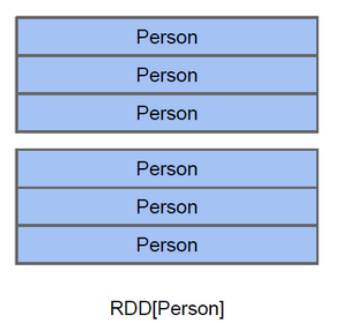
- RDD:
![]()
以Person为类型参数,但是Spark框架本身不了解Person类的内部结构。
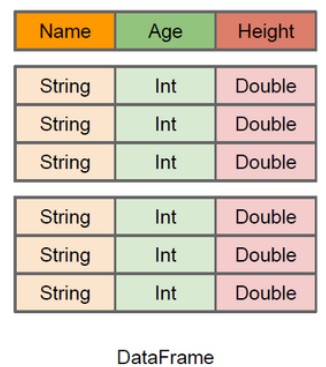
- DataFrame:
![]()
DataFrame每一行的类型固定为Row, 每一列的值没法直接访问,只有通过解析才能获取各个字段的值。
- DataSet:
DataFrame也可以叫DataSet[Row],每一行类型是Row,不解析,每一行究竟有哪些字段,各个字段又是什么类型都无从得知,只能用上面的getAs方法拿出特定字段,而DataSet中,每一行是什么类型是不一定的,在自定义case class之后可以很自由的获取每一行的信息。
- 三者关系
RDD是分布式的Java对象的集合。DataFrame是分布式的Row对象的集合,DataFrame=Dataset[Row]。
|
RDD |
DataFrame |
Dataset |
| 3者区别:数据类型 |
RDD[Int] |
DataFrame:不能跟数据类型 |
Dataset[Int] |
| 2者区别: |
|
1. DataFrame中存放的数据类型Row代表的是行数据,一个row就是一行数据。2.但是Row中每一行中有几列数据,每一列数据是什么类型,什么字段名Row都无法看出来,需要通过row.getAs[数据类型](列名/列的索引)获取对应的列的结果 |
1. Dataset除了Row类型意外,可以存储Scala支持的任何一种数据类型。包括元组、类或其他类型数据,Dataset中存放的每一种数据类型就是Dataset表格结构中的一行数据。 |
| 转换 |
函数 |
| RDD直接转DataFrame |
隐式转换函数toDF |
| RDD直接转Dataset |
隐式转换函数toDS |
| DataFram转换RDD |
dataframe.rdd |
| DataFrame转换Dataset |
dataframe.as[类型]--导入隐式转换 |
| Dataset转DataFrame |
dataset.toDF |
| Dataset转RDD |
dataset.rdd |



 浙公网安备 33010602011771号
浙公网安备 33010602011771号