hadoop1-构建电影推荐系统
一、 推荐系统概述
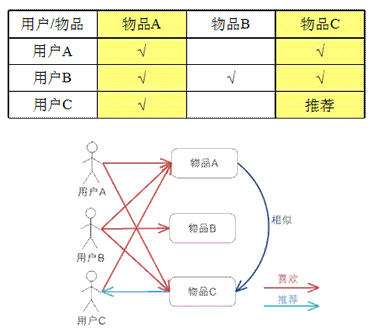
- 1. 计算物品之间的相似度
- 2. 根据物品的相似度和用户的历史行为给用户生成推荐列表
二、 需求分析:推荐系统指标设计
Netflix官方网站:www.netflix.com

部分训练集:http://graphlab.org/wp-content/uploads/2013/07/smallnetflix_mm.train_.gz
部分结果集:http://graphlab.org/wp-content/uploads/2013/07/smallnetflix_mm.validate.gz
完整数据集:http://www.lifecrunch.biz/wp-content/uploads/2011/04/nf_prize_dataset.tar.gz
- 1,101,5.0
- 1,102,3.0
- 1,103,2.5
- 2,101,2.0
- 2,102,2.5
- 2,103,5.0
- 2,104,2.0
- 3,101,2.0
- 3,104,4.0
- 3,105,4.5
- 3,107,5.0
- 4,101,5.0
- 4,103,3.0
- 4,104,4.5
- 4,106,4.0
- 5,101,4.0
- 5,102,3.0
- 5,103,2.0
- 5,104,4.0
- 5,105,3.5
- 5,106,4.0
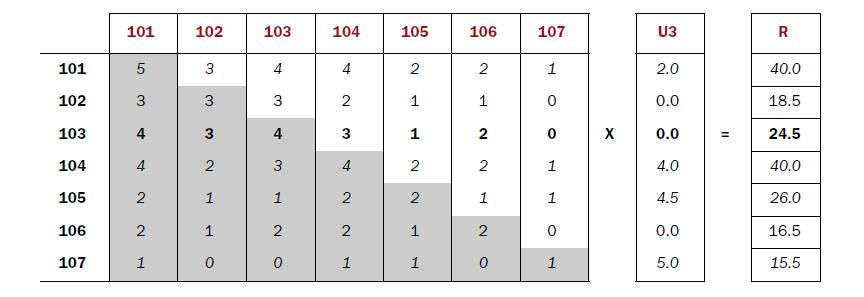
- [101] [102] [103] [104] [105] [106] [107]
- [101] 5 3 4 4 2 2 1
- [102] 3 3 3 2 1 1 0
- [103] 4 3 4 3 1 2 0
- [104] 4 2 3 4 2 2 1
- [105] 2 1 1 2 2 1 1
- [106] 2 1 2 2 1 2 0
- [107] 1 0 0 1 1 0 1
- U3
- [101] 2.0
- [102] 0.0
- [103] 0.0
- [104] 4.0
- [105] 4.5
- [106] 0.0
- [107] 5.0
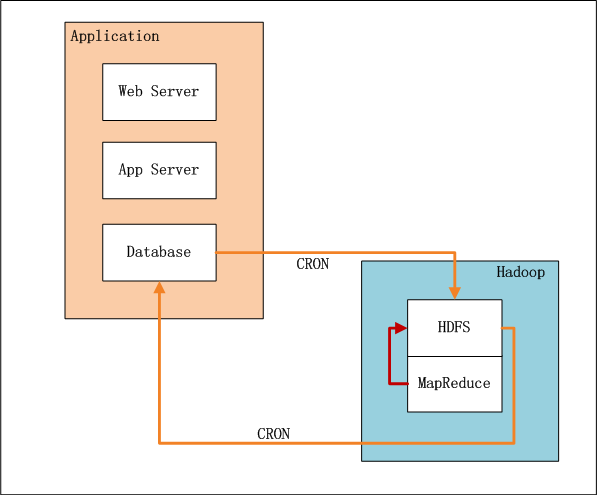
- 业务系统记录了用户的行为和对物品的打分
- 设置系统定时器CRON,每xx小时,增量向HDFS导入数据(userid,itemid,value,time)。
- 完成导入后,设置系统定时器,启动MapReduce程序,运行推荐算法。
- 完成计算后,设置系统定时器,从HDFS导出推荐结果数据到数据库,方便以后的及时查询。
package recommend;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Step1 {
public static class Map extends Mapper<Object, Text, IntWritable, Text>{
private static IntWritable k = new IntWritable();
private static Text v = new Text();
protected void map(Object key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
String[] splits = value.toString().split(",");
if(splits.length != 3){
return;
}
int userId = Integer.parseInt(splits[0]);
String itemId = splits[1];
String pref = splits[2];
//解析出用户ID和关联的商品ID与打分。并输出
k.set(userId);
v.set(itemId+":"+pref);
context.write(k, v);
};
}
public static class Reduce extends Reducer<IntWritable, Text, IntWritable, Text>{
private static StringBuilder sub = new StringBuilder(256);
private static Text v = new Text();
protected void reduce(IntWritable key, Iterable<Text> values, Context context)
throws java.io.IOException ,InterruptedException {
//合并用户的关联商品ID,作为一个组
for (Text v : values) {
sub.append(v.toString()+",");
}
v.set(sub.toString());
context.write(key, v);
sub.delete(0, sub.length());
};
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage:Step1");
System.exit(2);
}
Job job = new Job(conf,"Step1");
job.setJarByClass(Step1.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
计算结果:
[root@hadoop ~]# hadoop dfs -cat /step1/*
1 102:3.0,103:2.5,101:5.0,
2 101:2.0,102:2.5,103:5.0,104:2.0,
3 107:5.0,101:2.0,104:4.0,105:4.5,
4 101:5.0,103:3.0,104:4.5,106:4.0,
5 101:4.0,102:3.0,103:2.0,104:4.0,105:3.5,106:4.0,
使用Step1的输出结果作为输入的数据文件
package recommend;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
//使用Step1的输出结果作为输入的数据文件
public class Step2 {
public static class Map extends Mapper<Object, Text, Text, IntWritable>{
private static Text k = new Text();
private static IntWritable v = new IntWritable(1);
protected void map(Object key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
String[] tokens = value.toString().split("\t")[1].split(",");
//商品的相关是相互的,当然也包含自己。
String item1Id = null;
String item2Id = null;
for (int i = 0; i < tokens.length; i++) {
item1Id = tokens[i].split(":")[0];
for (int j = 0; j < tokens.length; j++) {
item2Id = tokens[j].split(":")[0];
k.set(item1Id+":"+item2Id);
context.write(k, v);
}
}
};
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable>{
private static IntWritable v = new IntWritable();
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws java.io.IOException ,InterruptedException {
int count = 0;
//计算总的次数
for (IntWritable temp : values) {
count++;
}
v.set(count);
context.write(key, v);
};
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage:Step2");
System.exit(2);
}
Job job = new Job(conf,"Step2");
job.setJarByClass(Step2.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
计算结果:
[root@hadoop ~]# hadoop dfs -cat /step2/*
101:101 5
101:102 3
101:103 4
101:104 4
101:105 2
101:106 2
101:107 1
102:101 3
102:102 3
102:103 3
102:104 2
102:105 1
102:106 1
103:101 4
103:102 3
103:103 4
103:104 3
103:105 1
103:106 2
104:101 4
104:102 2
104:103 3
104:104 4
104:105 2
104:106 2
104:107 1
105:101 2
105:102 1
105:103 1
105:104 2
105:105 2
105:106 1
105:107 1
106:101 2
106:102 1
106:103 2
106:104 2
106:105 1
106:106 2
107:101 1
107:104 1
107:105 1
107:107 1
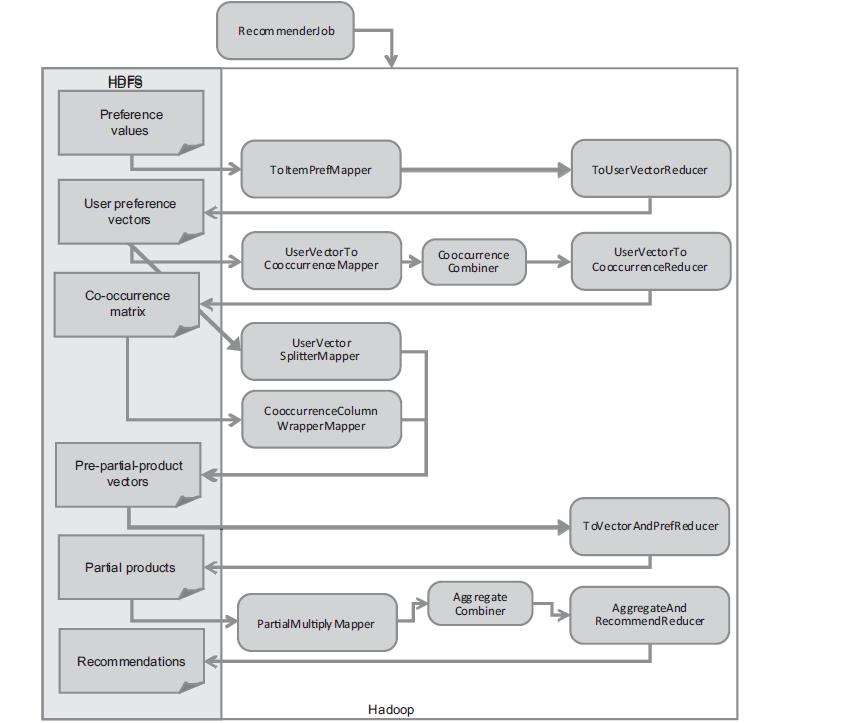
(忽略了原有参考的step3_2这一步,因为他的输出是和step2的输出是一样的。)
package recommend;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Step3 {
public static class Map extends Mapper<LongWritable, Text, IntWritable, Text>{
private static IntWritable k = new IntWritable();
private static Text v = new Text();
protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
String[] tokens = value.toString().split("\t");
String[] vector = tokens[1].split(",");
for (String s : vector) {
String[] t = s.split(":");
//设置商品ID
k.set(Integer.parseInt(t[0]));
//设置用户ID:评分
v.set(tokens[0]+":"+t[1]);
context.write(k, v);
}
};
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage:Step3");
System.exit(2);
}
Job job = new Job(conf,"Step3");
job.setJarByClass(Step3.class);
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
计算结果:
[root@hadoop ~]# hadoop dfs -cat /step3_1/*
101 5:4.0
101 1:5.0
101 2:2.0
101 3:2.0
101 4:5.0
102 1:3.0
102 5:3.0
102 2:2.5
103 2:5.0
103 5:2.0
103 1:2.5
103 4:3.0
104 2:2.0
104 5:4.0
104 3:4.0
104 4:4.5
105 3:4.5
105 5:3.5
106 5:4.0
106 4:4.0
107 3:5.0
package recommend;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Step4 {
public static class Map extends Mapper<Object, Text, IntWritable, Text>{
private static IntWritable k = new IntWritable();
private static Text v = new Text();
private static java.util.Map<Integer, List<Coocurence>> matrix = new HashMap<Integer, List<Coocurence>>();
protected void map(Object key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
//文件一格式、101 5:4.0 文件二格式、101:101 5
String[] tokens = value.toString().split("\t");
String[] v1 = tokens[0].split(":");
String[] v2 = tokens[1].split(":");
//文件二 101:101 5
if(v1.length > 1){
int itemId1 = Integer.parseInt(v1[0]);
int itemId2 = Integer.parseInt(v1[1]);
int num = Integer.parseInt(tokens[1]);
List<Coocurence> list = null;
if(matrix.containsKey(itemId1)){
list = matrix.get(itemId1);
}else{
list = new ArrayList<Coocurence>();
}
list.add(new Coocurence(itemId1, itemId2, num));
matrix.put(itemId1,list);
}
//文件一 101 5:4.0
if(v2.length > 1){
int itemId = Integer.parseInt(tokens[0]);
int userId = Integer.parseInt(v2[0]);
double pref = Double.parseDouble(v2[1]);
k.set(userId);
for (Coocurence c : matrix.get(itemId)) {
v.set(c.getItemId2()+","+pref*c.getNum());
context.write(k, v);
}
}
};
}
public static class Reduce extends Reducer<IntWritable, Text, IntWritable, Text>{
private static Text v = new Text();
protected void reduce(IntWritable key, Iterable<Text> values, Context context)
throws java.io.IOException ,InterruptedException {
java.util.Map<String, Double> result = new HashMap<String, Double>();
for (Text t : values) {
String[] str = t.toString().split(",");
if(result.containsKey(str[0])){
result.put(str[0], result.get(str[0])+Double.parseDouble(str[1]));
}else {
result.put(str[0], Double.parseDouble(str[1]));
}
}
Iterator<String> iter = result.keySet().iterator();
while (iter.hasNext()){
String itemId = iter.next();
double score = result.get(itemId);
v.set(itemId+","+score);
context.write(key, v);
}
};
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 3){
System.err.println("Usage:Step4");
System.exit(2);
}
Job job = new Job(conf,"Step4");
job.setJarByClass(Step4.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
//设置step2和step3_1两个输入目录作为输入,所以系统需要三个参数配置
FileInputFormat.addInputPath(job,new Path(args[0]));
FileInputFormat.addInputPath(job,new Path(args[1]));
FileOutputFormat.setOutputPath(job, new Path(args[2]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
class Coocurence{
private int itemId1;
private int itemId2;
private int num;
public Coocurence(int itemId1, int itemId2, int num) {
super();
this.itemId1 = itemId1;
this.itemId2 = itemId2;
this.num = num;
}
public int getItemId1() {
return itemId1;
}
public void setItemId1(int itemId1) {
this.itemId1 = itemId1;
}
public int getItemId2() {
return itemId2;
}
public void setItemId2(int itemId2) {
this.itemId2 = itemId2;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}
计算结果:
[root@hadoop ~]# hadoop dfs -cat /output/*
1 107,5.0
1 106,18.0
1 105,15.5
1 104,33.5
1 103,39.0
1 102,31.5
1 101,44.0
2 107,4.0
2 106,20.5
2 105,15.5
2 104,36.0
2 103,41.5
2 102,32.5
2 101,45.5
3 107,15.5
3 106,16.5
3 105,26.0
3 104,38.0
3 103,24.5
3 102,18.5
3 101,40.0
4 107,9.5
4 106,33.0
4 105,26.0
4 104,55.0
4 103,53.5
4 102,37.0
4 101,63.0
5 107,11.5
5 106,34.5
5 105,32.0
5 104,59.0
5 103,56.5
5 102,42.5
5 101,68.0
--------------------------------------------------------------------------------
参考:http://www.aboutyun.com/thread-8155-1-1.html
https://github.com/bsspirit/maven_hadoop_template/releases/tag/recommend

 浙公网安备 33010602011771号
浙公网安备 33010602011771号