centos7单机安装kafka,进行生产者消费者测试
原文出处:http://www.yund.tech/zdetail.html?type=1&id=3028469704c7976aef5b824811dd3bf5
作者:jstarseven
一、kafka介绍
Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- 支持在线水平扩展
二、kafka架构图
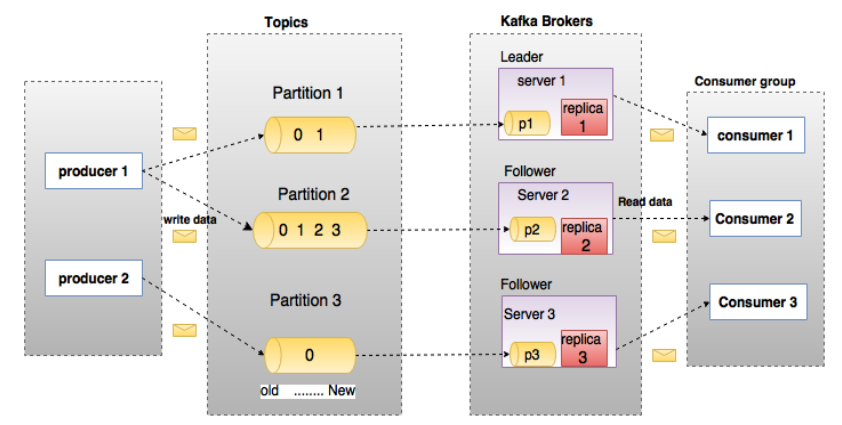

三、kafka安装与测试
1、配置JDK环境
Kafka 使用Zookeeper 来保存相关配置信息,Kafka及Zookeeper 依赖Java 运行环境,从oracle网站下载JDK 安装包,解压安装
1 tar zxvf jdk-8u171-linux-x64.tar.gz 2 mv jdk1.8.0_171 /usr/local/java/
设置Java 环境变量:
1 #java 2 export JAVA_HOME=/usr/local/java/jdk1.8.0_171 3 export PATH=$PATH:$JAVA_HOME/bin 4 export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
2、安装kafka
下载地址:http://kafka.apache.org/downloads
1 cd /opt 2 wget http://mirror.bit.edu.cn/apache/kafka/2.3.0/kafka_2.11-2.3.0.tgz 3 tar zxvf kafka_2.11-2.3.0.tgz 4 mv kafka_2.11-2.3.0 /usr/local/apps/ 5 cd /usr/local/apps/ 6 ln -s kafka_2.11-2.3.0 kafka
3、启动测试
(1)启动Zookeeper服务
1 cd /usr/local/apps/kafka 2 #执行脚本 3 bin/zookeeper-server-start.sh -daemon config/zookeeper.properties 4 #查看进程 5 jps
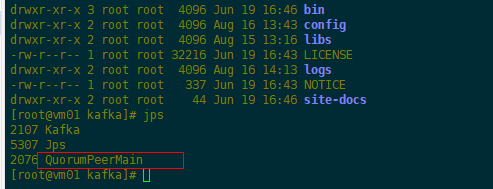
(2)启动单机Kafka服务
1 #执行脚本 2 bin/kafka-server-start.sh config/server.properties 3 #查看进程 4 jps
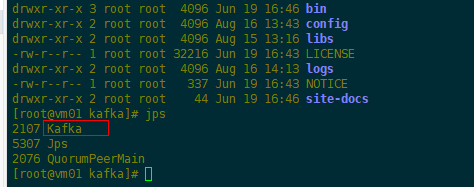
(3)创建topic进行测试
1 #执行脚本 2 bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
(4)查看topic列表
1 #执行脚本 2 bin/kafka-topics.sh --list --zookeeper localhost:2181 3 输出:test

(5)生产者消息测试
1 #执行脚本(使用kafka-console-producer.sh 发送消息) 2 bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test

(6)消费者消息测试
1 #执行脚本(使用kafka-console-consumer.sh 接收消息并在终端打印) 2 bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning

4、单机多broker集群配置
单机部署多个broker,不同的broker,设置不同的id、监听端口、日志目录
1 cp config/server.properties config/server-1.properties 2 vim server-1.properties 3 #修改: 4 broker.id=1 5 port=9093 6 log.dir=/tmp/kafka-logs-1 7 #启动Kafka服务 8 bin/kafka-server-start.sh config/server-1.properties &
5、java代码实现生产者消费者
(1)maven项目添加kafka依赖
1 <dependency> 2 <groupId>org.apache.kafka</groupId> 3 <artifactId>kafka-clients</artifactId> 4 <version>2.3.0</version> 5 </dependency>
(2)java代码实现
1 package com.server.kafka; 2 3 import org.apache.kafka.clients.consumer.ConsumerConfig; 4 import org.apache.kafka.clients.consumer.ConsumerRecord; 5 import org.apache.kafka.clients.consumer.ConsumerRecords; 6 import org.apache.kafka.clients.consumer.KafkaConsumer; 7 import org.apache.kafka.clients.producer.KafkaProducer; 8 import org.apache.kafka.clients.producer.ProducerConfig; 9 import org.apache.kafka.clients.producer.ProducerRecord; 10 import org.apache.kafka.common.serialization.StringDeserializer; 11 import org.apache.kafka.common.serialization.StringSerializer; 12 13 import java.util.Collections; 14 import java.util.Properties; 15 import java.util.Random; 16 17 18 public class KafakaExecutor { 19 20 public static String topic = "test"; 21 22 public static void main(String[] args) { 23 new Thread(()-> new Producer().execute()).start(); 24 new Thread(()-> new Consumer().execute()).start(); 25 } 26 27 public static class Consumer { 28 29 private void execute() { 30 Properties p = new Properties(); 31 p.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.21.181:9092"); 32 p.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); 33 p.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class); 34 p.put(ConsumerConfig.GROUP_ID_CONFIG, topic); 35 36 KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(p); 37 // 订阅消息 38 kafkaConsumer.subscribe(Collections.singletonList(topic)); 39 40 while (true) { 41 ConsumerRecords<String, String> records = kafkaConsumer.poll(100); 42 for (ConsumerRecord<String, String> record : records) { 43 System.out.println(String.format("topic:%s,offset:%d,消息:%s", // 44 record.topic(), record.offset(), record.value())); 45 } 46 } 47 } 48 } 49 50 51 public static class Producer { 52 53 private void execute() { 54 Properties p = new Properties(); 55 //kafka地址,多个地址用逗号分割 56 p.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.21.181:9092"); 57 p.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class); 58 p.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class); 59 KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(p); 60 61 try { 62 while (true) { 63 String msg = "Hello," + new Random().nextInt(100); 64 ProducerRecord<String, String> record = new ProducerRecord<>(topic, msg); 65 kafkaProducer.send(record); 66 System.out.println("消息发送成功:" + msg); 67 Thread.sleep(500); 68 } 69 } catch (InterruptedException e) { 70 e.printStackTrace(); 71 } finally { 72 kafkaProducer.close(); 73 } 74 } 75 76 } 77 }
(3)测试结果(上面使用脚本命令执行消费者的终端也会同步输出消息数据)

参考:https://www.cnblogs.com/frankdeng/p/9310684.html
-END-


 浙公网安备 33010602011771号
浙公网安备 33010602011771号