
数据挖掘技术
1. 相关性
相关性是指两个或多个变量因素的相关密切程度。
相关性分析用于确定数据之间的变化情况,即其中一个属性或几个属性的变化是否会对其他属性造成影响,影响有多大。
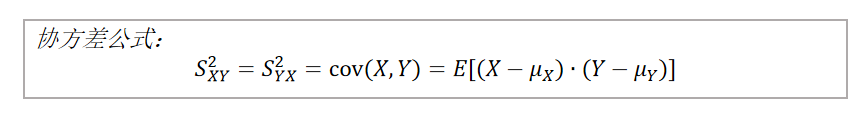
协方差是对两个随机变量X和Y,每个时刻的“X值与其均值之差”乘以“Y值与其均值之差”得到一个乘积,再对这每个时刻的乘积求和并求出平均值。
协方差为正,说明X和Y 是同向变化,协方差越大说明同向程度越高。
协方差为负,说明X和Y 是反向变化,协方差越小说明反向程度越高。
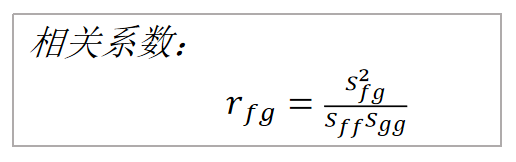
相关系数是标准化后的协方差。相关系数也可以反映两个变量的变化是同向还是反向,如果同向变化就为正,反向变化就为负。而且相关系数消除了两个变量变化幅度的影响,只是单纯反映两个随机变量每单位变化时的相似程度。
完全正相关:相关系数为1,说明两个变量变化时的正向相似度最大。
完全负相关:相关系数为-1,说明两个变量变化时的反向相似度最大。
2. K-means聚类
K-means聚类,又称K均值聚类。具体过程如下:
(1)首先随机选取样本中的K个点作为聚类中心;
(2)分别算出样本中其他样本距离这K个聚类中心的距离,并把这些样本分别作为自己最近的那个聚类中心的类别;
(3)对上述分类完的样本再进行每个类别求平均值,求解出新的聚类质心;
(4)与前一次计算得到的K个聚类质心比较,如果聚类质心发生变化,则跳转至步骤(2),否则跳转至步骤(5);
(5)当质心不发生变化时(当我们找到一个质心,在每次迭代中被分配到这个质心上的样本都是一致的,即每次新生成的簇都是一致的,所有的样本点都不会再从一个簇转移到另一个簇,质心就不会变化了),停止并输出聚类结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号