

随笔分类 - 日报
摘要:编写脚本 [root@node1 data]# cat dirandportToLogger.conf # 给flume采集进程起一个别名 a1 # 定义flume进程中有几个source、sink、channel,以及每一个source的别名 a1.sources = r1 r2 a1.sinks
阅读全文
摘要:案例说明 source:spooling directory Source 监控指定目录内数据变更 编写脚本 # 给flume采集进程起一个别名 a1 # 定义flume进程中有几个source、sink、channel,>以及每一个source的别名 a1.sources = r1 a1.sink
阅读全文
摘要:案例说明 数据源:netcat source 目的地:logger Sink source:netcat,host,post channel:基于内存的缓冲池 memory sink:logger 配置文件 [root@node1 data]# vim portToLogger.conf [root
阅读全文
摘要:Flume采集数据的工作图 Flume采集数据的工作流程 Flume配置过程 [root@node1 ~]# pwd /opt/software/ [root@node1 software]# tar -zxvf apache-flume-1.8.0-bin.tar.gz -C /opt/app/
阅读全文
摘要: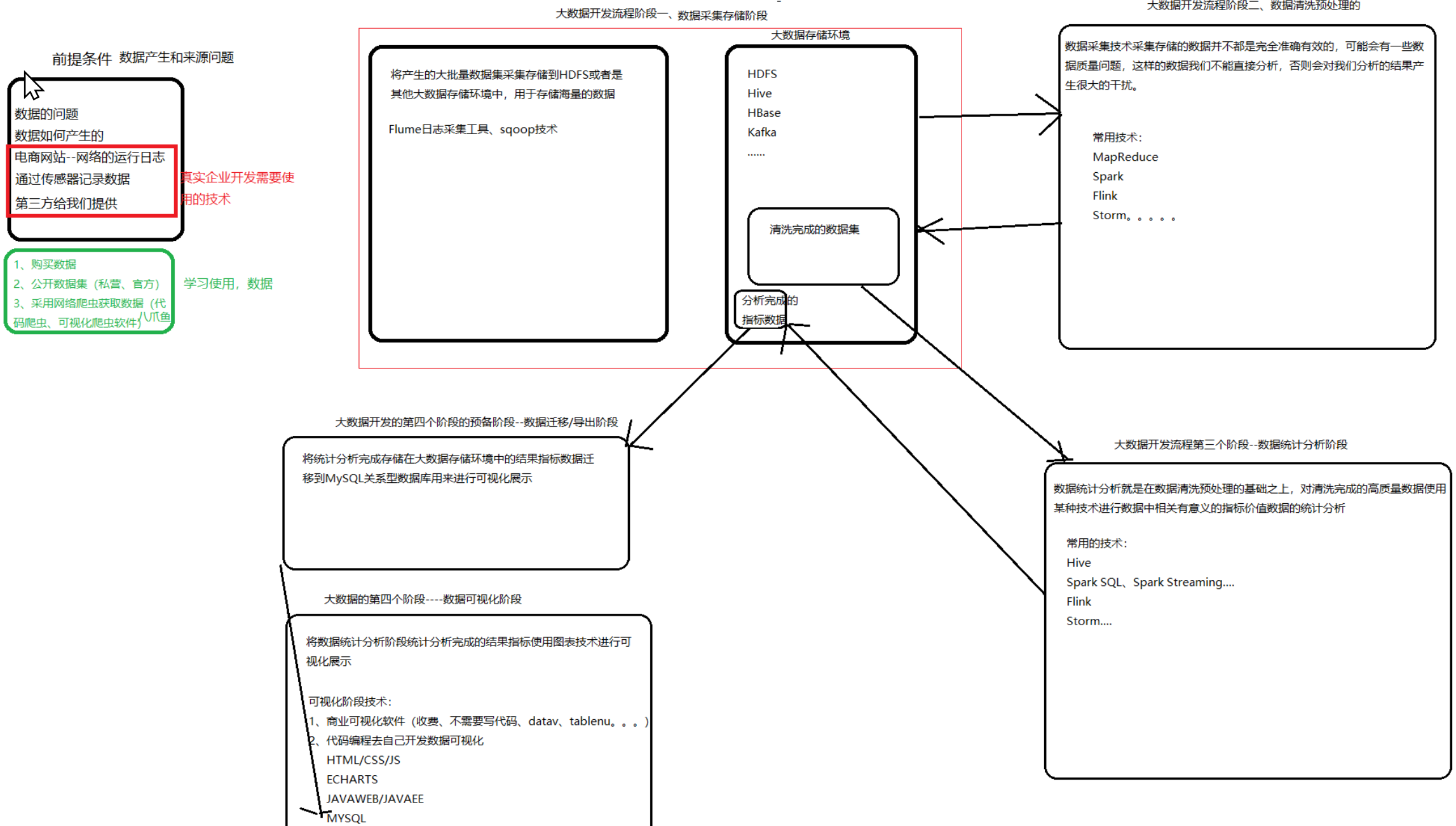
阅读全文
摘要:1. 在mysql中创建表 2. 导入hdfs中 # 将表student导入hdfs中 sqoop import --connect jdbc:mysql://node1:3306/shixun?serverTimezone=UTC --username root --password Jsq123
阅读全文
摘要:配置环境 1. 将jar包上传至/opt/software目录下 2. 解压 tar -zxvf sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz -C /opt/app/ 3. 改名字 mv sqoop-1.4.7.bin__hadoop-2.6.0/ sqoop-1.4.
阅读全文
摘要:pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance
阅读全文
摘要:案例要求 java编写 package udtf; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.metadata.HiveException; import
阅读全文
摘要:1. 添加maven依赖 一、pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XML
阅读全文
摘要:1. explode炸裂一行的数据 求一个界面的广告数量 page adid page1 1 page1 2 page1 3 page1 4 [root@node1 data]# cat ad.txt page1,1_3_5_9_10_56 page2,30_123_34_7_9_10 page3,
阅读全文
摘要:函数分类 UDF函数:一进一出,length UDAF函数:多进一出,聚合函数:sum、count UDTF函数:一进多出,explode、split 查看函数用法 查看系统自带的函数: show functions; 显示自带的函数的用法: desc functions 函数名; 详细显示自带的函
阅读全文
摘要:hive的执行命令 beeline的使用规则 需要配置hiveserver2 hive的配置文件:hive-site.xml <property> <name>hive.server2.authentication</name> <value>NONE</value> </property> <pr
阅读全文
摘要:1. 文本输出TextOutputFormat 默认的输出格式,把每条记录写为文本行 默认分隔符定义是:\t 即 key\tvalue 将最终输出的key、value数据以指定的分隔符(默认是\t)将key value拼接,然后以字符串(普通的文本数据)写出到结果文件中 分隔符可以自定义: conf
阅读全文
摘要:定义: 继承Reducer类,Combiner就是一个Reducer,但是处理的是某一个map的输出数据 数据写出到reducer了 job.setCombinerClass(WCCombiner.class); // 输入类型是map阶段的输出类型,输出类型一般是map阶段的输出类型 class
阅读全文
摘要:
阅读全文
摘要:[root@node1 conf]# mv hive-env.sh.template hive-env.sh [root@node1 conf]# vi hive-env.sh export HIVE_CONF_DIR=/opt/app/hive-2.3.8/conf export HADOOP_H
阅读全文
摘要:1. Mapreduce 1. 计算机性能 CPU、内存、磁盘、网络 2. IO操作优化 (1)数据倾斜 (2)Map和Reduce数设置不合理 (3)Map运行时间太长,导致reduce等待时间过久 (4)小文件过多 (5)大量的不可分块的超大文件 (6)Spill溢出次数过多 (7)Merge次
阅读全文
摘要:[root@node1 hadoop]# cat mapred-site.xml <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apa
阅读全文
摘要:分区的默认方式hashpartitioner public int getPartition(K2 key, V2 value, int numReduceTasks) { return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; }
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号