Axis in DataFrame
Axis in DataFrame
Optional parameter axis may appear in arithmetric between DataFrame and Series,the key point understanding the meaning of axis is match,by default the index of series shall match columns of DataFrame,broadcasting down the rows;And axis may also appear in apply(),max(),mean() or so kind of DataFrame object method,by default, axis='index',meaning find the max one among index,and that is to find the max one of every column.Please note that,apply() is not identical to applymap().apply(f) will perform f function on one-dimentional array(index or columns),by default,axis='index' while applymap(f) will perform f function on element-wise for DataFrame.
import pandas as pd
import numpy as np
frame=pd.DataFrame(np.random.randn(4,3),index=['Utah','Ohio','Texas','Oregon'],columns=list('bde'));frame
| b | d | e | |
|---|---|---|---|
| Utah | -0.311649 | 0.252285 | -0.741715 |
| Ohio | 0.351583 | 1.287569 | 0.726872 |
| Texas | 0.605527 | -0.186660 | -0.993184 |
| Oregon | 1.577405 | 0.381833 | 1.607757 |
frame['b']
Utah -0.311649
Ohio 0.351583
Texas 0.605527
Oregon 1.577405
Name: b, dtype: float64
series1=frame.iloc[0];series1
b -0.311649
d 0.252285
e -0.741715
Name: Utah, dtype: float64
frame.sub(series1,axis='columns') # By default,arithmetic between DataFrame and Series matches the index of Series on the DataFrame's columns,broadcasting down the rows.
| b | d | e | |
|---|---|---|---|
| Utah | 0.000000 | 0.000000 | 0.000000 |
| Ohio | 0.663232 | 1.035284 | 1.468587 |
| Texas | 0.917176 | -0.438944 | -0.251470 |
| Oregon | 1.889054 | 0.129548 | 2.349471 |
frame.sub(series1,axis=1) # The same with above
| b | d | e | |
|---|---|---|---|
| Utah | 0.000000 | 0.000000 | 0.000000 |
| Ohio | 0.663232 | 1.035284 | 1.468587 |
| Texas | 0.917176 | -0.438944 | -0.251470 |
| Oregon | 1.889054 | 0.129548 | 2.349471 |
series2=frame['d'];series2
Utah 0.252285
Ohio 1.287569
Texas -0.186660
Oregon 0.381833
Name: d, dtype: float64
frame.sub(series2,axis='index') # Must set axis='index',so that broadcasts down on column.
| b | d | e | |
|---|---|---|---|
| Utah | -0.563934 | 0.0 | -0.993999 |
| Ohio | -0.935986 | 0.0 | -0.560697 |
| Texas | 0.792186 | 0.0 | -0.806525 |
| Oregon | 1.195572 | 0.0 | 1.225924 |
frame.max(axis='index') # max() default to set axis='index',meaning find the max one among 'index',not every max one of every index.
b 1.577405
d 1.287569
e 1.607757
dtype: float64
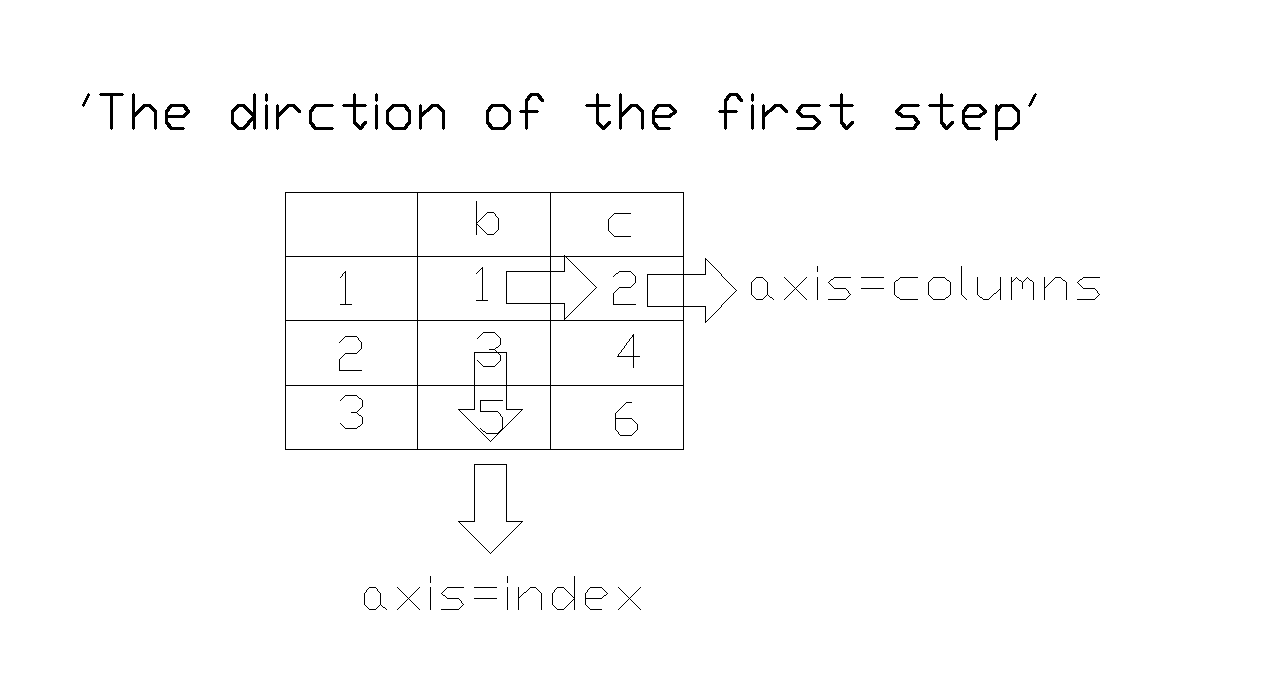
Summary:no matter arithmetic between df and series,and df object method, the operation steps can be divided into 2 setps,firstly, finding the direction of elementwise level operation,and then reapeating this process along the other direction.
df1=pd.DataFrame(np.arange(12).reshape(3,4));df1
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
df1.sub(df1.loc[1],axis=1)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | -4 | -4 | -4 | -4 |
| 1 | 0 | 0 | 0 | 0 |
| 2 | 4 | 4 | 4 | 4 |
df1.sub(df1[1],axis=0)
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | -1 | 0 | 1 | 2 |
| 1 | -1 | 0 | 1 | 2 |
| 2 | -1 | 0 | 1 | 2 |
df1.max(axis=0)
0 8
1 9
2 10
3 11
dtype: int32
df1.max(axis=1)
0 3
1 7
2 11
dtype: int32
The same rule can also be applied to np.concatenate() and pd.concat(),pd.DataFrame.any(),pd.DataFrame.all()
Signature: pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
Docstring:
Concatenate pandas objects along a particular axis with optional set logic
along the other axes. Can also add a layer of hierarchical indexing on the
concatenation axis, which may be useful if the labels are the same (or
overlapping) on the passed axis number
Parameters
objs : a sequence or mapping of Series, DataFrame, or Panel objects
If a dict is passed, the sorted keys will be used as the keys
argument, unless it is passed, in which case the values will be
selected (see below). Any None objects will be dropped silently unless
they are all None in which case a ValueError will be raised
axis : {0/'index', 1/'columns'}, default 0
The axis to concatenate along
join : {'inner', 'outer'}, default 'outer'
How to handle indexes on other axis(es)
join_axes : list of Index objects
Specific indexes to use for the other n - 1 axes instead of performing
inner/outer set logic
ignore_index : boolean, default False
If True, do not use the index values along the concatenation axis. The
resulting axis will be labeled 0, ..., n - 1. This is useful if you are
concatenating objects where the concatenation axis does not have
meaningful indexing information. Note the index values on the other
axes are still respected in the join.
keys : sequence, default None
If multiple levels passed, should contain tuples. Construct
hierarchical index using the passed keys as the outermost level
levels : list of sequences, default None
Specific levels (unique values) to use for constructing a
MultiIndex. Otherwise they will be inferred from the keys
names : list, default None
Names for the levels in the resulting hierarchical index
verify_integrity : boolean, default False
Check whether the new concatenated axis contains duplicates. This can
be very expensive relative to the actual data concatenation
copy : boolean, default True
If False, do not copy data unnecessarily
Notes
The keys, levels, and names arguments are all optional
Returns
concatenated : type of objects
File: e:\software\anaconda\lib\site-packages\pandas\tools\merge.py
Type: function

 浙公网安备 33010602011771号
浙公网安备 33010602011771号