100天搞定机器学习|Day56 随机森林工作原理及调参实战(信用卡欺诈预测)
本文是对100天搞定机器学习|Day33-34 随机森林的补充
前文对随机森林的概念、工作原理、使用方法做了简单介绍,并提供了分类和回归的实例。
本期我们重点讲一下:
1、集成学习、Bagging和随机森林概念及相互关系
2、随机森林参数解释及设置建议
3、随机森林模型调参实战
4、随机森林模型优缺点总结
集成学习、Bagging和随机森林
集成学习
集成学习并不是一个单独的机器学习算法,它通过将多个基学习器(弱学习器)进行结合,最终获得一个强学习器。这里的弱学习器应该具有一定的准确性,并且要有多样性(学习器之间具有差异),比较常用的基学习器有决策树和神经网络。
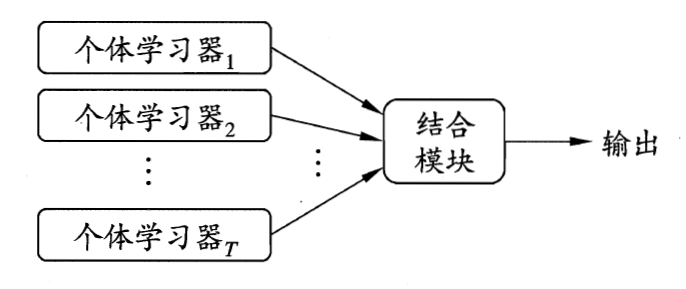
集成学习的核心就是如何产生并结合好而不同的基学习器,这里有两种方式是,一种是Bagging,基学习器之间没有强依赖关系,可同时生成的并行化方法。一种是Boosting,基学习器之间有强依赖关系,必须串行生成。
集成学习另一个关键问题是结合策略,主要有平均法、投票法和学习法,这里不再展开。
Bagging
Bagging是Bootstrap AGGregaING的缩写,Bootstrap即随机采样,比如给定含有$m$个样本的数据集$D$,每次随机的从中选择一个样本,放入新的数据集,然后将其放回初始数据集$D$,放回后有可能继续被采集到,重复这个动作$m$次,我们就得到新的数据集$D'$。
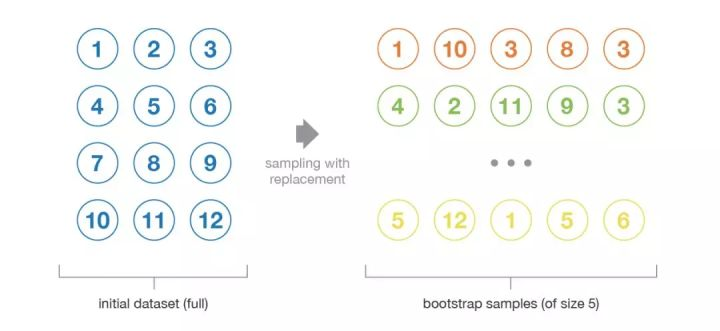
用这种方式,我们可以采样出TGE含m个训练样本的采样集,然后基于每个采样集训练基学习器,再将基学习器进行结合,这便是Bagging的基本流程。
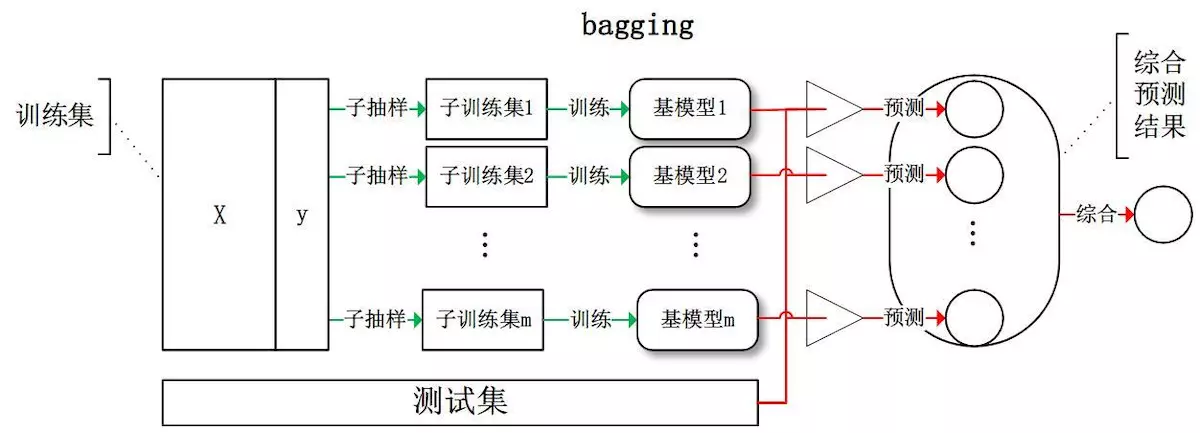
随机森林
随机森林是非常具有代表性的Bagging集成算法,它在Bagging基础上进行了强化。
它的所有基学习器都是CART决策树,传统决策树在选择划分属性时是在当前结点的属性集合(假定有d个属性)中选择最优属性。但是随机森林的决策树,现在每个结点的属性集合随机选择部分k个属性的子集,然后在子集中选择一个最优的特征来做决策树的左右子树划分,一般建议$k=log_2d$.分类决策树组成的森林就叫做随机森林分类器,回归决策树所集成的森林就叫做随机森林回归器。
RF的算法:
输入为样本集$D={(x_,y_1),(x_2,y_2), ...(x_m,y_m)}$,弱分类器迭代次数T。
输出为最终的强分类器$f(x)$
1)对于t=1,2...,T:
a)对训练集进行第t次随机采样,共采集m次,得到包含m个样本的采样集Dt
b)用采样集$D_t$训练第t个决策树模型$G_t(x)$,在训练决策树模型的节点的时候, 在节点上所有的样本特征中选择一部分样本特征, 在这些随机选择的部分样本特征中选择一个最优的特征来做决策树的左右子树划分
2)如果是分类算法预测,则T个弱学习器投出最多票数的类别或者类别之一为最终类别。如果是回归算法,T个弱学习器得到的回归结果进行算术平均得到的值为最终的模型输出。
随机森林参数解释及设置建议
在scikit-learn中,RandomForest的分类类是RandomForestClassifier,回归类是RandomForestRegressor,需要调参的参数包括两部分,第一部分是Bagging框架的参数,第二部分是CART决策树的参数。这里我们看一下scikit-learn中随机森林的主要参数



随机森林模型调参实战
这是一道kaggle上的题目,通过信用卡交易记录数据对欺诈行为进行预测,信用卡欺诈检测文件记录了2013年9月欧洲信用卡持有者所发生的交易。在284807条交易记录中共包含492条欺诈记录。
数据集下载地址:请在公众号后台回复[56]
需要说明的是,本文重点是RF模型调参,所以不涉及数据预处理、特征工程和模型融合的内容,这些我会在本栏目未来的章节中再做介绍。
所以最终结果可能会不理想,这里我们只关注通过调参给模型带来的性能提升和加深对重要参数的理解即可。
1、导入用到的包
import numpy as np
import pandas as pd
from sklearn.model_selection import GridSearchCV,train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
2、导入数据
df = pd.read_csv("D:\WKS\PyProject\Credit_Card\creditcard.csv")
data=df.iloc[:,1:31]
284807条交易记录中只有492条欺诈记录,样本严重不平衡,这里我们需要使用下采样策略(减少多数类使其数量与少数类相同)
X = data.loc[:, data.columns != 'Class']
y = data.loc[:, data.columns == 'Class']
number_records_fraud = len(data[data.Class == 1]) # class=1的样本函数
fraud_indices = np.array(data[data.Class == 1].index) # 样本等于1的索引值
normal_indices = data[data.Class == 0].index # 样本等于0的索引值
random_normal_indices = np.random.choice(normal_indices,number_records_fraud,replace = False)
random_normal_indices = np.array(random_normal_indices)
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices]) # Appending the 2 indices
under_sample_data = data.iloc[under_sample_indices,:] # Under sample dataset
X_undersample = under_sample_data.loc[:,under_sample_data.columns != 'Class']
y_undersample = under_sample_data.loc[:,under_sample_data.columns == 'Class']
X_train, X_test, y_train, y_test = train_test_split(X_undersample,y_undersample,test_size = 0.3, random_state = 0)
先用默认参数训练RF
rf0 = RandomForestClassifier(oob_score=True, random_state=666)
rf0.fit(X_train,y_train)
print(rf0.oob_score_)
y_predprob = rf0.predict_proba(X_test)[:,1]
print("AUC Score (Train): %f" % roc_auc_score(y_test, y_predprob))
0.9244186046511628
AUC Score (Train): 0.967082
除oob_score将默认的False改为True, 我们重点优化n_estimators、max_depth、min_samples_leaf 这三个参数。为简单起见,模型评价指标,我们选择AUC值。
模型调优我们采用网格搜索调优参数(grid search),通过构建参数候选集合,然后网格搜索会穷举各种参数组合,根据设定评定的评分机制找到最好的那一组设置。
先优化n_estimators
param_test1 = {'n_estimators':range(10,101,10)}
gsearch1 = GridSearchCV(estimator = RandomForestClassifier(oob_score=True, random_state=666,n_jobs=2),
param_grid = param_test1, scoring='roc_auc',cv=5)
gsearch1.fit(X_train,y_train)
gsearch1.cv_results_, gsearch1.best_params_, gsearch1.best_score_
{'n_estimators': 50},
0.9799524239675649)
在优化后的n_estimators基础上,优化max_features
param_test2 = {'max_depth':range(2,12,2)}
gsearch2 = GridSearchCV(estimator = RandomForestClassifier(n_estimators= 50,oob_score=True, random_state=666,n_jobs=2),
param_grid = param_test2, scoring='roc_auc',cv=5)
gsearch2.fit(X_train,y_train)
gsearch2.cv_results_, gsearch2.best_params_, gsearch2.best_score_
{'max_depth': 6},
0.9809897227343921)
在上述两个参数优化结果的基础上优化max_depth
param_test2 = {'min_samples_split':range(2,8,1)}
gsearch2 = GridSearchCV(estimator = RandomForestClassifier(n_estimators= 50,max_depth=6,
oob_score=True, random_state=666,n_jobs=2),
param_grid = param_test2, scoring='roc_auc',cv=5)
gsearch2.fit(X_train,y_train)
gsearch2.cv_results_, gsearch2.best_params_, gsearch2.best_score_
{'min_samples_split': 5},
0.9819618127837587)
最后我们综合再次尝试
rf1 = RandomForestClassifier(n_estimators= 50,max_depth=6,min_samples_split=5,oob_score=True, random_state=666,n_jobs=2)
rf1.fit(X_train,y_train)
print(rf1.oob_score_)
y_predprob1 = rf1.predict_proba(X_test)[:,1]
print("AUC Score (Train): %f" % roc_auc_score(y_test, y_predprob1))
0.9331395348837209
AUC Score (Train): 0.977811
最终结果比调参前有所提升
随机森林优缺点总结
RF优点
1.不容易出现过拟合,因为选择训练样本的时候就不是全部样本。
2.可以既可以处理属性为离散值的量,比如ID3算法来构造树,也可以处理属性为连续值的量,比如C4.5算法来构造树。
3.对于高维数据集的处理能力令人兴奋,它可以处理成千上万的输入变量,并确定最重要的变量,因此被认为是一个不错的降维方法。此外,该模型能够输出变量的重要性程度,这是一个非常便利的功能。
4.分类不平衡的情况时,随机森林能够提供平衡数据集误差的有效方法
RF缺点
1.随机森林在解决回归问题时并没有像它在分类中表现的那么好,这是因为它并不能给出一个连续型的输出。当进行回归时,随机森林不能够作出超越训练集数据范围的预测,这可能导致在对某些还有特定噪声的数据进行建模时出现过度拟合。
2.对于许多统计建模者来说,随机森林给人的感觉像是一个黑盒子——你几乎无法控制模型内部的运行,只能在不同的参数和随机种子之间进行尝试。
参考:
https://www.jianshu.com/p/708dff71df3a
https://zhuanlan.zhihu.com/p/30461746
https://www.cnblogs.com/pinard/p/6156009.html
《百面机器学习》中有一道关于随机森林的面试题,大家可以思考一下:
可否将随机森林中的基分类器由决策树替换为线性分类器或K-近邻呢?
解答:随机森林属于Bagging类的集成学习,Bagging的主要好处是集成后的分类器的方差比基分类器方差小。Bagging采用的分类器最好是本身对样本分布比较敏感(即不稳定的分类器),这样Bagging才有价值。线性分类器或K-近邻都是比较稳定,本身方差就很小,所以以他们作为基分类器使用Bagging并不能获得更好地表现,甚至可能因为Bagging的采样导致训练中更难收敛,从而增大集成分类器的偏差。

本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号