mongoDB--CURD
mogoDB CURD
添加文档
db.User.insert({name:'zhangsan',age:21,sex:true})
db.User.find()
MongoDB默认为每一个文档生成一个ObjectId类型的主键(_id)。
ObjectId使用12字节的存储空间,每个字节二位十六进制数字,是一个24位的字符串;
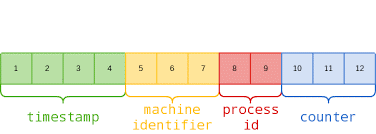
- 时间戳:时间不断变化的
- 机器:主机的唯一标识码。通常是机器主机名的散列值,这样可以确保不同主机生成不同的Objectld ,不产生冲突。
- PID:为了确保在同一台机器上并发的多个进程产生的Objectld是唯一的,所以加上进程标识符(PID).
- 计数器:后3个字节就是一个自动增加的计数器,确保相同进程同一秒产生的Objectld也是不一样。
查询文档
WHERE
# select * from User where name = 'lucy'
db.User.find({name:"lucy"})
FIELDS
# select name, age from User where age = 20
db.User.find({age:20}, {'name':1, 'age':1})
SORT
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列。
# select * from User order by age
db.User.find().sort({age:1})
分页
在 MongoDB 中使用 skip()方法来跳过指定数量的数据,limit()方法来读取指定数量的数据。
select * from User limit 3
db.User.find().skip(0).limit(3)
IN
# select * from User where age in (21, 26, 32)
db.User.find({age:{$in:[21,26,32]}})
COUNT
# select count(*) from User where age >20
db.User.find({age:{$gt:20}}).count()
OR
# select * from User where age = 20 or age = 30
db.User.find({$or:[{age:20}, {age:30}]})
更新文档
db.User.updateMany({name:'jack'},{$set:{age:18,addr:'tangshan'}})
删除文档
remove()用于删除单个或全部文档,删除后的文档无法恢复
//移除对应id的行
db.User.remove(id)
//移除所有
db.User.remove({})
aggregate聚合
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
统计各个年龄的人数:
# select age ,count(*) from User group by age ;
db.User.aggregate([{$group:{_id:'$age',ucount:{$sum:1}}}])
索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构。
db.User.createIndex({"name":1})
语法中 name值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号