[Flink/Spark] Apache Stream Park : 一站式的流处理计算开发运管平台
0 序言
- 近期因某项目的部署诉求,需要基于 Stream Park,部署 Flink on k8s。在此学习总结一二。
1 概述:Apache Stream Park
Apache Stream Park
- 在实时处理领域,Apache Spark™ 和 Apache Flink® 代表着巨大的进步,尤其是
Flink,它被广泛视为下一代大数据流计算引擎,而我们在使用 Apache Flink® 和 Apache Spark™ 时发现从编程模型、启动配置到运维管理都存在许多可以抽象和共用的部分,Apache Stream Park开源项目团队将一些优秀经验进行固化并结合业内最佳实践,经过不懈努力最终诞生了:Apache Stream Park™
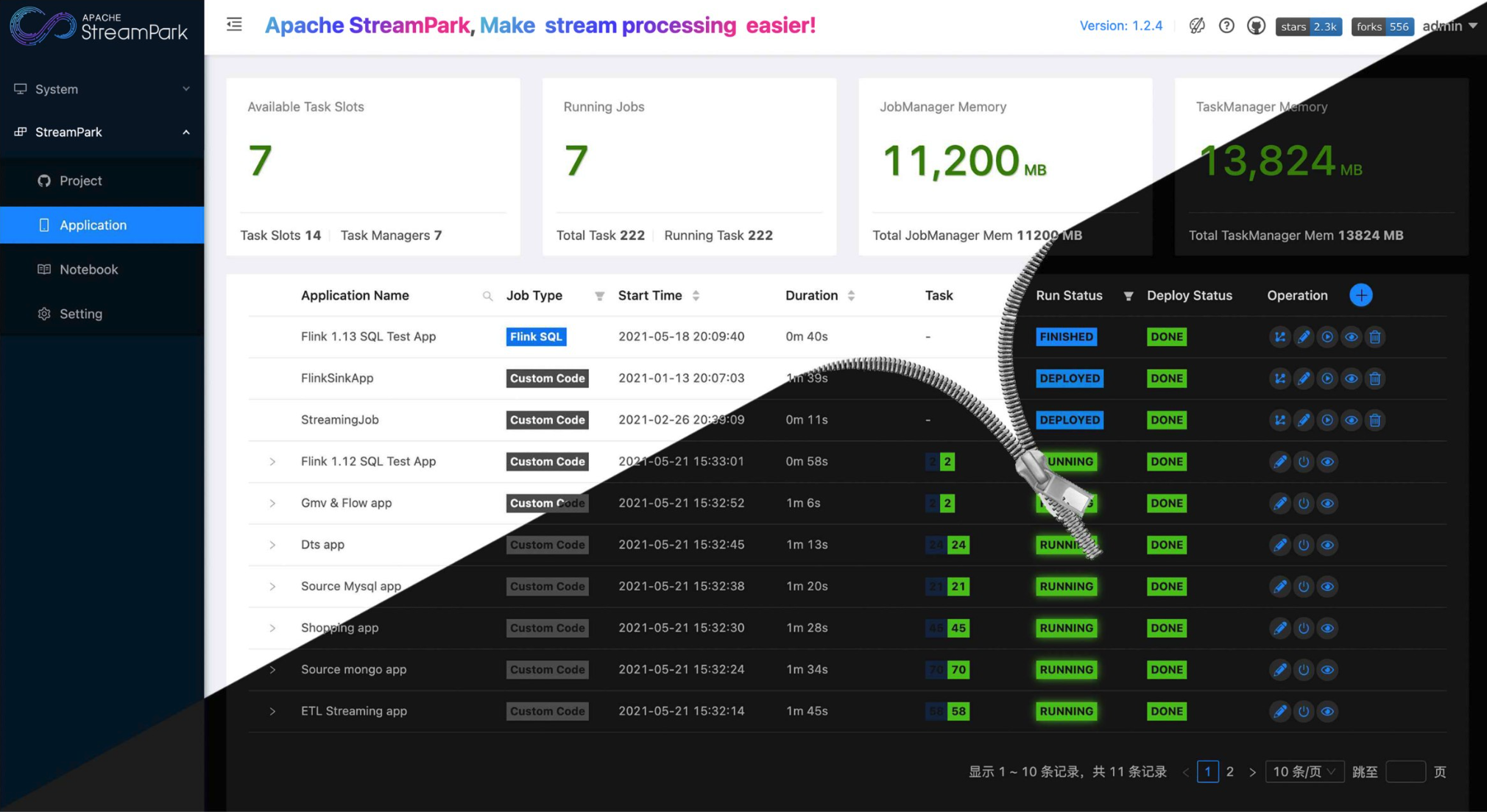
Apache Stream Park™ 是一个一站式的流处理计算平台。规范了项目的配置、鼓励函数式编程、定义了最佳的编程方式,提供了一系列开箱即用的连接器(Connector),标准化了配置、开发、测试、部署、监控、运维的整个过程,提供了 Scala 和 Java 两套接口,并且提供了一个一站式的流处理作业开发管理平台,从流处理作业开发到上线全生命周期都做了支持。
使用 Apache StreamPark™ 开发流处理作业可以显著降低学习成本和开发门槛,让开发者能够专注于核心业务逻辑。。
核心特性
应用程序开发脚手架
- Apache StreamPark™ 提供了一个易于使用的开发框架,使开发者能够高效地构建流处理应用。它支持多种版本的 Apache Flink® 和 Apache Spark™,降低了学习成本和开发门槛,允许开发者专注于核心业务逻辑。
开箱即用的连接器
- Apache Stream Park™ 提供了一系列开箱即用的连接器,简化了与不同数据源和目标的集成。
这些连接器使得数据流的获取和处理变得更加高效,支持多种数据场景。
一站式流处理运维平台
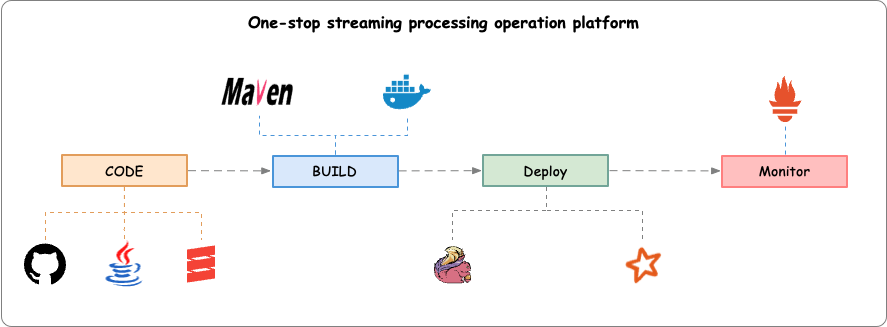
- Apache Stream Park™ 作为一个一站式流处理运维平台,集成了应用的开发、调试、部署和运维管理功能。
它通过
streampark-console提供了低代码平台,方便用户管理 Flink 任务,简化了项目的编译、发布、参数配置等操作。
支持多种场景
- Apache Stream Park™ 支持多种应用场景,包括 Catalog、OLAP 和 Streaming Warehouse 等。这使得用户能够在不同的数据处理需求下灵活应用 Apache Stream Park™,满足实时数据分析和处理的需求。
架构设计
- Apache Stream Park™ 核心由 Stream Park Core 和 Stream Park Console 组成:
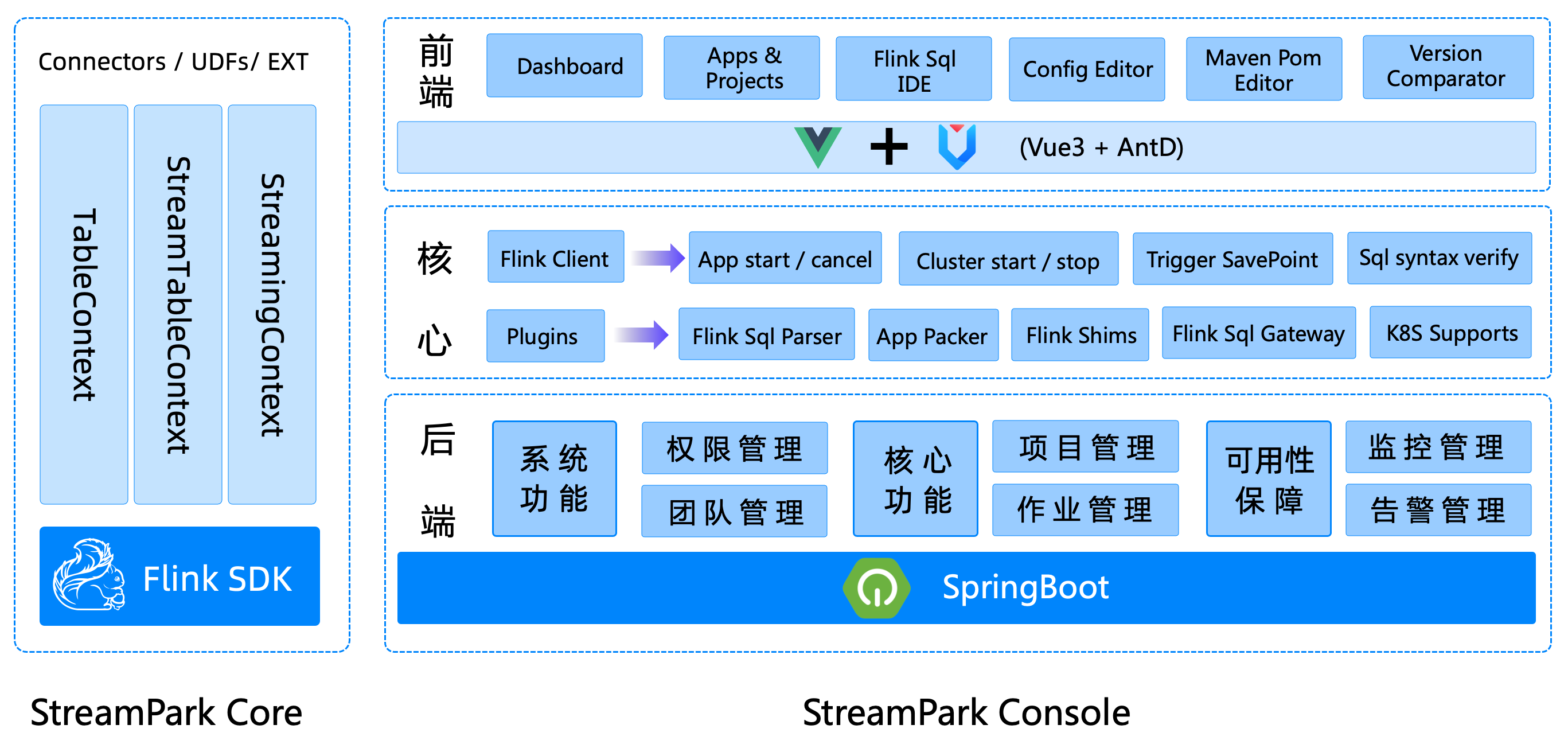
Stream Park Core
- Stream Park Core 定位是一个开发时框架,关注编码开发,规范了配置文件,按照约定优于配置的方式进行开发,提供了一个开发环境的
RuntimeContext和一系列开箱即用的连接器,扩展了 DataStream 相关的方法,融合了 DataStream 和 Flink SQL API,简化繁琐的操作、聚焦业务本身,提高开发效率和开发体验。
StreamPark Console
- Stream Park Console 是一个集实时数据处理与低代码开发于一体的平台,能够高效管理 Flink 任务。
它整合了项目编译、发布、参数配置、启动、保存点、火焰图、Flink SQL 和监控等功能,极大简化了 Flink 任务的日常操作与维护,并融入了众多最佳实践。
该平台使原本只有大公司才能研发和使用的项目,如今人人可得,其【目标】是打造一个实时数仓、流批一体的一式站大数据解决方案。
技术栈
- 该平台使用了以下技术(但不限于):
- Apache Flink
- Apache Spark
- Apache YARN
- Spring Boot
- Mybatis
- Mybatis-Plus
- Vue
- VuePress
- Ant Design of Vue
- ANTD PRO VUE
- xterm.js
- Monaco Editor
- ...
2 快速入门
如果要快速入门 StreamPark,可以 一键安装部署 或者 手动安装部署 。
2.1 一键安装模式
- 如果需要一键安装 StreamPark,直接复制如下命令即可:
curl -L https://streampark.apache.org/quickstart.sh | sh
如果提示如下内容,表示安装部署成功:
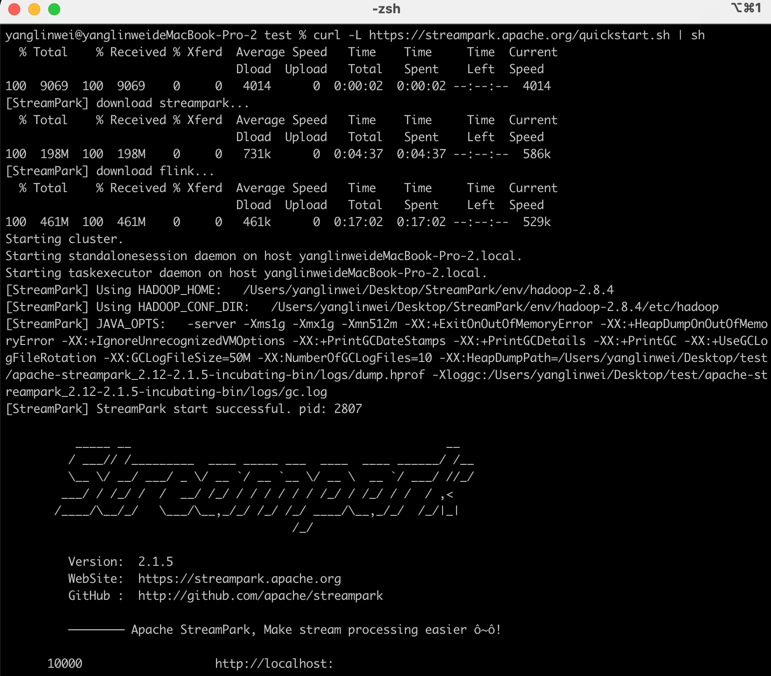
脚本已经帮我们安装好 StreamPark 以及 Flink 集群了,直接登录即可启动作业
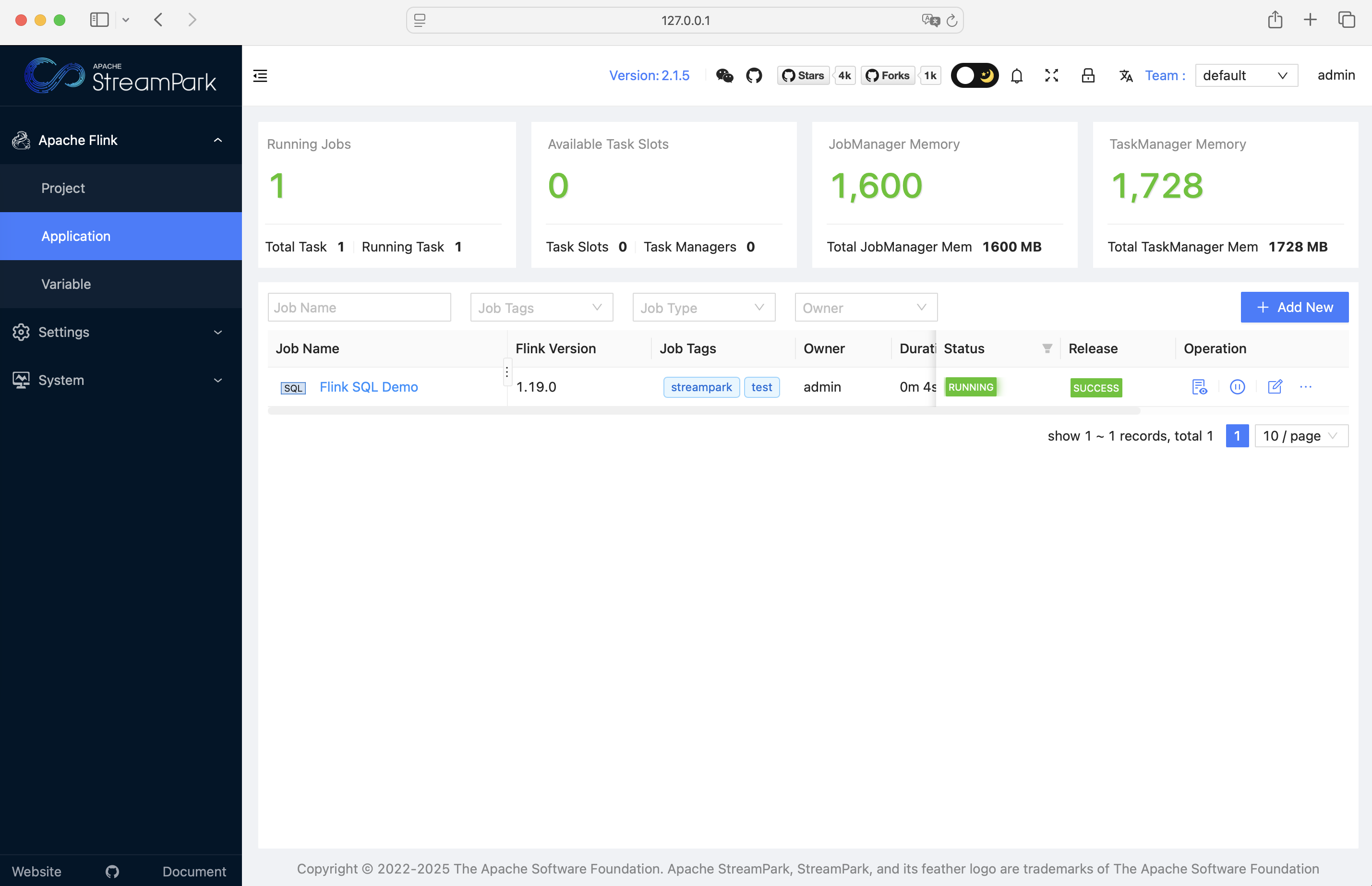
- 登录系统后,点击启动即可启动默认作业。
登录地址: http://127.0.0.1:8081 ,登录账号密码: admin / streampark ):
2.2 手动安装模式
- 只需按照以下三个步骤,即可快速入门StreamPark:
Step1:环境准备
Step2:StreamPark 安装
Step3:部署作业
2.2.1 环境准备
| 物料 | 版本要求 | 演示版本(仅供参考) |
|---|---|---|
| 操作系统 | Linux/MacOS | MacOS |
| Java | JDK version >=1.18 | 1.8.0_362 |
| Scala | Scala version >=2.12 | 2.12.18 |
| Flink | Flink version >= 1.12 | 1.19.0 |
| StreamPark安装包 | 任意版本 | 2.1.5 |
备注:默认用户在本地已经安装好 JDK 以及 Scala 环境。
2.2.2 StreamPark 安装
- 首先,从官网直接下载最新版的 StreamPark,本文使用的是 2.1.5 版本
- 其次,下载完成后,解压到本地的某个目录,进入 bin 目录启动 StreamPark ,相关脚本如下:
# 解压StreamPark安装包.
tar -zxvf apache-streampark_2.12-2.1.5-incubating-bin.tar.gz
# 启动StreamPark.
cd apache-streampark_2.12-2.1.5-incubating-bin/bin
./startup.sh
启动成功后界面如下:
- 登录 Stream Park
地址: http://127.0.0.1:10000 | 账号密码:admin / streampark
2.2.3 部署作业
- 首次登录系统后,会发现已经有一个默认创建好的
FlinkSQL作业。
为了更好地演示,这里使用
Standalone模式来运行这个作业。
在此之前,需要先配置 Flink 版本与关联 Flink 集群。
2.2.3.1 配置 Flink 版本
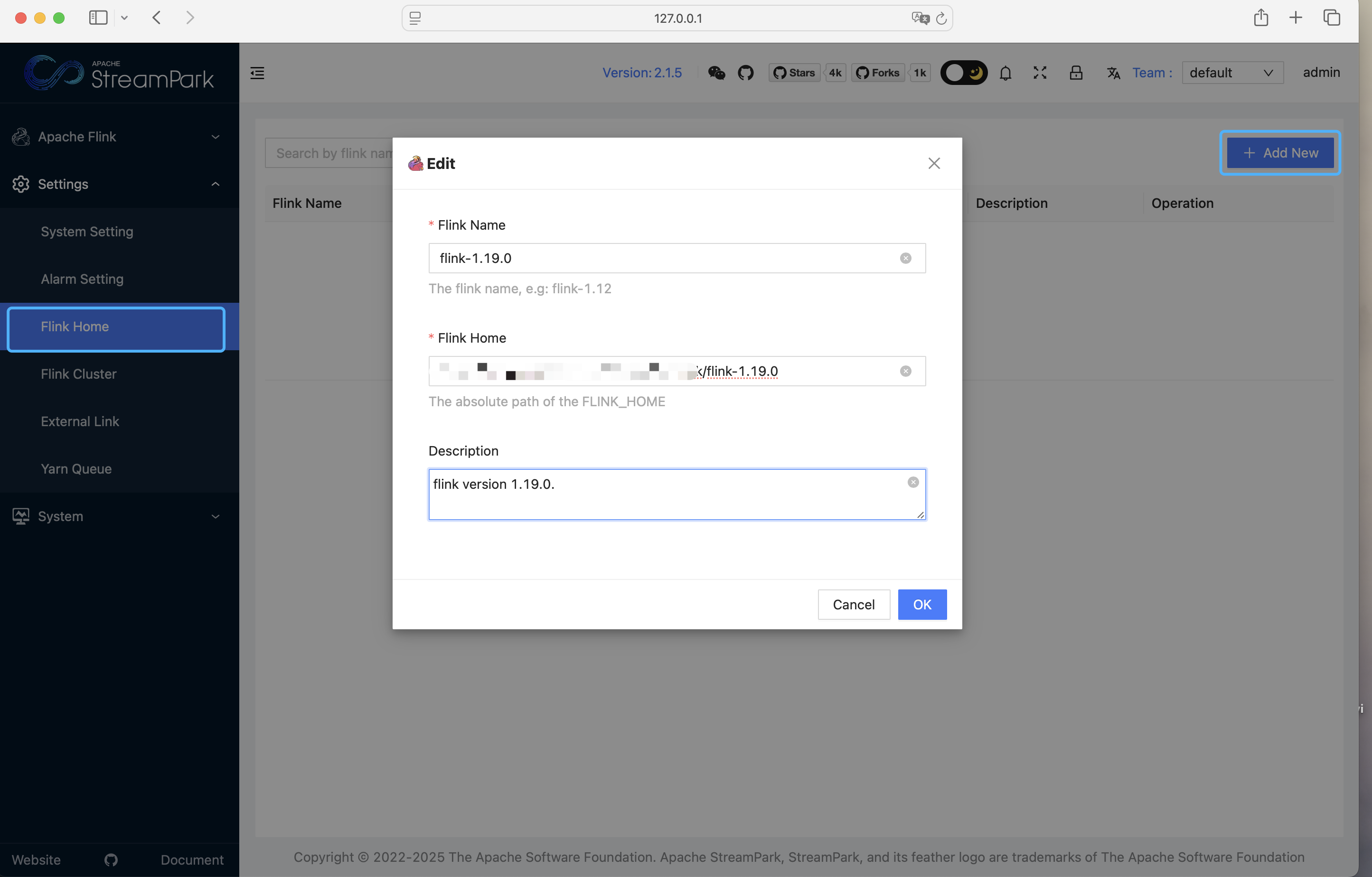
Flink 安装包需要与 StreamPark 服务同在一台服务器。
- 首先,需要配置 Flink 版本,即指定本地
Flink的解压路径。依次点击:设置中心 → Flink Home (Flink 版本) → 新建
2.2.3.2 配置Flink集群
需要确保本地的 Flink 集群已经启动(直接进入 Flink 解压目录下的bin目录,执行
./start-cluster.sh即可)
- 关联Flink集群,依次点击:设置中心 → Flink集群 → 添加
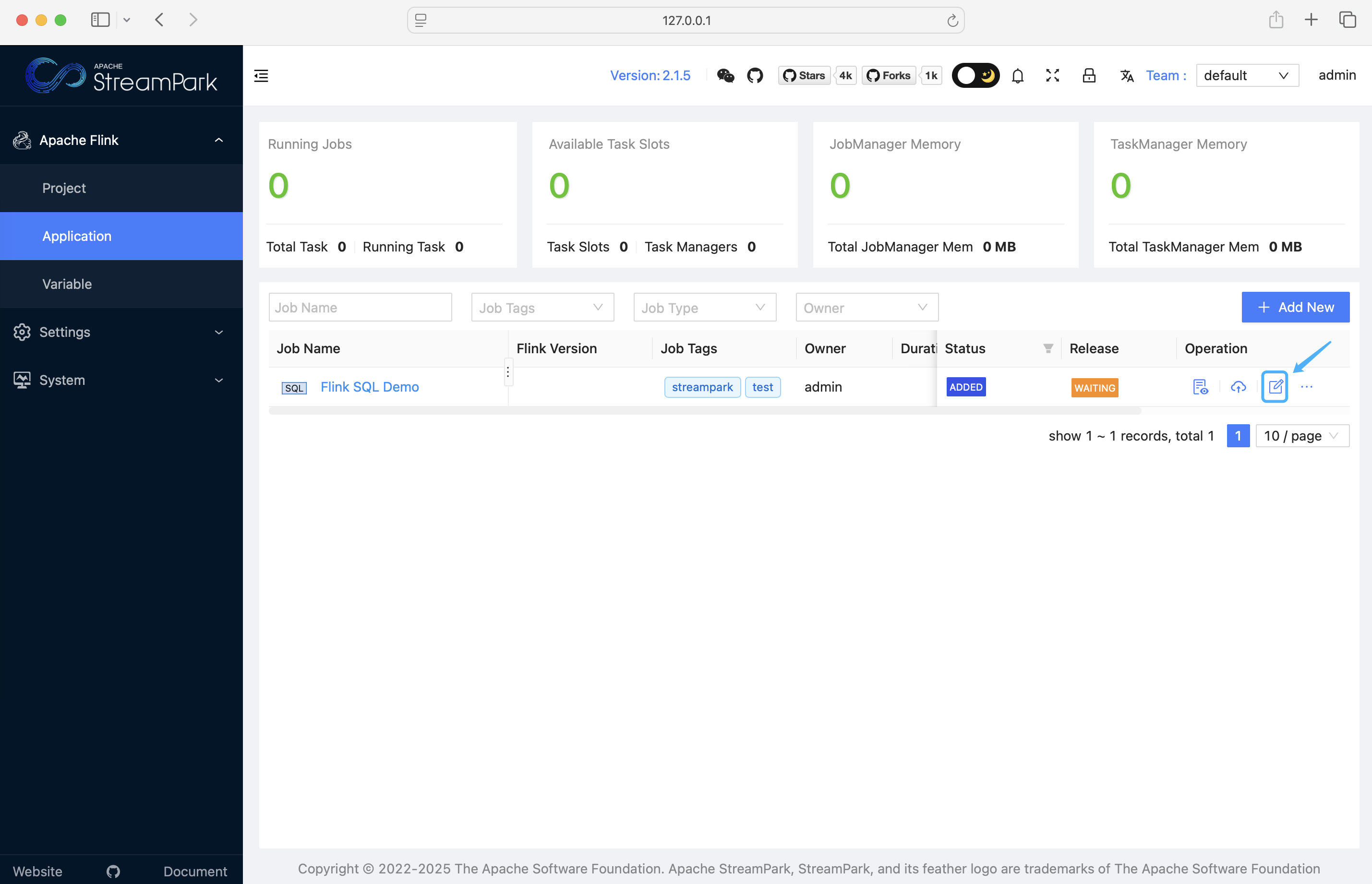
2.2.3.3 配置作业
- 点击作业配置,进入作业配置页面:
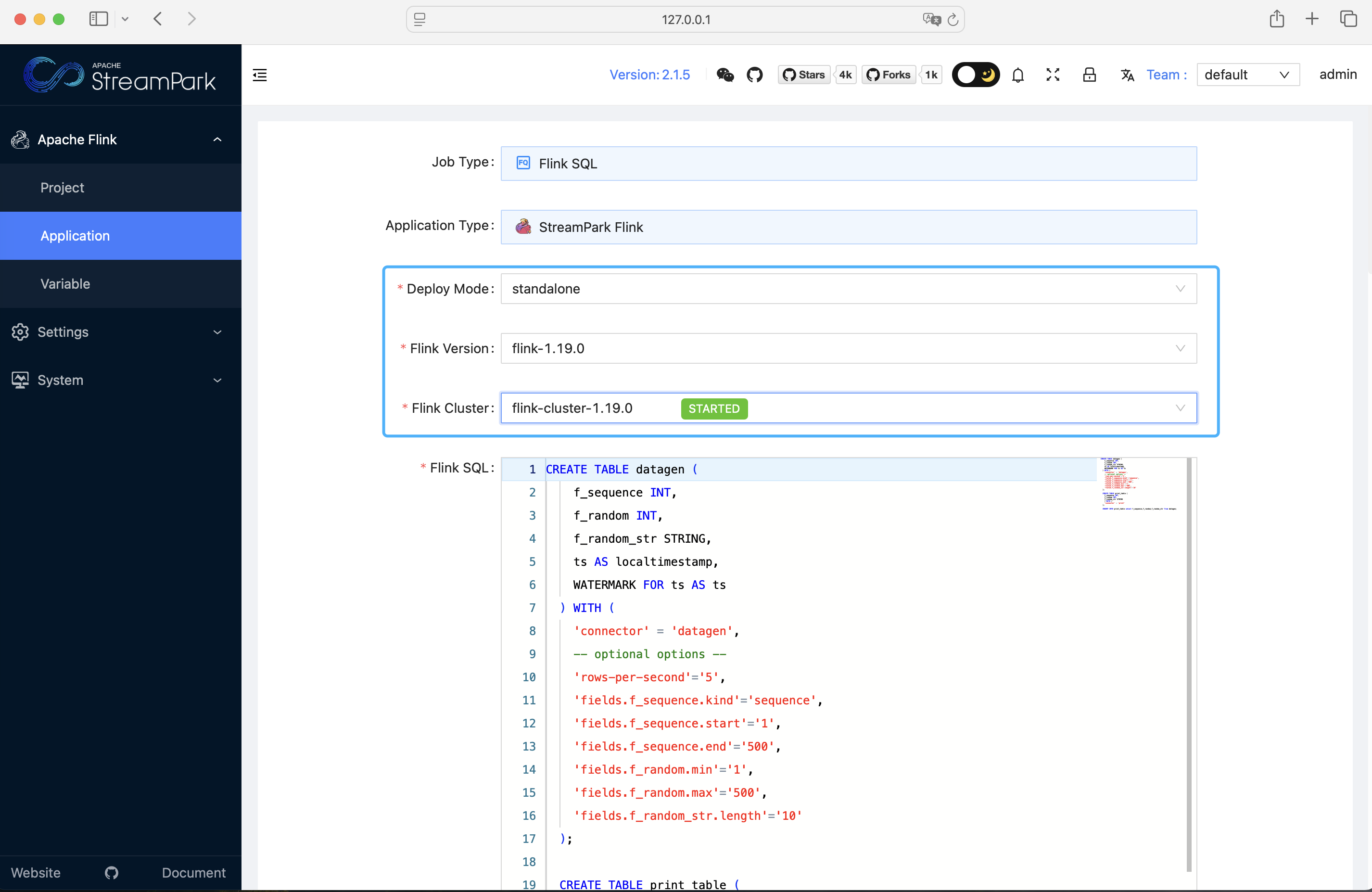
- 只需要修改部署模式、Flink 版本、Flink 集群,保存即可:
- 点击上线: (Release)
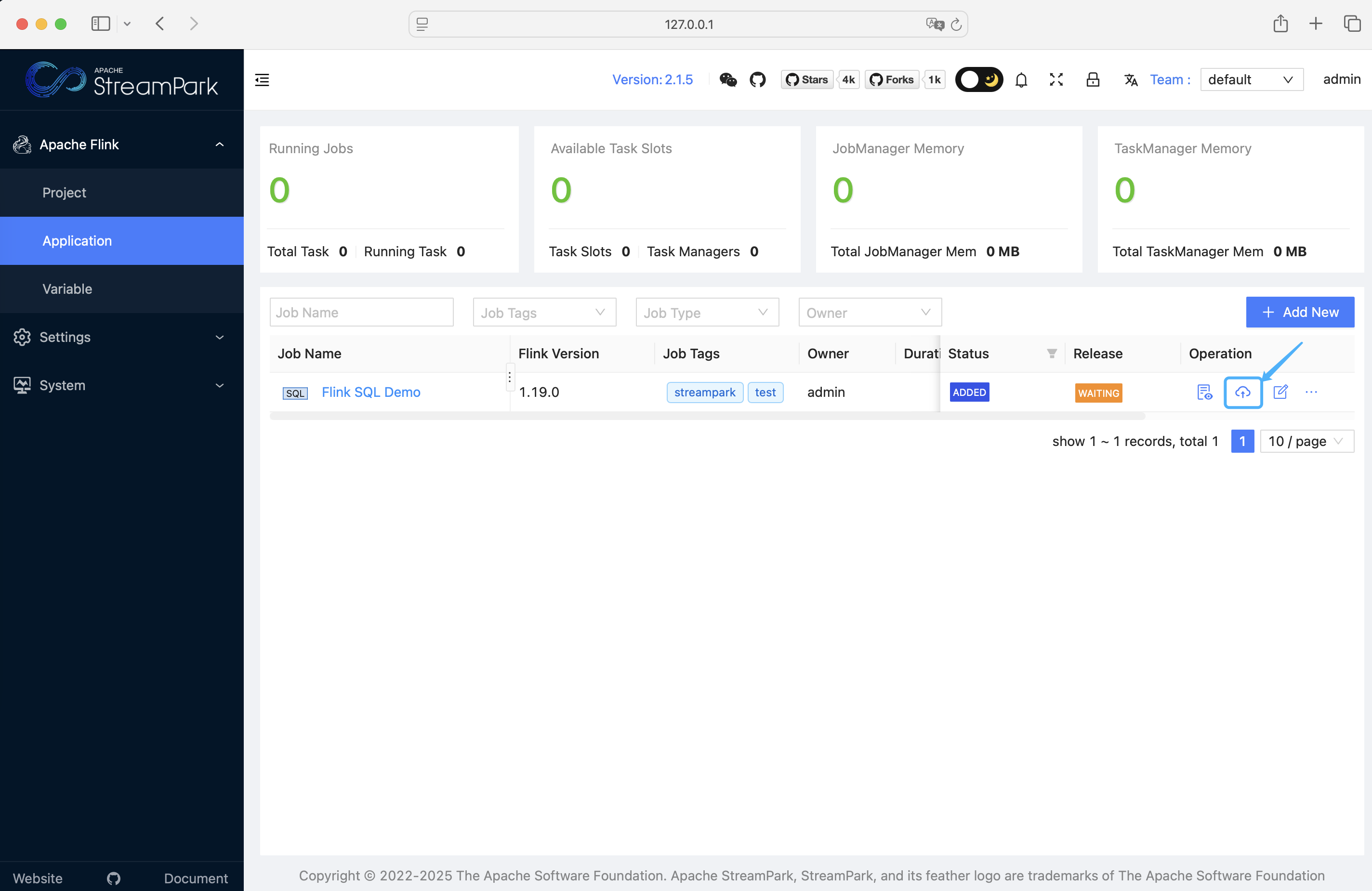
- 启动作业:
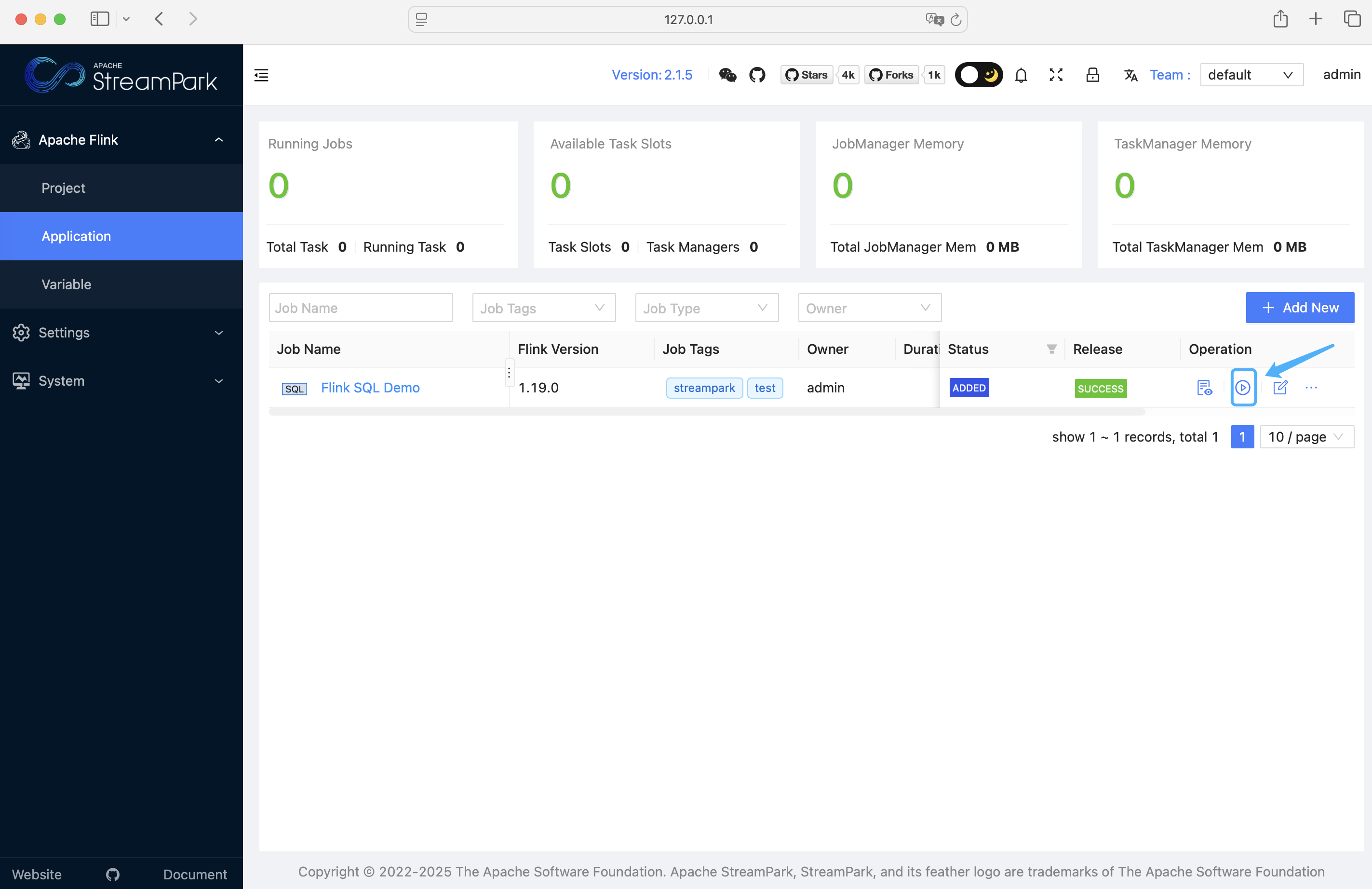
启动成功后的页面如下:
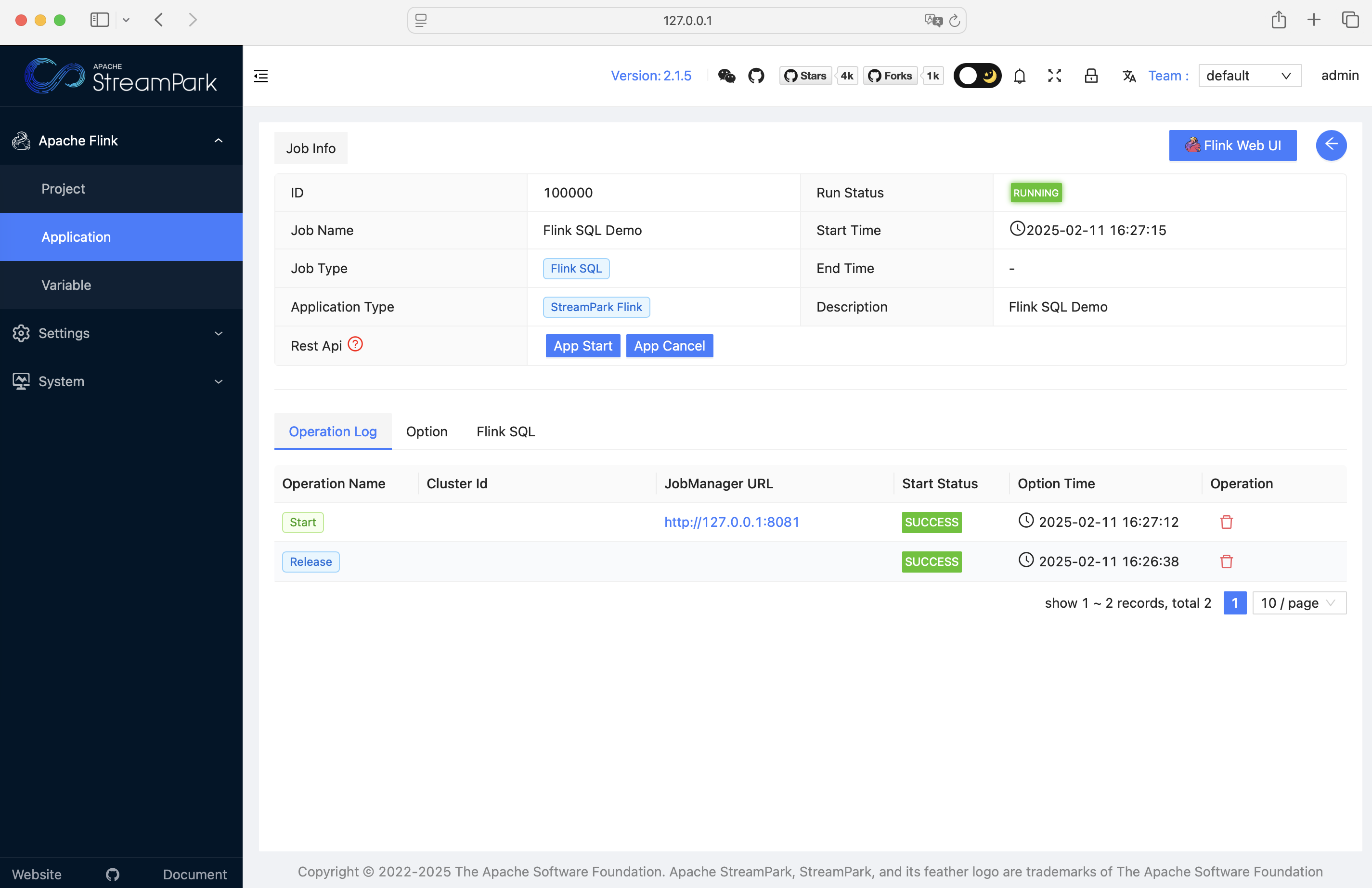
当然,也能进入详情页面查看作业详情:
3 安装部署
3.1 安装部署(非Docker版)
3.1.1 准备
- 为了顺利成功安装 StreamPark,首先需要准备好如下的环境:
| 环境 | 版本要求 | 是否必须 | 备注 |
|---|---|---|---|
| 操作系统 | Linux/MacOS | 是 | 不支持 Windows 系统 |
| Java | 1.18+ | 是 | Java version >=1.8 |
| Scala | 2.12+ | 是 | Scala version >=2.12 |
| 数据库 | MySQL: 5.6+、Postgresql: 9.6+ | 默认使用 H2 数据库,支持 MySQL 和 Postgresql | |
| Flink | 1.12+ | Flink 版本最低支持1.12 | |
| Hadoop | 2+ | 非必须,如果部署作业至 Yarn,需要准备 Hadoop 环境 | |
| Kubernetes | 1.16+ | 非必须,如果部署作业至 Kubernetes,需要准备 Kubernetes 集群 |
3.1.2 下载
- 您可以直接从官网下载最新版的 StreamPark
本文使用的是 2.1.5 版本
下载地址: https://streampark.apache.org/download
- 下载完成后,解压:
# 解压 streampark 安装包.
tar -zxvf apache-streampark_2.12-2.1.5-incubating-bin.tar.gz
- 可以看到解压后的目录如下:
├── bin
│ ├── startup.sh //启动脚本
│ ├── shutdown.sh //停止脚本
│ └── ......
├── conf
│ ├── config.yaml //项目配置文件
│ └── logback-spring.xml //日志配置文件
├── lib
│ └── *.jar //项目的 jar 包
├── logs //程序 log 目录
├── script
│ ├── data
│ │ ├── mysql-data.sql // mysql的ddl建表sql
│ │ └── pgsql-data.sql // pgsql的ddl建表sql
│ ├── schema
│ │ ├── mysql-schema.sql // mysql的完整初始化数据
│ │ └── pgsql-schema.sql // pgsql的完整初始化数据
│ └── upgrade
│ ├── mysql
│ │ ├── 1.2.3.sql //升级到 1.2.3版本需要执行的升级sql
│ │ ├── 2.0.0.sql //升级到 2.0.0版本需要执行的升级sql
│ │ ├── ......
│ └── pgsql
│ └── ......
└── temp //内部使用到的临时路径,不要删除
3.1.3 启动
- 进入安装目录下的 bin 目录,启动:
# 进入安装目录下的 bin 目录
cd bin
# 启动程序
./startup.sh
注意:
- 启动程序后,可能会报如下错误:streampark.workspace.local: "/tmp/streampark" is an invalid path, please reconfigure in xxx/conf/config.yaml
这是因为 streampark 的本地工作目录不存在或者是没有指定合法的目录,处理方式很简单,可以直接使用默认配置,在
/tmp目录直接新建streampark目录:
mkdir -p /tmp/streampark
或者配置安装路径下的
conf/config.yaml文件的streampark.workspace.local的属性值为一个合法的本地路径。
再次执行
startup.sh,可以看到程序启动成功:
- 访问 StreamPark
地址: http://127.0.0.1:10000 | 账号密码: admin / streampark

3.1.4 更多
- 至此,可以看到项目正常跑起来了,上述的安装是基于默认的 H2 本地数据库来启动程序的,继续来看看如何集成外部的数据库( MySQL 或 Postgresql )。
3.1.4.1 使用外部数据库
- 如果要使用外部数据库,需要修改安装目录下的
conf/config.yaml文件,核心修改内容如下(这里以 MySQL 为例子):
datasource:
dialect: mysql #这里改为 mysql,默认 h2, 支持 mysql、pgsql
h2-data-dir: ~/streampark/h2-data # 如果数据源为 h2, 这里需要配置。如果数据源为 mysql 或者 pgsql, 需要配置剩余的信息(用户名或密码)
username: # 数据源连接用户名
password: # 数据源连接密码
url: # jdbc 连接地址,例如:jdbc:mysql://localhost:3306/streampark?useUnicode=true&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8
-
接着需要手动连接外部数据库,并初始化 MySQL 建表脚本(位置:安装目录
/script/schema/mysql-schema.sql)以及数据初始化脚本(位置:安装目录/script/data/mysql-data.sql) -
以上步骤都准备好了后,启动服务即可自动连接并使用外部的数据库。
3.1.4.2 使用 Hadoop
- 如果需要部署作业至 YARN,则需要配置 Hadoop 相关的环境变量。假如您是基于 CDH 安装的 hadoop 环境, 相关环境变量可以参考如下配置:
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop #hadoop 安装目录
export HADOOP_CONF_DIR=/etc/hadoop/conf
export HIVE_HOME=$HADOOP_HOME/../hive
export HBASE_HOME=$HADOOP_HOME/../hbase
export HADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs
export HADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce
export HADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn
StreamPark 服务会自动从上述配置的环境变量里读取 hadoop 路径下的配置,连接 hadoop,上传资源至 hdfs 以及部署作业至 yarn。
- 除此,安装目录下的 conf/config.yaml 文件可能需要修改(例如指定 hadoop 用户、kerberos 认证等),核心修改内容如下:
streampark:
workspace:
# 存储资源至 hdfs 的根路径
remote: hdfs:///streampark/
proxy:
# hadoop yarn 代理路径, 例如: knox 进程地址 https://streampark.com:8443/proxy/yarn
yarn-url:
yarn:
# 验证类型
http-auth: 'simple' # 默认 simple或 kerberos
# flink on yarn or spark on yarn, HADOOP_USER_NAME
hadoop-user-name: hdfs
# 如果启用了 kerberos 认证,则需要配置如下信息
security:
kerberos:
login:
debug: false
enable: false
keytab:
krb5:
principal:
3.1.4.3 其它配置
- 最后附上 config.yaml 的配置详解,可以让您轻松地进一步集成 SSO 或 LDAP 等。
########################################### 日志相关配置 ###########################################
logging:
level:
root: info
########################################### 服务基础配置 ###########################################
server:
port: 10000
session:
ttl: 2h # 用户登录会话的有效期。如果会话超过这个时间,用户会被自动注销。
undertow: # Undertow 服务设置
buffer-size: 1024
direct-buffers: true
threads:
io: 16
worker: 256
########################################### 数据库相关配置 ###########################################
datasource:
dialect: h2 # 数据库方言,支持 h2、mysql、pgsql
h2-data-dir: ~/streampark/h2-data # 如果使用 h2 数据库,则需要配置数据目录
username:
password:
url: # 数据库连接URL,示例: jdbc:mysql://localhost:3306/streampark?......
########################################### 项目基础配置 ###########################################
streampark:
## 工作区配置,分为本地和 hdfs 工作区,用于相关不同类型的资源
workspace:
local: /tmp/streampark
remote: hdfs:///streampark/
## 代理相关
proxy:
lark-url: # 飞书代理地址
yarn-url: # Yarn 的代理路径
## yarn相关
yarn:
http-auth: 'simple' # 认证方式
hadoop-user-name: hdfs # 配置 Hadoop 用户名
## 项目管理相关
project:
max-build: 16 # 同时运行的最大项目数量。
## 开发接口相关
openapi:
white-list: # 配置开放 API 的白名单
########################################### kerberos 认证配置 ###########################################
security:
kerberos:
login:
debug: false
enable: false
keytab:
krb5:
principal:
ttl: 2h
########################################### ldap 认证配置 ###########################################
ldap:
base-dn: dc=streampark,dc=com
enable: false
username: cn=Manager,dc=streampark,dc=com
password: streampark
urls: ldap://99.99.99.99:389
user:
email-attribute: mail
identity-attribute: uid
- 当然,您也可以登录平台的设置中心去配置其它内容,包括:Maven、Docker、Kubernetes 或邮箱等。

3.2 安装部署(Docker)
3.2.1 环境准备
- 如果要使用 Docker 的方式安装 StreamPark,需要准备好如下的环境:
| 环境 | 版本要求 | 是否必须 | 备注 |
|---|---|---|---|
| Docker | 1.13.1+ | Docker版本不低于1.13.1 | |
| Docker Compose | 1.28.0+ | Docker Compose版本不低于1.28.0 |
本文默认已经安装好 Docker 和 Docker compose
3.2.2 打包镜像
- 本文讲解的是以手动的方式打包镜像,首先按照如下命令下载 StreamPark 源码,切换分支后把打包好的安装包放到 dist 目录:
## 克隆源码到本地
git clone https://github.com/apache/streampark.git
## 进入 docker 目录
cd streampark/docker
## 切换到期望打包的分支,这里为 release-2.1.5 分支
git checkout release-2.1.5
## 创建dist目录
mkdir dist
创建好 dist 目录之后,可以把打包好或已下载的安装包放到 dist 目录里面,这里为了方便演示,直接从官网下载的安装包。
下载地址: https://streampark.apache.org/download
- 接着可以开始打包镜像了:
## 注意: 这里已经把安装包放到dist目录了
# cp path/to/apache-streampark_2.12-2.1.5-incubating-bin.tar.gz dist
## 打包镜像,注意镜像名的格式为:<apache/streampark>:<版本号>,注意后面不要漏了 "."
docker build -t apache/streampark:2.1.5 .
## 打包成功后,可以使用命令查看镜像是否已经打包成功
docker images|grep streampark
- 使用
docker命令可以查看到镜像已经打包成功,如图所示:

3.2.3 启动服务
- 在当前 StreamPark 源码的 docker 目录,可以使用
docker-compose命令来启动服务:
docker-compose up -d
- 启动成功后,可以使用命令查看 StreamPark 服务是否运行正常:
docker ps -a|grep streampark
从下图可以看到,StreamPark 服务启动成功:

访问 StreamPark,地址: http://127.0.0.1:10000 | 账号密码: admin / streampark
3.2.4 配置详解
- 从上面可以得知 StreamPark 是使用 docker-compose 命令来启动的,而 docker-compose.yaml 文件是一个用于定义和管理多容器 Docker 应用程序的配置文件,其内容及解析如下:
version: '3.8'
services:
streampark:
image: apache/streampark:2.1.5 # 使用前面打包好的镜像
ports:
- "10000:10000" # 将容器的 10000 端口映射到主机的 10000 端口,允许访问该端口上的服务
environment:
- TZ=Asia/Shanghai # 容器内时区
- DATASOURCE_DIALECT=h2 # 设置数据源方言,支持 h2, mysql, pgsql,当前为 h2
# 如果使用 MySQL 或 PostgreSQL 数据库,需设置以下参数
# - DATASOURCE_URL=jdbc:mysql://localhost:3306/streampark?useSSL=false&useUnicode=true&characterEncoding=UTF-8&allowPublicKeyRetrieval=false&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=GMT%2B8
# - DATASOURCE_URL=jdbc:postgresql://localhost:5432/streampark?stringtype=unspecified
# - DATASOURCE_USERNAME=root # 数据库用户名
# - DATASOURCE_PASSWORD=streampark # 数据库密码
volumes:
- /var/run/docker.sock:/var/run/docker.sock # 将主机的 Docker 套接字挂载到容器内,允许容器内的进程与 Docker 进行交互
- /etc/hosts:/etc/hosts:ro # 将主机的 /etc/hosts 文件挂载到容器内,容器只读访问该文件
- ~/.kube:/root/.kube:ro # 将主机的 kube 配置目录挂载到容器中,以便访问 Kubernetes 集群
privileged: true # 给予容器更高权限,通常用于需要与宿主机资源交互的场景
restart: always # 容器崩溃或主机重启后总是自动重启容器
networks:
- streampark # 使用名为 streampark 的自定义网络
healthcheck: # 设置健康检查
test: [ "CMD", "curl", "http://streampark:10000" ] # 使用 curl 检查容器的 10000 端口是否可访问
interval: 5s # 健康检查的间隔时间为 5 秒
timeout: 5s # 每次健康检查的超时时间为 5 秒
retries: 120 # 如果健康检查失败,容器将在 120 次失败后被认为不可用
networks:
streampark:
driver: bridge # 使用桥接网络驱动
K 最佳实践 & 案例实践
Flink on Kubernetes
基于 Flink Native Kubernetes 项目构建
- StreamPark Flink Kubernetes 基于 Flink Native Kubernetes 实现,支持以下 Flink 运行模式:
- Native-Kubernetes Application
- Native-Kubernetes Session
- 单个
StreamPark实例当前只支持单个Kubernetes集群,如果您有多 Kubernetes 支持的诉求,欢迎提交相关的 Fearure Request Issue : )
额外环境要求
- StreamPark Flink-Kubernetes 需要具备以下额外的运行环境:
- Kubernetes
- Maven(StreamPark 运行节点具备)
- Docker(StreamPark 运行节点是具备)
- StreamPark 平台实例并不需要强制部署在
Kubernetes所在节点上,可以部署在 Kubernetes 集群外部节点,但是需要该 StreamPark 部署节点与Kubernetes集群保持网络通信畅通。
集成准备
Kubernetes 连接配置
- StreamPark 直接使用系统
~/.kube/config作为Kubernetes集群的连接凭证。
最为简单的方式是直接拷贝 Kubernetes 节点的
.kube/config到StreamPark节点用户目录,各云服务商 Kubernetes 服务也都提供了相关配置的快速下载。
当然为了权限约束,也可以自行生成对应 Kubernetes 自定义账户的 config。
- 完成后,可以通过 StreamPark 所在机器的
kubectl快速检查目标 Kubernetes 集群的连通性:
kubectl cluster-info
Kubernetes RBAC 配置
- 同样的,需要准备 Flink 所使用 Kubernetes Namespace 的 RBAC 资源
请参考 Flink-Docs: https://ci.apache.org/projects/flink/flink-docs-stable/docs/deployment/resource-providers/native_kubernetes/#rbac
- 假设使用 Flink Namespace 为
flink-dev,不明确指定 Kubernetes 账户,可以如下创建简单 clusterrolebinding 资源:
kubectl create clusterrolebinding flink-role-binding-default --clusterrole=edit --serviceaccount=flink-dev:default
Docker 远程容器服务配置
- 在 StreamPark Setting 页面,配置目标 Kubernetes 集群所使用的 Docker 容器服务的连接信息。
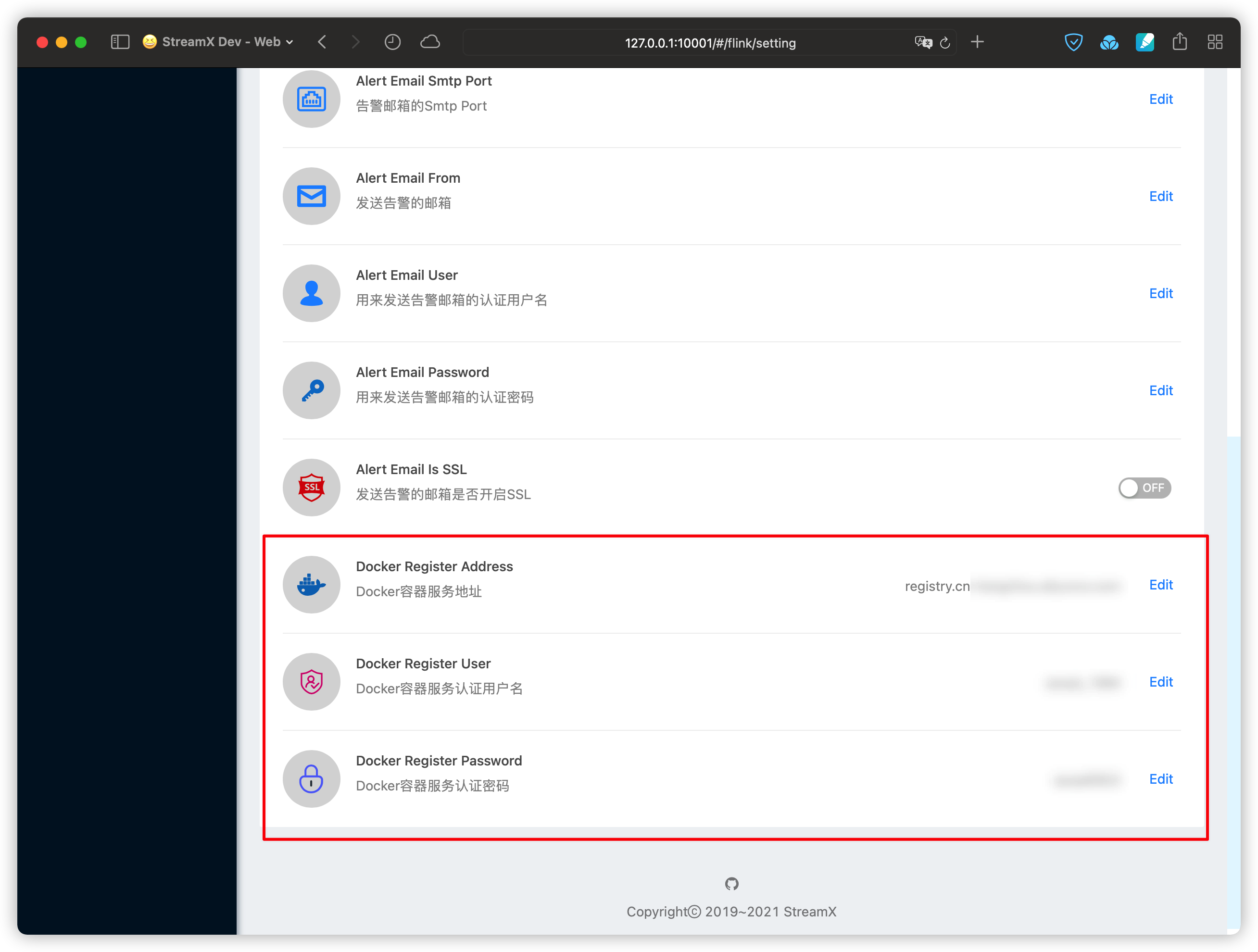
- 在远程 Docker 容器服务创建一个名为
streampark的 Namespace(该Namespace可自定义命名,命名不为 streampark 请在setting页面修改确认) ,为 StreamPark 自动构建的 Flink image 推送空间,请确保使用的 Docker Register User 具有该 Namespace 的 pull/push 权限。
可以在 StreamPark 所在节点通过 docker command 简单测试权限:
# verify access
docker login --username=<your_username> <your_register_addr>
# verify push permission
docker pull busybox
docker tag busybox <your_register_addr>/streampark/busybox
docker push <your_register_addr>/streampark/busybox
# verify pull permission
docker pull <your_register_addr>/streampark/busybox
任务提交
Application 任务发布

Flink Custom (Flink JAR) 也支持,且支持上传的外部依赖包。
- 其中需要说明的参数如下:
- Flink Base Docker Image: 基础 Flink Docker 镜像的 Tag
可以直接从 DockerHub - offical/flink 获取,也支持用户私有的底层镜像。
此时在 setting 设置 Docker Register Account 需要具备该私有镜像 pull 权限。
- Rest-Service Exposed Type: 对应 Flink 原生 kubernetes.rest-service.exposed.type 配置
各个候选值说明:
- ClusterIP:需要 StreamPark 可直接访问 Kubernetes 内部网络;
- LoadBalancer:需要 Kubernetes 提前创建 LoadBalancer 资源,且 Flink Namespace 具备自动绑定权限,同时 StreamPark 可以访问该 LoadBalancer 网关;
- NodePort:需要 StreamPark 可以直接连通所有 Kubernetes 节点;
- Kubernetes Pod Template: Flink 自定义 pod-template 配置,注意 container-name 必须为 flink-main-container,如果 Kubernetes pod 拉取 Docker 镜像需要秘钥,请在 pod 模板文件中补全秘钥相关信息,pod 模板如下:
apiVersion: v1
kind: Pod
metadata:
name: pod-template
spec:
serviceAccount: default
containers:
- name: flink-main-container
image:
imagePullSecrets:
- name: regsecret
- Dynamic Option: Flink on Kubernetes 动态参数(部分参数也可在 pod-template 文件中定义),该参数需要以
-D开头,详情见 Flink on Kubernetes相关参数。任务启动后,支持在该任务的 Detail 页直接访问对应的 Flink Web UI 页面:
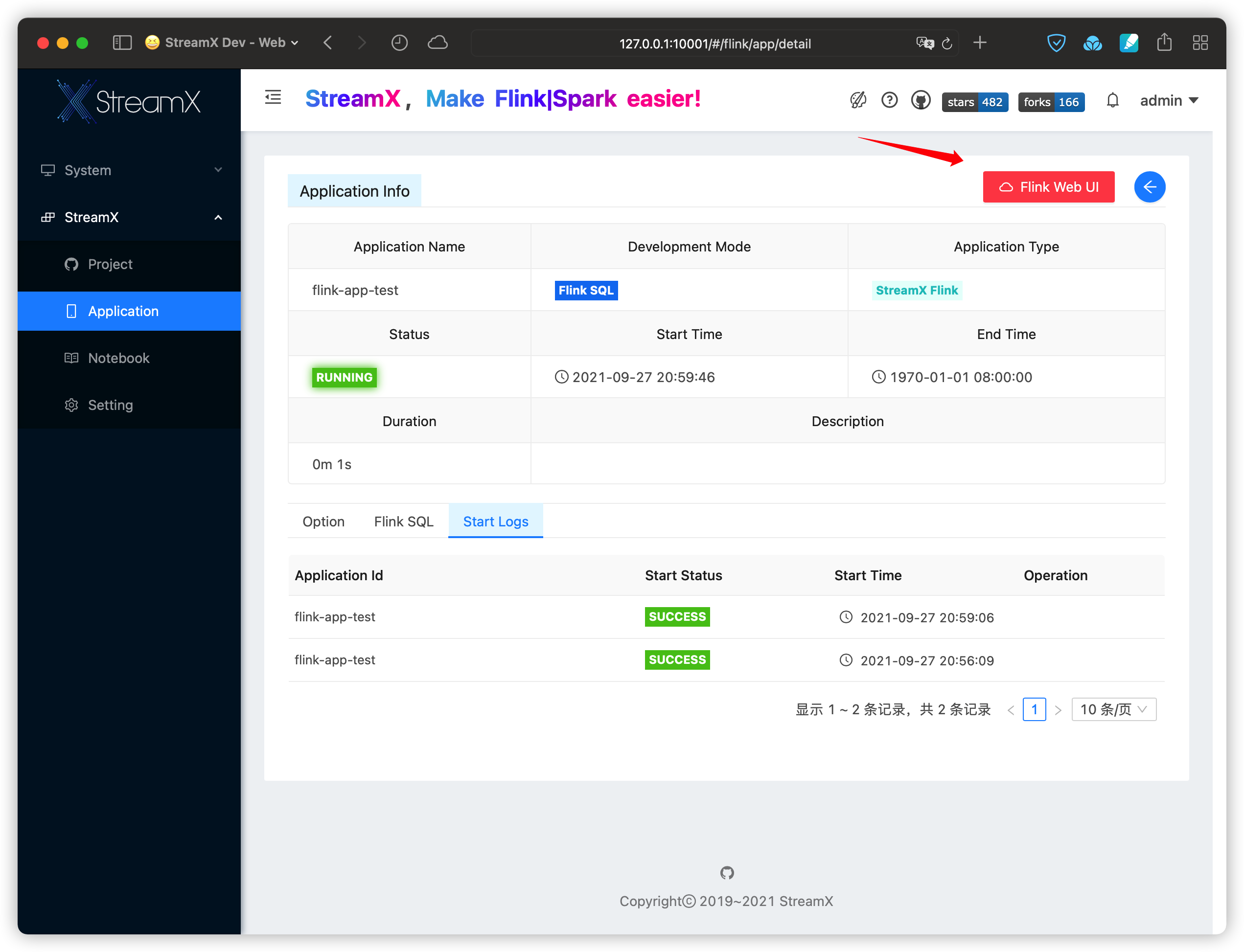
Session 任务发布
- Flink-Native-Kubernetes Session 任务 Kubernetes 额外的配置(pod-template 等)完全由提前部署的 Flink-Session 集群决定。
请直接参考 Flink-Doc: https://ci.apache.org/projects/flink/flink-docs-stable/docs/deployment/resource-providers/native_kubernetes
相关参数配置
- StreamPark 在
applicaton.ymlFlink-Kubernetes 相关参数如下,默认情况下不需要额外调整默认值。
| 配置项 | 描述 | 默认值 |
|---|---|---|
| streampark.docker.register.image-namespace | 远程 docker 容器服务仓库命名空间,构建的 flink-job 镜像会推送到该命名空间。 | null |
| streampark.flink-k8s.tracking.polling-task-timeout-sec.job-status | 每组 flink 状态追踪任务的运行超时秒数 | 120 |
| streampark.flink-k8s.tracking.polling-task-timeout-sec.cluster-metric | 每组 flink 指标追踪任务的运行超时秒数 | 120 |
| streampark.flink-k8s.tracking.polling-interval-sec.job-status | flink 状态追踪任务运行间隔秒数,为了维持准确性,请设置在 5s 以下,最佳设置在 2-3s | 5 |
| streampark.flink-k8s.tracking.polling-interval-sec.cluster-metric | flink 指标追踪任务运行间隔秒数 | 10 |
| streampark.flink-k8s.tracking.silent-state-keep-sec | silent 追踪容错时间秒数 | 60 |
参考文献
Z FAQ for Apache Stream Park
Q: Flink启动时,启动日志报找不到入口类?
问题描述
...
2034-11-27 12:21:50,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: $internal.application.program-args, --configLocation;nacos;--nacosHost;http://nacos.nacos:8848;--nacosUsername;nacos;--nacosPassword;xxxxxxx;--namespace;xxxx;--group;xxxx;--dataId;com.xxx.dataintegration.flinkapi.entry.xxx.deviceStatusxxxParse;--jobName;xxxTEST_deviceStatusxxxParse
2034-11-27 12:21:50,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: kubernetes.container.image, artifactory.xxx.com/docker-release/streampark-flink-xxx-TEST-device-status-xxx-parse
2034-11-27 12:21:50,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: parallelism.default, 1
2034-11-27 12:21:50,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: kubernetes.namespace, flink
2034-11-27 12:21:50,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.numberOfTaskSlots, 1
2034-11-27 12:21:50,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: kubernetes.rest-service.exposed.type, NodePort
2034-11-27 12:21:50,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: $internal.application.main, com.xxx.dataintegration.flinkapi.entry.xxx.deviceStatusxxxParse
2034-11-27 12:21:50,203 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: taskmanager.memory.process.size, 1728m
2034-11-27 12:21:50,204 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: kubernetes.internal.jobmanager.entrypoint.class, org.apache.flink.kubernetes.entrypoint.KubernetesApplicationClusterEntrypoint
2034-11-27 12:21:50,204 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: pipeline.name, xxx-TEST-device-status-xxx-parse
2034-11-27 12:21:50,204 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: classloader.resolve-order, child-first
2034-11-27 12:21:50,204 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: kubernetes.pod-template-file,
...
2034-11-27 12:21:50,205 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: pipeline.jars, local:///opt/flink/usrlib/streampark-flinkjob_xxx-TEST-device-status-xxx-parse.jar
2034-11-27 12:21:50,205 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: kubernetes.taskmanager.labels, jobId:911903a426d8d032ac7b039bca1ed944
2034-11-27 12:21:50,205 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: rest.address, localhost
2034-11-27 12:21:50,279 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: kubernetes.pod-template-file.jobmanager, /tmp/streampark/workspace/100001/xxx-TEST-device-status-xxx-parse@flink/pod-template.yaml
2034-11-27 12:21:50,279 INFO org.apache.flink.configuration.GlobalConfiguration [] - Loading configuration property: kubernetes.pod-template-file.jobmanager, /tmp/streampark/workspace/100001/xxx-TEST-device-status-xxx-parse@flink/pod-template.yaml
2034-11-27 12:21:50,608 ERROR org.apache.flink.runtime.entrypoint.ClusterEntrypoint [] - Could not create application program.
org.apache.flink.util.FlinkException: Could not load the provided entrypoint class.
at org.apache.flink.client.program.DefaultPackagedProgramRetriever.getPackagedProgram(DefaultPackagedProgramRetriever.java:215) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.kubernetes.entrypoint.KubernetesApplicationClusterEntrypoint.getPackagedProgram(KubernetesApplicationClusterEntrypoint.java:100) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.kubernetes.entrypoint.KubernetesApplicationClusterEntrypoint.main(KubernetesApplicationClusterEntrypoint.java:70) [flink-dist-1.15.0.jar:1.15.0]
Caused by: org.apache.flink.client.program.ProgramInvocationException: The program's entry point class 'com.xxx.dataintegration.flinkapi.entry.xxx.deviceStatusxxxParse' was not found in the jar file.
at org.apache.flink.client.program.PackagedProgram.loadMainClass(PackagedProgram.java:481) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.client.program.PackagedProgram.<init>(PackagedProgram.java:153) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.client.program.PackagedProgram.<init>(PackagedProgram.java:65) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.client.program.PackagedProgram$Builder.build(PackagedProgram.java:691) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.client.program.DefaultPackagedProgramRetriever.getPackagedProgram(DefaultPackagedProgramRetriever.java:213) ~[flink-dist-1.15.0.jar:1.15.0]
... 2 more
Caused by: java.lang.ClassNotFoundException: com.xxx.dataintegration.flinkapi.entry.xxx.deviceStatusxxxParse
at java.net.URLClassLoader.findClass(URLClassLoader.java:382) ~[?:1.8.0_275]
at java.lang.ClassLoader.loadClass(ClassLoader.java:418) ~[?:1.8.0_275]
at org.apache.flink.util.FlinkUserCodeClassLoader.loadClassWithoutExceptionHandling(FlinkUserCodeClassLoader.java:68) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.util.ChildFirstClassLoader.loadClassWithoutExceptionHandling(ChildFirstClassLoader.java:74) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.util.FlinkUserCodeClassLoader.loadClass(FlinkUserCodeClassLoader.java:52) ~[flink-dist-1.15.0.jar:1.15.0]
at java.lang.ClassLoader.loadClass(ClassLoader.java:351) ~[?:1.8.0_275]
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders$SafetyNetWrapperClassLoader.loadClass(FlinkUserCodeClassLoaders.java:172) ~[flink-dist-1.15.0.jar:1.15.0]
at java.lang.Class.forName0(Native Method) ~[?:1.8.0_275]
at java.lang.Class.forName(Class.java:348) ~[?:1.8.0_275]
at org.apache.flink.client.program.PackagedProgram.loadMainClass(PackagedProgram.java:479) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.client.program.PackagedProgram.<init>(PackagedProgram.java:153) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.client.program.PackagedProgram.<init>(PackagedProgram.java:65) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.client.program.PackagedProgram$Builder.build(PackagedProgram.java:691) ~[flink-dist-1.15.0.jar:1.15.0]
at org.apache.flink.client.program.DefaultPackagedProgramRetriever.getPackagedProgram(DefaultPackagedProgramRetriever.java:213) ~[flink-dist-1.15.0.jar:1.15.0]
... 2 more ... 2 more ... 2 more ... 2 more ... 2 more
...
问题分析
Stream Park(on k8s) 平台中Application部署模式下ReleaseFlinkJob 的流程中,镜像打包流程:
Step-6 Build flink app docker image
Step 1/4 : FROM artifactory.seres.cn/docker-release/flink-1.15-base-image:v17
Step 2/4 : RUN mkdir -p $FLINK_HOME/usrlib
Step 3/4 : COPY lib $FLINK_HOME/lib/
Step 4/4 : COPY streampark-flinkjob_rhr-uat-robot-status-signal-parse.jar $FLINK_HOME/usrlib/streampark-flinkjob_rhr-uat-robot-status-signal-parse.jar
- 方法1: 进入 FlinkJob 对应的 Pod 查看目标 JAR 包是否存在、入口启动类是否存在?
$ echo $FLINK_HOME
/opt/flink
$ ls -la /opt/flink/usrlib/streampark-flinkjob_xxx-dev-device-status-xxx-parse.jar
$ cd /opt && unzip -l /opt/flink/usrlib/streampark-flinkjob_xxx-dev-device-status-xxx-parse.jar | grep "com/xxx/dataintegration/flinkapi/entry/xxx/deviceStatusxxxParse"
解决方法
-
修复有问题的jar包
-
重新打包(镜像)
-
...
推荐文献
Application 模式 要求用户代码已经和 flink 镜像捆绑到一起了,因为该模式会在集群上运行用户代码的 main() 方法,application 模式会在程序终止后确保清除所有的 flink 组件。
FROM flink
RUN mkdir -p $FLINK_HOME/usrlib
COPY /path/of/my-flink-job.jar $FLINK_HOME/usrlib/my-flink-job.jar
Y 推荐文献
- Apache Stream Park
X 参考文献

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号