);
4)反向键索引(Reverse):将字节倒置后组织键值。当使用序列产生主键索引时,可以防止叶节点出现热块现象(考点),缺点是无法提供索引范围扫描
SCOTT@orcl> create index mgr_idx on emp1(mgr) reverse;
5)函数索引(Function base):以索引列值的函数值为键值去组织索引
SCOTT@orcl> create index fun_idx on emp1(lower(ename));
6)压缩(Compress):重复键值只存储一次,就是说重复的键值在叶块中就存一次,后跟所有与之匹配的rowid字符串
SCOTT@orcl> create index comp_idx on emp1(sal) compress;
7)升序或降序(Ascending or descending):叶节点中的键值排列默认是升序的
SCOTT@orcl> create index deptno_job_idx on emp1(deptno desc, job asc);
7 基于函数的索引

查看执行计划
explain plan for select * from emp where ename=upper('scott');
@?/rdbms/admin/utlxplp.sql
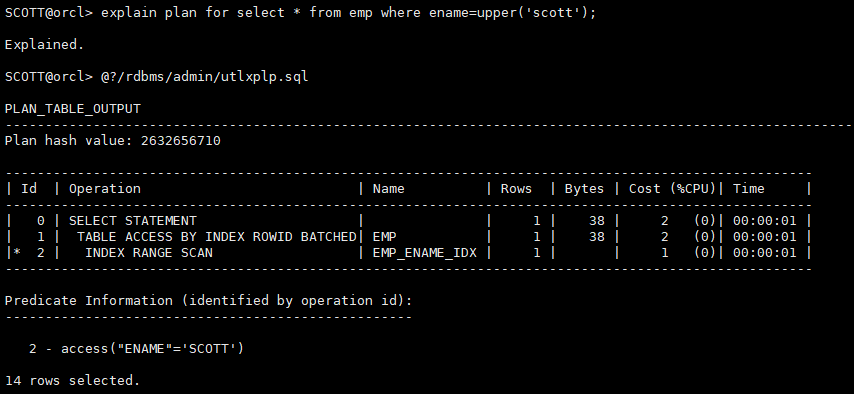
explain plan for select * from emp where lower(ename)='scott';
@?/rdbms/admin/utlxplp.sql

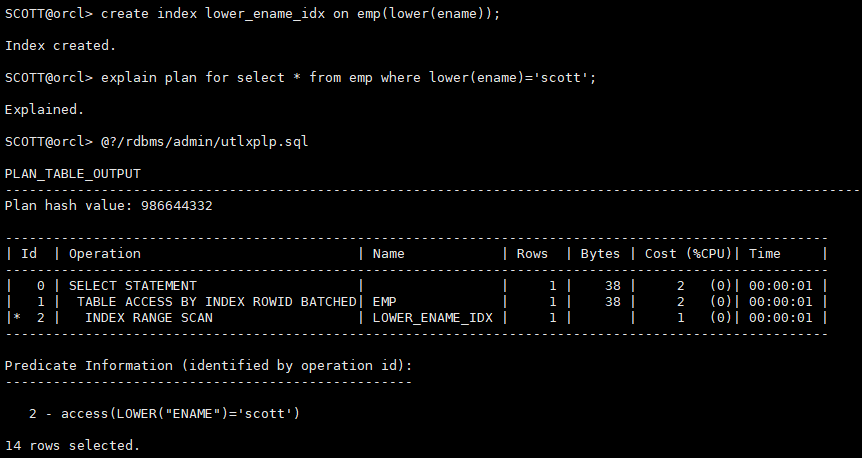
创建基于函数的索引
create index lower_ename_idx on emp(lower(ename));
再次查看执行计划
explain plan for select * from emp where lower(ename)='scott';
@?/rdbms/admin/utlxplp.sql
8 重建索引
语法:alter index index_name rebuild online;
批量重建索引:
select 'alter index ' || index_name || ' rebuild online;' scripts from user_indexes;

9 删除索引

一个无用的索引会降低DML效率,还会占用存储空间
10 索引不可用unusable和不可见invisible
10.1 索引不可用unusable
仅仅保存索引定义,不删除索引,也不更新索引
alter index ind_test_id unusable;
索引被设定为unusable后,如再次使用需要做rebuild
alter index ind_test_id rebuild;
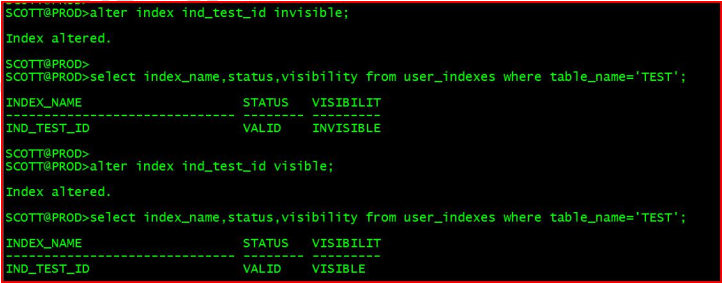
10.2 索引不可见invisible
在11g里,Oracle提供了一个新特性(Index Invisible)来降低直接删除索引或禁用索引的风险。可以在创建索引时指定invisible属性或者用alter语句来修改索引为invisible(visible)
索引不可见其实是对优化器来说不可见,索引维护还是正常进行的
alter index ind_test_id invisible;
select index_name,status,visibility from user_indexes where table_name='TEST';
alter index ind_test_id visible;
select index_name,status,visibility from user_indexes where table_name='TEST';
11 扩展补充:监控索引的使用
开启监控索引的使用情况:
alter index table_name.index_name monitoring usage;
关闭监控索引的使用情况:
alter index table_name.index_name nomonitoring usage;
例子eg:
开启索引监控
alter index pk_dept monitoring usage;

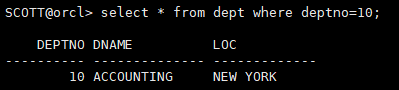
执行查询
select * from dept where deptno=10;
查看索引是否被使用
select * from v$object_usage;

关闭监控
alter index pk_dept nomonitoring usage;


 浙公网安备 33010602011771号
浙公网安备 33010602011771号