Linux之awk函数(三)
1.命令结构:
awk 'BEGIN{ commands } pattern{ commands } END{ commands }'
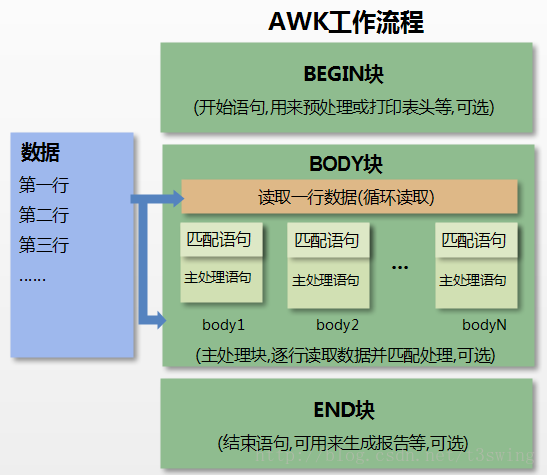
1、通过关键字 BEGIN 执行 BEGIN 块的内容,即 BEGIN 后花括号 {} 的内容。 2、完成 BEGIN 块的执行,开始执行body块。 3、读入有 \n 换行符分割的记录。 4、将记录按指定的域分隔符划分域,填充域,$0 则表示所有域(即一行内容),$1 表示第一个域,$n 表示第 n 个域。 5、依次执行各 BODY 块,pattern 部分匹配该行内容成功后,才会执行 awk-commands 的内容。 6、循环读取并执行各行直到文件结束,完成body块执行。 7、开始 END 块执行,END 块可以输出最终结果。
注:为啥函数都有BEGIN,因为pattern是读文件匹配的。所以没有要读的文件时,用BEGIN块,来执行函数。
2. 函数
2.1 字符串函数
2.1.1 gsub( Ere, Repl, [ In ] )
说明:gsub 是全局替换( global substitution )的缩写。除了正则表达式所有具体值被替代这点,它和 sub 函数完全一样地执行。
2.1.1.1 gsub实例
[root@localhost ~]# awk 'BEGIN{str="welcome to tianjin" ; print str ; gsub("tianjin","beijing" ,str) ; print str}' welcome to tianjin welcome to beijing [root@localhost ~]#
2.1.2 sub(regex,sub,string)
说明:sub 函数执行一次子串替换。它将第一次出现的子串用 regex 替换。第三个参数是可选的,默认为 $0。
2.1.2.1 sub实例
[root@localhost ~]# awk 'BEGIN{str="welcome to tianjin" ; print str ; sub("tianjin","beijing" ,str) ; print str}' welcome to tianjin welcome to beijing [root@localhost ~]#
2.1.3 substr(str, start, l)
说明:substr 函数返回 str 字符串中从第 start 个字符开始长度为 l 的子串。如果没有指定 l 的值,返回 str 从第 start 个字符开始的后缀子串。
2.1.3.1 substr 实例、
[root@localhost ~]# awk 'BEGIN{str="welcome to tianjin" ; print str ; print substr(str,1 ,3) }' welcome to tianjin wel [root@localhost ~]#
2.2 其它函数
2.2.1 close(expr) 函数
说明:关闭管道的文件
[root@ecs-76840553 ~]# awk 'BEGIN {cmd = "tr [a-z] [A-Z]" ;print "hello, world !!!" | cmd ;close(cmd, "to") ;cmd | getline outprint out; close(cmd);}' HELLO, WORLD !!!
2.2.2 delete 函数
说明:用于从数组中删除元素
[root@ecs-76840553 ~]# awk 'BEGIN{array[0]="1";array[1]="2";array[2]="3"; print "delete befor...";for(i in array){print array[i]}; delete array[2] ; print "delete after ...";for(i in array){print array[i]}}' delete befor... 1 2 3 delete after ... 1 2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号