ML 激励函数 Activation Function (整理)
本文为内容整理,原文请看url链接,感谢几位博主知识来源
一、什么是激励函数
激励函数一般用于神经网络的层与层之间,上一层的输出通过激励函数的转换之后输入到下一层中。神经网络模型是非线性的,如果没有使用激励函数,那么每一层实际上都相当于矩阵相乘。经过非线性的激励函数作用,使得神经网络有了更多的表现力。
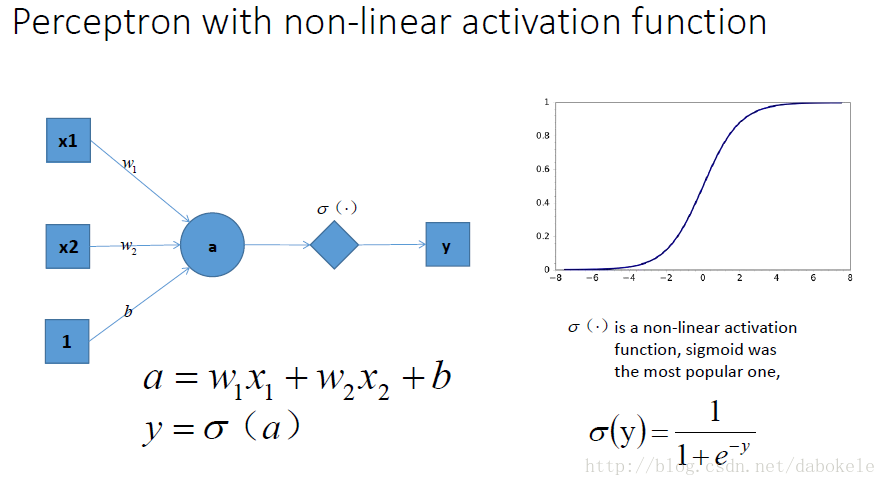
这是一个单层的感知机, 也是我们最常用的神经网络组成单元啦. 用它可以划出一条线, 把平面分割开
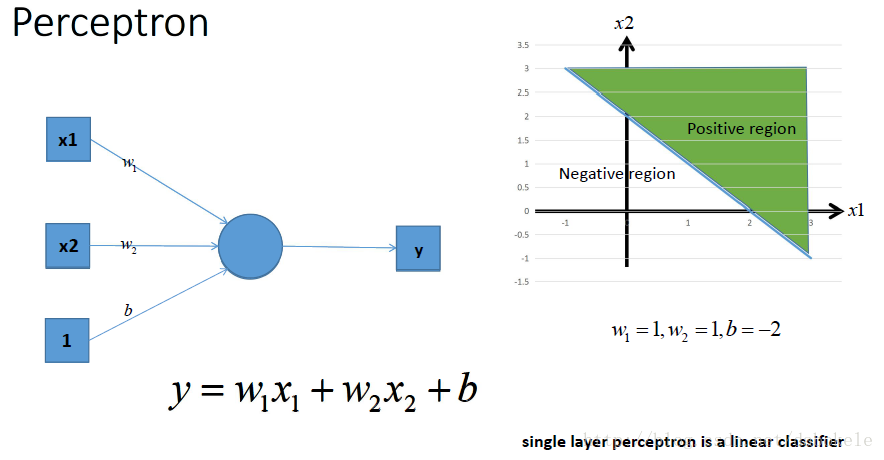
那么很容易地我们就会想用多个感知机来进行组合, 获得更强的分类能力, 这是没问题的啦~~
如图所示,
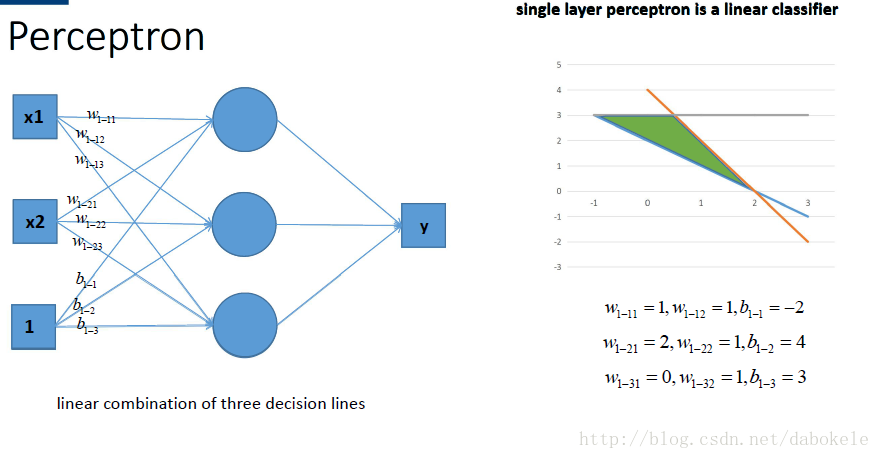
那么我们动笔算一算, 就可以发现, 这样一个神经网络组合起来,输出的时候无论如何都还是一个线性方程哎~纳尼, 说好的非线性分类呢~!!!!???
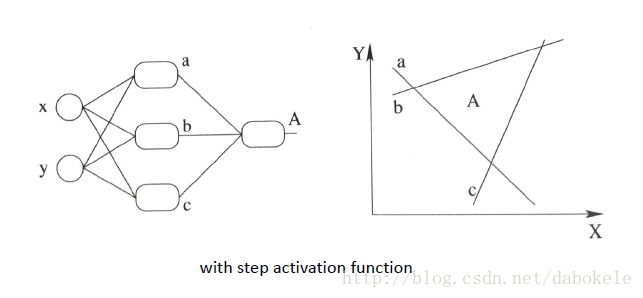
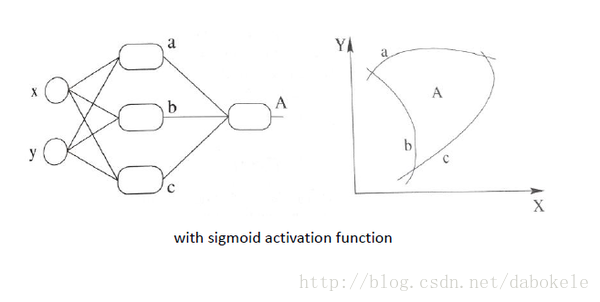
再盗用一幅经常在课堂上用的图…然而我已经不知道出处是哪了, 好像好多老师都是直接用的, 那我就不客气了嘿嘿嘿~,这幅图就跟前面的图一样, 描述了当我们直接使用step activation function的时候所能获得的分类器, 其实只能还是线性的, 最多不过是复杂的线性组合罢了,当然你可以说我们可以用无限条直线去逼近一条曲线啊……额,当然可以, 不过比起用non-linear的activation function来说就太傻了嘛….
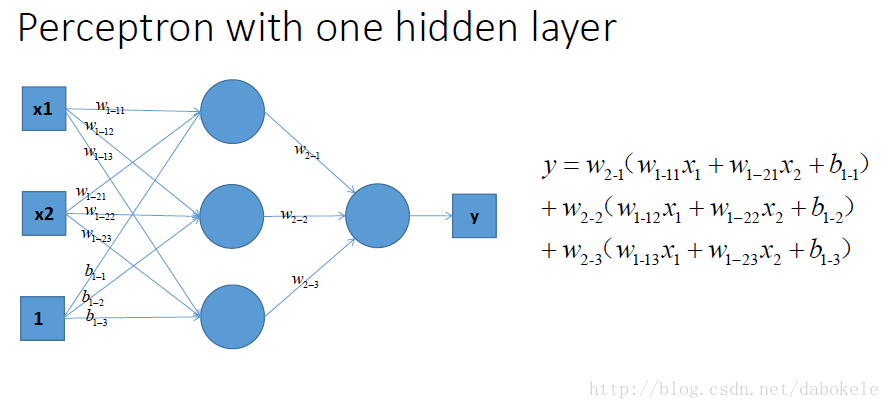
祭出主菜. 题主问的激励函数作用是什么, 就在这里了!!
我们在每一层叠加完了以后, 加一个激活函数, 如图中的y
. 这样输出的就是一个不折不扣的非线性函数!
于是就很容易拓展到多层的情况啦, 更刚刚一样的结构, 加上non-linear activation function之后, 输出就变成了一个复杂的, 复杂的, 超级复杂的函数….额别问我他会长成什么样, 没人知道的~我们只能说, 有了这样的非线性激活函数以后, 神经网络的表达能力更加强大了~(比起纯线性组合, 那是必须得啊!)
继续厚颜无耻地放一张跟之前那副图并列的图, 加上非线性激活函数之后, 我们就有可能学习到这样的平滑分类平面. 这个比刚刚那个看起来牛逼多了有木有!

二、不同激励函数的公式和图形
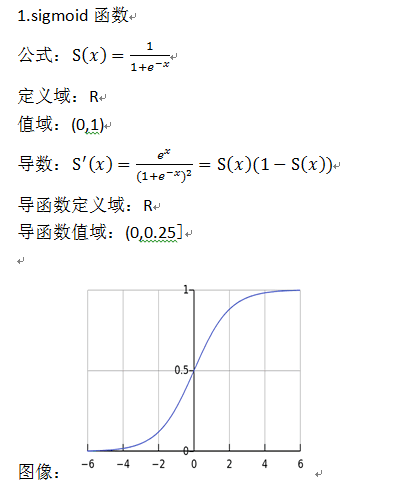
1、Sigmoid函数
Sigmoid函数公式如下
函数图形如下:
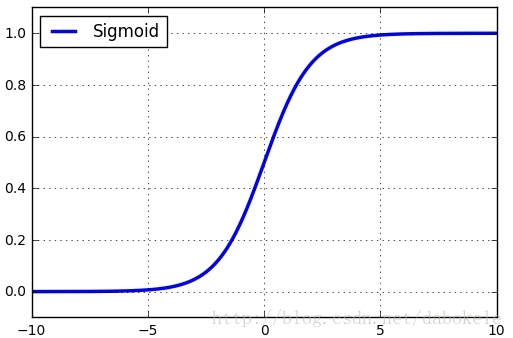
观察函数图形可以看到,Sigmoid函数将输入值归一化到(0, 1)之间。
Sigmoid函数导数公式如下
函数图形如下:
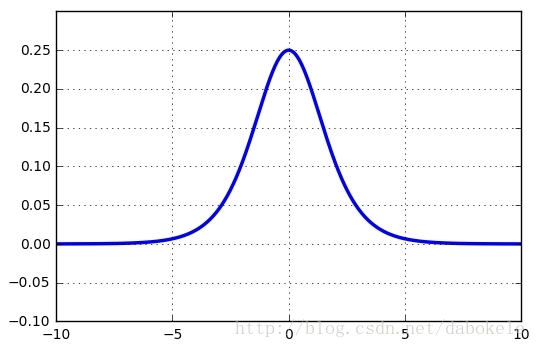
Sigmoid函数有三个缺点:
(1)Saturated neurons “kill” the gradients
在一些误差反向传播的场景下。首先会计算输出层的loss,然后将该loss以导数的形式不断向上一层神经网络传递,调整参数。使用Sigmoid函数的话,很容易导致loss导数变为0,从而失去优化参数的功能。
并且Sigmoid函数的导数最大值为0.25,该误差经过多层神经网络后,会快速衰减到0。
(2)Sigmoid outputs are not zero-centered
Sigmoid函数的输出值恒大于零,那么下一层神经网络的输入x恒大于零。
对上面这个公式来说,w上的gradient将会全部大于零或者全部小于零。这会导致模型训练的收敛速度变慢。
如下图所示,当输入值均为正数时,会导致按红色箭头所示的阶梯式更新。
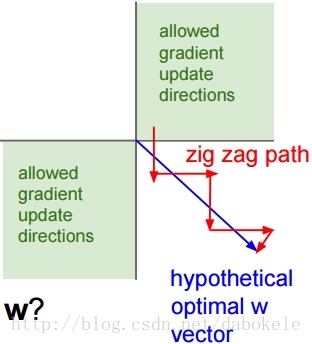
(3)exp() is a bit compute expensive
最后,Sigmoid函数中的指数运算也是一个比较消耗计算资源的过程。
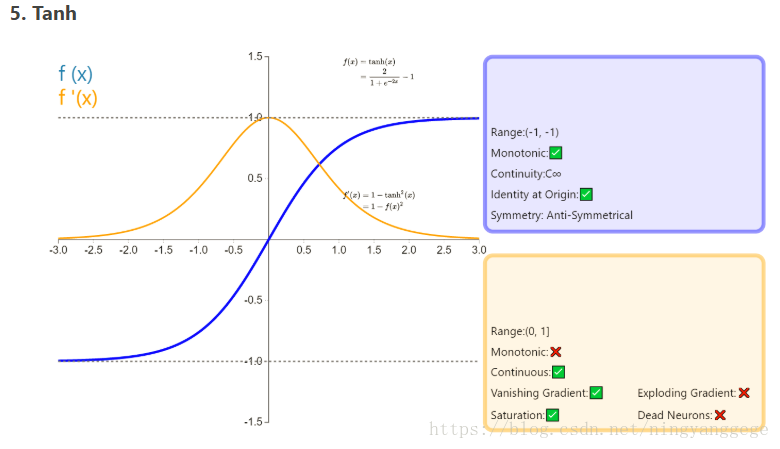
2、Tanh函数
接下来的Tanh函数基于Sigmoid函数进行了一些优化,克服了Sigmoid的not zero-centered的缺点。Tanh函数公式如下:
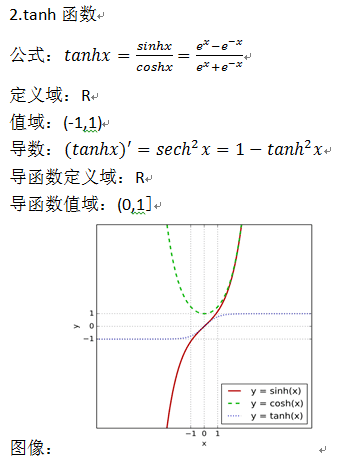
Sigmoid函数和Tanh函数之间的关系如下:

所以,对应于sigmoid的取值范围(0, 1),tanh的取值范围为(0, 1)。将两个函数图像画在同一坐标系中,如下图所示:

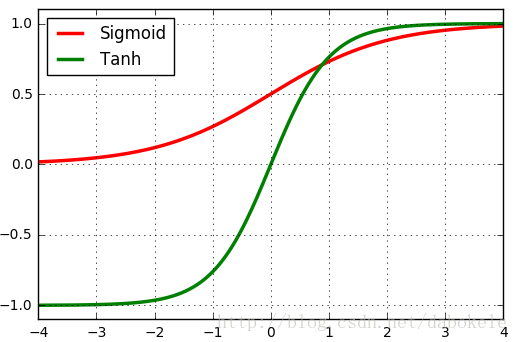
它们之间存在的细微差别
观察sigmoid和tanh的函数曲线,sigmoid在输入处于[-1,1]之间时,函数值变化敏感,一旦接近或者超出区间就失去敏感性,处于饱和状态,影响神经网络预测的精度值。tanh的输出和输入能够保持非线性单调上升和下降关系,符合BP网络的梯度求解,容错性好,有界,渐进于0、1,符合人脑神经饱和的规律,但比sigmoid函数延迟了饱和期。
3、ReLU函数
ReLU函数公式如下所示:
对应函数图形如下:
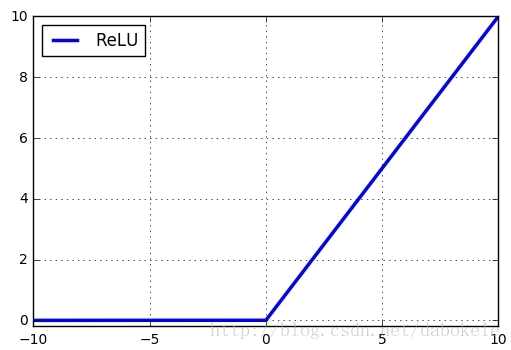
该函数在输入小于0时输出值恒为0,在输入大于0时,输出线性增长。
ReLU函数没有Sigmoid函数及Tanh函数中的指数运算,并且也没有”kill” gradients的现象。
但是ReLU函数也有以下几个不足之处:
(1)not zero-centered
这个与Sigmoid类似,从函数图形就可以看出。
(2)dead relu
这里指的是某些神经元可能永远不会被激活,导致对应的参数永远不会被更新。
比如说一个非常大的Gradient流过ReLU神经元,可能会导致参数更新后该神经元再也不会被激活。
当学习率过大时,可能会导致大部分神经元出现dead状况。所以使用该激活函数时应该避免学习率设置的过大。另外一种比较少见的情况是,某些初始化参数也会导致一些神经元出现dead状况。
4、Softplus函数
Softplus函数公式如下,
Sζ(x)=ln(1+exp(x)).
通过观察该公式可以发现Softplus函数是Sigmoid函数的原函数。
Softplus函数与ReLU函数的图形对比如下图所示,
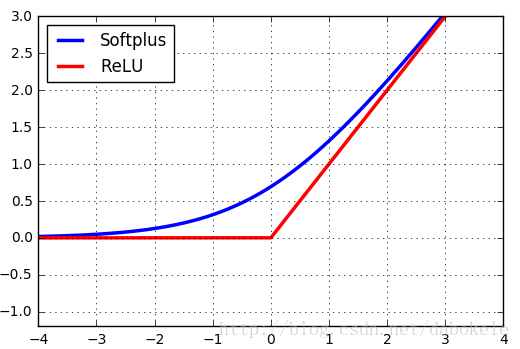
在这里之所以将Softplus函数与ReLU函数的图形放在一起进行比较,是因为Softplus函数可以看成是ReLU函数的平滑版本。
并且,Softplus函数是对全部数据进行了非线性映射,是一种不饱和的非线性函数其表达式如公式,Softplus函数不具备稀疏表达的能力,收敛速度比ReLUs函数要慢很多。但该函数连续可微并且变化平缓,比Sigmoid函数更加接近生物学的激活特性,同时解决了Sigmoid函数的假饱和现象,易于网络训练和泛化性能的提高。虽然该函数的表达性能更优于ReLU函数和Sigmoid函数,即精确度相对于后者有所提高,但是其并没有加速神经网络的学习速度。
softplus函数可以用来产生正态分布的β和σ参数,因为它的范围是(0,∞)。当处理包含sigmoid函数的表达式时它也经常出现。softplus函数名字来源于它是另外一个函数的平滑(或”软化”)形式,这个函数是x+=max(0,x)。softplus 是对 ReLU 的平滑逼近的解析函数形式。
softplus函数别设计成正部函数(positive part function)的平滑版本,这个正部函数是指x+=max{0,x}。与正部函数相对的是负部函数(negative part function)x-=max{0, -x}。为了获得类似负部函数的一个平滑函数,我们可以使用ζ(-x)。就像x可以用它的正部和负部通过等式x+-x-=x恢复一样,我们也可以用同样的方式对ζ(x)和ζ(-x)进行操作,就像下式中那样:ζ(x) -ζ(-x)=x.
Rectifier:In the context of artificial neural networks, the rectifier is an activation function defined as:
f(x)=max(0,x)
where x is the input to a neuron. This activation function was first introduced to a dynamical network by Hahnloser et al. in a 2000 paper in Nature. It has been used in convolutional networks more effectively than the widely used logistic sigmoid (which is inspired by probability theory; see logistic regression) and its more practical counterpart, the hyperbolic tangent. The rectifier is, as of 2015, the most popular activation function for deep neural networks.
A unit employing the rectifier is also called a rectified linear unit (ReLU).
A smooth approximation to the rectifier is the analytic function: f(x)=ln(1+ex), which is called the softplus function. The derivative of softplus is: f’(x)=ex/(ex+1)=1/(1+e-x), i.e. the logistic function.
Rectified linear units(ReLU) find applications in computer vision and speech recognition using deep neural nets.
Noisy ReLUs: Rectified linear units can be extended to include Gaussian noise, making them noisy ReLUs, giving: f(x)=max(0, x+Y), with Y∽N(0, σ(x)). Noisy ReLUs have been used with some success in restricted Boltzmann machines for computer vision tasks.
Leaky ReLUs:allow a small, non-zero gradient when the unit is not active:
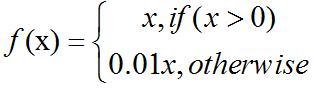
Parametric ReLUs take this idea further by making the coefficient of leakage into a parameter that is learned along with the other neural network parameters:
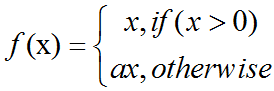
Note that for a≤1, this is equivalent to: f(x)=max(x, ax), and thus has a relation to "maxout" networks.
ELUs:Exponential linear units try to make the mean activations closer to zero which speeds up learning. It has been shown that ELUs can obtain higher classification accuracy than ReLUs:
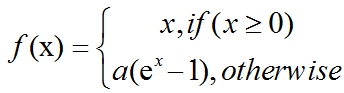
a is a hyper-parameter to be tuned and a≥0 is a constraint.
5、Softsign函数
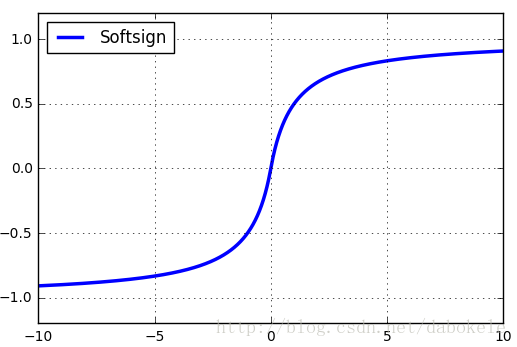
和tanh函数比较研究下:
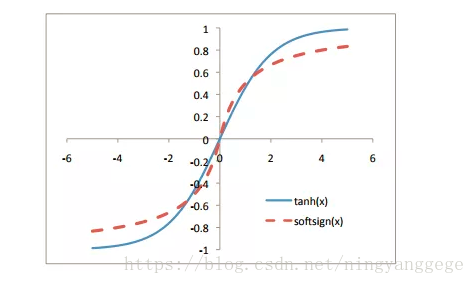
容易看出tanh比softsign更容易饱和
softsign的导数
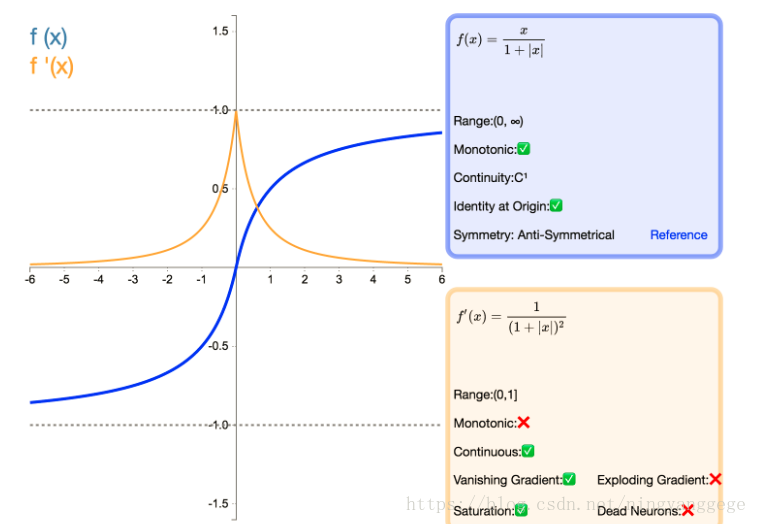
tanh的导数:
Softsign 是 Tanh 激活函数的另一个替代选择。
就像 Tanh 一样,Softsign 是反对称、去中心、可微分,并返回-1 和 1 之间的值。
其更平坦的曲线与更慢的下降导数表明它可以更高效地学习,比tanh更好的解决梯度消失的问题。另一方面,导数的计算比 Tanh 更麻烦;
在实践中,可以深度用softsign替代tanh激活函数
三、Tensorflow中提供的激励函数
在Tensorflow r1.0中提供了以下几种激励函数,其中包括连续非线性的(比如sigmoid, tanh, elu, softplus, softsign),连续但是并不是处处可微分的(relu, relu6, crelu, relu_x)以及随机函数(dropout)。
tf.nn.relu
tf.nn.relu6
tf.nn.crelu
tf.nn.elu
tf.nn.softplus
tf.nn.softsign
tf.nn.dropout
tf.nn.bias_add
tf.sigmoid
tf.tanh
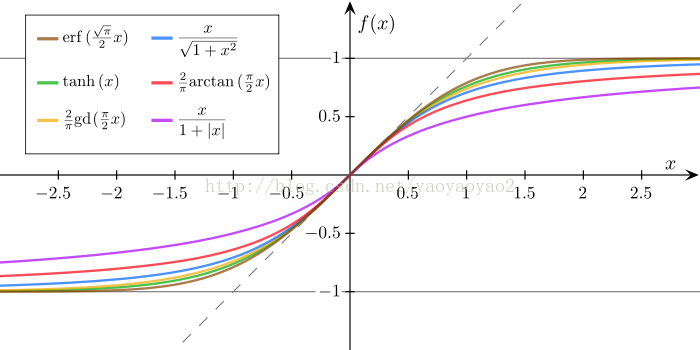
其他常见的值域在[-1, 1]的函数
来源: (1 ) https://www.zhihu.com/question/22334626/answer/103835591
( 2 ) https://blog.csdn.net/fengbingchun/article/details/73872828
( 3 ) https://blog.csdn.net/yaoyaoyao2/article/details/73848983
( 4 ) https://blog.csdn.net/ningyanggege/article/details/80665888

 浙公网安备 33010602011771号
浙公网安备 33010602011771号