

数据库(四)DQL
前言
本文为在霍格沃兹测试开发学社的学习经历分享,希望有志同道合的小伙伴可以一起交流技术,一起进步~
DQL查询语言
单表查询
语法:
select * from 表名;
- 字段查询
select 列名 from 表名;
- 起别名

- 去掉重复信息
select distinct 列名 from 表名;
注意:distinct要放在想要去重的列名前,如果distinct后面有多个列名,那都会生效,所以不想要去重的列需要放在distinct前
- 运算查询
语法
select (列名 运算表达式) from 表名;
- 条件查询语法:
SELECT 列名 FROM 表名 WHERE 条件表达式
比较运算符

示例:
use employees;
-- 查询出生日期晚于1965-01-01的员工编号,姓名,生日
SELECT
emp_no,
first_name,
last_name,
hire_date
FROM
employees
WHERE
hire_date > '1965-01-01';
使用between模糊查询

示例:
-- 查询年薪在70000-70003之间的员工编号及薪资
SELECT
emp_no,
salary
FROM
salaries
WHERE
salary BETWEEN 70000
AND 70003;
- 注意: 小数在前,大数在后
使用in模糊查询

示例:
-- 查询入职日期为1995-01-01 和1995-03-02的员工信息
SELECT
*
FROM
employees
WHERE
hire_date IN ( '1995-01-01', '1995-03-02' );
判断是否为空
语法:WHERE <列名> IS [NOT] NULL
-- 查询年龄为空的数据
SELECT * FROM user WHERE age is null;
逻辑运算符

-- 查询名字为Lillian并且姓氏为Haddadi的员工信息
SELECT
*
FROM
employees
WHERE
first_name = 'Lillian'
AND last_name = 'Haddadi';
-- 查询名字为Lillian 或者姓氏为Terkki的员工信息
SELECT
*
FROM
employees
WHERE
first_name = 'Lillian'
or last_name = 'Terkki';
-- 查询名字为Lillian 并且性别不是女的员工信息
SELECT
*
FROM
employees
WHERE
first_name = 'Lillian'
and not gender='F';
通配符

-- 查询名字中包含fai的员工信息
SELECT * from employees where first_name like '%fai%';
-- 查询名字中fa开头的,名字长度为3位的员工信息
SELECT * from employees where first_name like 'fa_';
排序
排序语法:

- 排序的运行速度一般较慢
单列排序
-- 使用salary字段,对salaries表数据进行升序排序
SELECT * from salaries ORDER BY salary;
-- 使用salary字段,对salaries表数据进行降序排序
SELECT * from salaries ORDER BY salary desc;
-- 查询员工的编号和入职日期,按照员工入职日期从晚到早排序
SELECT
emp_no,
hire_date
FROM
employees
ORDER BY
hire_date DESC;
组合排序

-- 在入职时间排序的基础上,再使用 emp_no 进行降序排序
SELECT
emp_no,
hire_date
FROM
employees
ORDER BY
hire_date DESC, emp_no DESC;
分组查询
一般会与聚合函数一起使用

-- 查询每个员工的薪资和
select emp_no,sum(salary) from salaries GROUP BY emp_no;
-- 查询员工编号小于10010的,薪资和小于400000的员工薪资和
select emp_no,sum(salary) from salaries where emp_no<10010 GROUP BY emp_no having sum(salary)<400000;
子句区别
-
where子句:从数据源种去掉不符合其搜索条件的数据,是对不符合搜索条件的数据进行剔除,是在分组前的
-
group by子句:搜集数据行到各个组中,统计函数为各个组计算统计值
-
having子句:去掉不符合组搜索条件的各行数据行
limit关键字限制查询结果行数

- 注意:只能在mysql中使用该关键字
-- 展示前十条员工信息
select * from employees limit 10;
select * from employees limit 10 OFFSET 0;
-- 显示年薪从高到低排序,第15位到第20位员工的编号和年薪
select emp_no ,salary from salaries ORDER BY salary Desc limit 14,6;
总结
-- 基础查询语法
select distinct <列名>
from <表名>
where <查询条件表达式>
group by <分组的列名>
having <分组后的查询条件表达式>
order by <排序的列名> [ASC/DESC]
limit [开始的行数],<查询记录的条数>
sql语法执行顺序
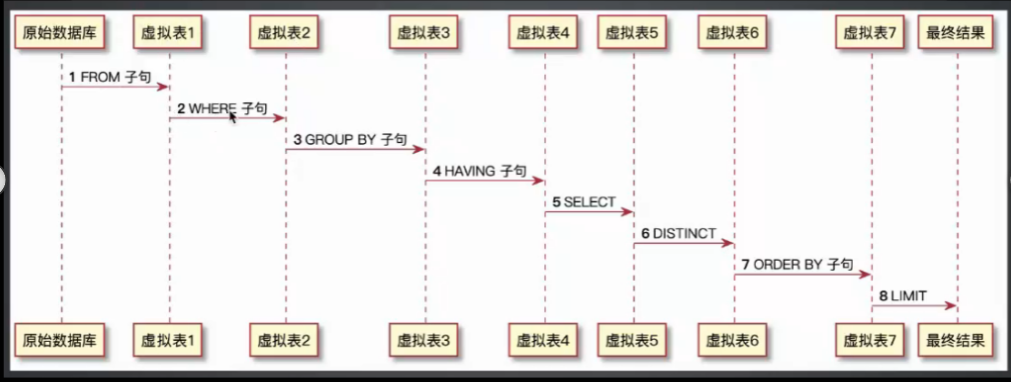
推荐阅读文章链接:接口测试经典面试题:Session、cookie、token有什么区别?_霍格沃兹测试开发学社的博客-CSDN博客

 浙公网安备 33010602011771号
浙公网安备 33010602011771号