[OLAP/数据建模/MYSQL] 技术选型对比:Clickhouse vs Doris
0 序
Doris和ClickHouse是两款热门的OLAP数据库,它们在架构、功能、性能和易用性等方面存在差异
- Doris : 最初由百度大数据部研发,名为百度Palo。
- 2017年开源,2018年贡献给Apache社区并更名为Apache Doris。
- 设计目标是为了满足大数据场景下的实时分析需求。
- Clickhouse : 最初由 Yandex 公司开发并开源。
- 专为OLAP场景设计,特别适合大宽表和数据聚合查询。
- 在Yandex内部广泛应用于各种大数据分析场景。

1 架构设计

Doris:
- 采用
MPP架构,分为Frontend(FE)和Backend(BE)节点。
FE负责元数据管理和查询规划BE负责数据存储和执行,支持自动均衡和故障恢复,架构更偏向企业级,数据一致性强。
- 支持动态数据分区和自动数据分布策略,以实现【负载均衡】和【高效查询】。
- 通过简化的建表语句和优化的执行引擎设计,提供了更好的易用性和性能表现。
ClickHouse:基于Shared-Nothing架构,原生为单节点设计,需通过分布式表和ZooKeeper协调多节点,灵活性高但运维复杂度也较高。
- ClickHouse同样采用了MPP架构和列式存储格式,专注于OLAP场景的优化。
- 支持多种表引擎和数据复制功能以应对不同的数据存储和处理需求。这些设计使得ClickHouse在架构上具有很高的灵活性和可扩展性。
- 然而在某些方面如
join操作上可能不如Doris高效灵活;同时其SQL支持也有限制(如开窗函数仍在试验阶段)。
这些特点使得在选择数据库时需要根据具体业务场景进行权衡考虑。
2 功能特性
- 数据更新:Doris支持Upsert/Delete操作,数据更新实时可见;ClickHouse以追加写为主,更新操作异步,数据一致性较弱。
- 物化视图:Doris的物化视图自动刷新,ClickHouse需手动配置或重建。
- 数据导入:Doris支持多种实时导入方式(如Flink、Kafka),ClickHouse批量导入为主,实时性较弱。
- SQL兼容性:Doris基本兼容MySQL协议,易上手;ClickHouse使用自定义SQL方言,学习成本较高。
3 性能表现
- 查询速度:
ClickHouse在单表查询和聚合操作上性能极强,尤其适合只读场景;Doris在复杂SQL分析(如多表Join)和实时更新场景中表现更优。
- 高并发处理:
Doris在高并发查询中稳定性更好,ClickHouse需合理配置资源以应对高并发。
4 数据建模
基于doris 和基于clickhouse 数据库做数据建模,有何差异?尝试从宽表模型、星型模型、雪花模型、三范式模型角度深入分析:
核心差异:引擎特性决定模型适配优先级
Doris侧重 OLAP 场景的灵活性与兼容度ClickHouse侧重 极致查询性能与列存高效性,模型选择差异本质是引擎存储 / 计算特性的延伸。
宽表模型(大宽表,扁平化结构)
- Doris:支持但非最优,单表列数限制(默认 1000 列),宽表 JOIN 性能一般,更适合中等宽度的汇总宽表(如日报 / 周报聚合结果)。
- ClickHouse:天然适配且首选,列存引擎对宽表查询(多列过滤、部分列读取)效率极高,无严格列数限制,常用来存储原始明细宽表(如用户行为全量字段)。
星型模型(事实表 + 多个维度表,无维度表关联)
- Doris:原生友好,支持物化视图、预聚合,维度表 Join(Lookup Join)性能稳定,适合多维度下钻分析(如电商销售事实表 + 用户 / 商品 / 时间维度表)。
- ClickHouse:支持但需优化,维度表通过字典编码、Join 表缓存提升性能,更适合维度数据量小(百万级以下)的星型模型,大维度表 Join 易卡顿。
雪花模型(维度表多层关联,维度表间有 Join)
- Doris:兼容度更高,支持多层维度表嵌套 Join,查询优化器对复杂 Join 的拆解更成熟,适合维度层级复杂的场景(如地域维度:国家→省份→城市)。
- ClickHouse:不推荐,多层 Join 会极大消耗内存和 CPU,列存引擎对多表关联优化较弱,强行使用会导致查询性能暴跌,需先扁平化为星型 / 宽表。
三范式模型(数据最小冗余,多表关联)
- Doris:支持但不推荐 OLAP 场景,三范式的多表 Join 会抵消其预聚合优势,仅适合需严格保证数据一致性的少量 Transactional 场景(如订单明细 + 支付明细关联)。
- ClickHouse:几乎不支持,引擎设计聚焦读优化,对事务和多表关联支持薄弱,三范式的高频 Join 会让查询速度骤降,完全违背其列存高效特性。
初步总结
| 模型 | Doris 适配性 | ClickHouse 适配性 | 核心原因 |
|---|---|---|---|
| 宽表模型 | 中等(汇总宽表) | 极高(明细宽表) | ClickHouse 列存对宽表读取更高效 |
| 星型模型 | 极高(首选) | 中等(小维度) | Doris 对维度 Join 和预聚合更友好 |
| 雪花模型 | 中等(兼容) | 极低(不推荐) | ClickHouse 多层 Join 性能拉胯 |
| 三范式模型 | 低(仅特殊场景) | 极低(不支持) | 两者均侧重读优化,抵触多 Join |
案例实践
电商销售分析场景:Doris vs ClickHouse 模型设计实操
1. 业务需求
核心:支持多维度(用户 / 商品 / 地域 / 时间)下钻、销售指标实时汇总(GMV / 订单量 / 客单价)、维度属性灵活过滤(如商品分类、用户会员等级)。
2. Doris 模型设计(首选星型模型)
- 事实表(sales_fact):存储订单明细核心字段(订单 ID、用户 ID、商品 ID、地域 ID、下单时间、支付金额、订单量),采用 聚合模型(Aggregate Model),预聚合按天 / 商品 / 地域汇总 GMV 和订单量。
- 维度表(4 张):用户维(user_dim,含会员等级、注册时间)、商品维(product_dim,含分类、价格带)、地域维(region_dim,国家→省份→城市层级)、时间维(time_dim,年月日时分秒层级)。
- 关联方式:查询时通过 Lookup Join 关联事实表与维度表,利用 Doris 物化视图提前缓存热门维度组合的聚合结果,下钻查询响应时间控制在 100ms 内。
- 优势:支持地域维度多层过滤(如 “查询中国 - 广东 - 深圳的会员用户 GMV”),无需扁平化维度表,数据冗余低,维度属性更新(如商品分类调整)无需重刷事实表。
3. ClickHouse 模型设计(首选宽表模型)
-
核心表(sales_wide):将事实表与所有维度表字段扁平化为宽表,包含订单 ID、支付金额、用户会员等级、商品分类、省份、城市、下单日期等 全量字段。
-
优化手段
:
- 维度字段(如商品分类、会员等级)采用字典编码,降低存储开销;
- 按 “下单日期 + 商品分类” 分区,查询时精准命中分区;
- 对 GMV、订单量字段创建跳数索引,加速聚合计算。
-
限制:地域维度需提前扁平化为 “省份”“城市” 字段,无法直接支持 “国家→省份” 的层级关联查询,若需层级分析需额外冗余 “国家 - 省份” 组合字段;维度属性更新(如用户会员等级升级)需通过更新语句重写宽表,成本较高。
日志分析场景(Doris vs ClickHouse 模型设计)
1. 业务需求
- 核心:存储全量用户行为日志(点击 / 浏览 / 购买),支持按时间范围、用户 ID、页面 URL、设备类型等多条件过滤查询,需快速导出明细数据。
2. Doris 模型设计(汇总宽表 + 明细表)
-
明细表(log_detail):存储原始日志全字段,采用 明细模型(Duplicate Model),按天分区,仅支持基础过滤查询,不适合复杂聚合。
-
汇总宽表(log_aggregate):按天 / 用户 ID / 设备类型预聚合,存储点击次数、浏览时长等指标,供快速统计分析。
-
劣势:原始日志字段达 200 + 时,明细表查询性能下滑明显,多条件组合过滤(如 “查询 2024 年 5 月 1 日 - 10 日,安卓设备用户访问‘首页’的明细日志”)响应时间超 1s,不如 ClickHouse 高效。
3. ClickHouse 模型设计(宽表明细表)
- 核心表(log_wide):采用 MergeTree 引擎,按 “日期 + 设备类型” 分区,主键设为(用户 ID,页面 URL),对常用过滤字段(如设备类型、页面 URL)创建布隆过滤器。
- 优势:列存引擎支持仅读取查询所需字段(如仅读取 “用户 ID + 点击时间 + 页面 URL”),200 + 列的宽表查询仍能保持毫秒级响应;支持批量导出明细数据,适合日志溯源分析。
- 适配性:完全贴合 ClickHouse 列存优势,无需预聚合,原始日志直接入库即可支持高效查询,是日志场景的最优选择。
模型选择决策清单(快速落地参考)
| 决策维度 | 选 Doris 的场景 | 选 ClickHouse 的场景 |
|---|---|---|
| 维度复杂度 | 维度层级多(如雪花模型场景)、需灵活下钻 | 维度简单、无需层级关联 |
| 数据形态 | 以汇总数据为主、需预聚合 | 以原始明细数据为主、需多字段过滤 |
| 关联需求 | 需多表 Join、维度频繁更新 | 单表查询为主、维度相对稳定 |
| 响应要求 | 聚合查询响应≤500ms,对明细查询要求不高 | 明细 / 聚合查询均需毫秒级,支持海量数据扫描 |
结合 电商销售分析 和 日志分析 两大核心场景,提供可直接执行的 Doris/ClickHouse 建表语句,包含分区、分桶、索引、引擎优化等关键配置,适配常见数据量级(日增 1000 万条明细,维度表百万级)。
案例:电商销售分析场景建表语句
1. Doris 建表(星型模型:事实表 + 4 张维度表)
(1)维度表设计(Lookup Join 依赖,支持动态更新)
-- 1. 时间维度表(time_dim):预生成2020-2030年时间层级数据
CREATE TABLE time_dim (
time_id INT COMMENT '时间唯一ID(YYYYMMDD)',
dt DATE COMMENT '日期',
year INT COMMENT '年份',
quarter INT COMMENT '季度',
month INT COMMENT '月份',
day INT COMMENT '日期',
week INT COMMENT '周数',
is_workday TINYINT COMMENT '是否工作日(0=否,1=是)'
) ENGINE=OLAP
DUPLICATE KEY(time_id)
COMMENT '时间维度表'
DISTRIBUTED BY HASH(time_id) BUCKETS 10
PROPERTIES (
"replication_num" = "3", -- 副本数(生产环境建议3)
"storage_medium" = "HDD" -- 维度表数据量小,用HDD即可
);
-- 2. 地域维度表(region_dim):支持国家→省份→城市层级
CREATE TABLE region_dim (
region_id INT COMMENT '地域唯一ID',
country VARCHAR(50) COMMENT '国家',
province VARCHAR(50) COMMENT '省份',
city VARCHAR(50) COMMENT '城市',
city_level TINYINT COMMENT '城市等级(1=一线,2=二线...)',
region_code VARCHAR(20) COMMENT '行政区划代码'
) ENGINE=OLAP
DUPLICATE KEY(region_id)
COMMENT '地域维度表'
DISTRIBUTED BY HASH(region_id) BUCKETS 10
PROPERTIES (
"replication_num" = "3",
"storage_medium" = "HDD"
);
-- 3. 用户维度表(user_dim):含会员等级等属性
CREATE TABLE user_dim (
user_id BIGINT COMMENT '用户唯一ID',
member_level TINYINT COMMENT '会员等级(0=普通,1=青铜...5=黑钻)',
register_dt DATE COMMENT '注册日期',
gender TINYINT COMMENT '性别(0=未知,1=男,2=女)',
city VARCHAR(50) COMMENT '用户所在城市'
) ENGINE=OLAP
DUPLICATE KEY(user_id)
COMMENT '用户维度表'
DISTRIBUTED BY HASH(user_id) BUCKETS 20 -- 用户量较大,分桶数增加
PROPERTIES (
"replication_num" = "3",
"storage_medium" = "HDD"
);
-- 4. 商品维度表(product_dim):含分类、价格带属性
CREATE TABLE product_dim (
product_id BIGINT COMMENT '商品唯一ID',
product_name VARCHAR(200) COMMENT '商品名称',
category1 VARCHAR(50) COMMENT '一级分类',
category2 VARCHAR(50) COMMENT '二级分类',
price DECIMAL(10,2) COMMENT '售价',
brand VARCHAR(50) COMMENT '品牌',
status TINYINT COMMENT '状态(0=下架,1=上架)'
) ENGINE=OLAP
DUPLICATE KEY(product_id)
COMMENT '商品维度表'
DISTRIBUTED BY HASH(product_id) BUCKETS 20
PROPERTIES (
"replication_num" = "3",
"storage_medium" = "HDD"
);
(2)事实表设计(Aggregate 模型,预聚合 + 物化视图)
-- 销售事实表(按天/用户/商品/地域预聚合)
CREATE TABLE sales_fact (
dt DATE COMMENT '日期(分区键)',
user_id BIGINT COMMENT '用户ID',
product_id BIGINT COMMENT '商品ID',
region_id INT COMMENT '地域ID',
order_cnt BIGINT SUM DEFAULT 0 COMMENT '订单量(聚合字段)',
gmv DECIMAL(12,2) SUM DEFAULT 0 COMMENT 'GMV(聚合字段)',
pay_cnt BIGINT SUM DEFAULT 0 COMMENT '支付订单量(聚合字段)'
) ENGINE=OLAP
AGGREGATE KEY(dt, user_id, product_id, region_id) -- 聚合主键(去重维度)
COMMENT '销售事实表(预聚合)'
PARTITION BY RANGE (dt) (
START ('2024-01-01') END ('2025-01-01') EVERY (INTERVAL 1 DAY), -- 按天分区
START ('2025-01-01') END ('2026-01-01') EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(user_id, product_id) BUCKETS 100 -- 复合分桶,均衡数据分布
PROPERTIES (
"replication_num" = "3",
"storage_medium" = "SSD", -- 事实表查询频繁,用SSD提升性能
"storage_cooldown_time" = "30 DAY" -- 30天前的分区冷数据迁移到HDD
);
-- 物化视图(加速热门维度组合查询:按天+商品分类+会员等级聚合)
CREATE MATERIALIZED VIEW sales_mv_category_member
COMMENT '按商品分类+会员等级预聚合'
AS
SELECT
t.dt,
p.category1,
p.category2,
u.member_level,
SUM(t.order_cnt) AS order_cnt,
SUM(t.gmv) AS gmv
FROM sales_fact t
JOIN product_dim p ON t.product_id = p.product_id
JOIN user_dim u ON t.user_id = u.user_id
GROUP BY t.dt, p.category1, p.category2, u.member_level;
2. ClickHouse 建表(宽表模型:事实表 + 维度字段扁平化)
-- 销售宽表(MergeTree 引擎,维度字段全冗余)
CREATE TABLE sales_wide (
dt Date COMMENT '日期(分区键)',
order_id String COMMENT '订单唯一ID',
user_id UInt64 COMMENT '用户ID',
member_level UInt8 COMMENT '会员等级',
user_gender UInt8 COMMENT '用户性别',
product_id UInt64 COMMENT '商品ID',
product_name String COMMENT '商品名称',
category1 String COMMENT '商品一级分类',
category2 String COMMENT '商品二级分类',
brand String COMMENT '商品品牌',
region_id UInt32 COMMENT '地域ID',
country String COMMENT '国家',
province String COMMENT '省份',
city String COMMENT '城市',
city_level UInt8 COMMENT '城市等级',
order_cnt UInt32 COMMENT '订单量',
gmv Decimal(12,2) COMMENT 'GMV',
pay_cnt UInt32 COMMENT '支付订单量',
create_time DateTime COMMENT '下单时间'
) ENGINE = MergeTree()
ORDER BY (dt, user_id, product_id) -- 排序键:优先按分区字段+高频查询字段排序
PARTITION BY dt -- 按天分区
PRIMARY KEY (dt, category1, member_level) -- 主键:加速热门维度过滤
TTL dt + INTERVAL 90 DAY -- 数据保留90天(自动清理过期数据)
SETTINGS
storage_policy = 'default', -- 存储策略(默认即可)
index_granularity = 8192, -- 索引粒度(默认8192,平衡索引开销和查询效率)
enable_mixed_granularity_parts = 1; -- 支持小粒度分区,提升写入性能
-- 为常用过滤字段创建布隆过滤器(减少IO)
ALTER TABLE sales_wide ADD INDEX idx_category2 category2 TYPE bloom_filter GRANULARITY 4;
ALTER TABLE sales_wide ADD INDEX idx_city city TYPE bloom_filter GRANULARITY 4;
-- 为聚合字段创建跳数索引(加速SUM/COUNT)
ALTER TABLE sales_wide ADD INDEX idx_gmv gmv TYPE minmax GRANULARITY 1;
ALTER TABLE sales_wide ADD INDEX idx_order_cnt order_cnt TYPE minmax GRANULARITY 1;
案例:日志分析场景建表语句
1. Doris 建表(明细模型 + 汇总宽表)
(1)原始日志明细表(Duplicate 模型,支持全字段查询)
CREATE TABLE log_detail (
log_id BIGINT COMMENT '日志唯一ID',
dt DATE COMMENT '日期(分区键)',
log_time DATETIME COMMENT '日志产生时间',
user_id BIGINT COMMENT '用户ID',
device_type VARCHAR(20) COMMENT '设备类型(安卓/苹果/PC)',
device_id VARCHAR(50) COMMENT '设备唯一标识',
page_url VARCHAR(200) COMMENT '访问页面URL',
page_title VARCHAR(100) COMMENT '页面标题',
action_type VARCHAR(20) COMMENT '行为类型(点击/浏览/停留)',
stay_duration INT COMMENT '停留时长(秒)',
referer_url VARCHAR(200) COMMENT '来源URL',
ip VARCHAR(20) COMMENT '用户IP',
user_agent VARCHAR(500) COMMENT '浏览器UA'
) ENGINE=OLAP
DUPLICATE KEY(dt, log_time, user_id) -- 排序键:按时间+用户ID排序,提升查询效率
COMMENT '用户行为日志明细表'
PARTITION BY RANGE (dt) (
START ('2024-01-01') END ('2026-01-01') EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(user_id, device_id) BUCKETS 150 -- 复合分桶,避免数据倾斜
PROPERTIES (
"replication_num" = "3",
"storage_medium" = "HDD", -- 明细表数据量大,用HDD节省成本
"load_mem_limit" = "8589934592" -- 导入内存限制8GB,适配大批次日志导入
);
-- 汇总宽表(按天/用户/设备/页面预聚合)
CREATE TABLE log_aggregate (
dt DATE COMMENT '日期(分区键)',
user_id BIGINT COMMENT '用户ID',
device_type VARCHAR(20) COMMENT '设备类型',
page_url VARCHAR(200) COMMENT '访问页面URL',
click_cnt BIGINT SUM DEFAULT 0 COMMENT '点击次数',
browse_cnt BIGINT SUM DEFAULT 0 COMMENT '浏览次数',
total_stay_duration INT SUM DEFAULT 0 COMMENT '总停留时长(秒)'
) ENGINE=OLAP
AGGREGATE KEY(dt, user_id, device_type, page_url)
COMMENT '日志汇总宽表'
PARTITION BY RANGE (dt) (
START ('2024-01-01') END ('2026-01-01') EVERY (INTERVAL 1 DAY)
)
DISTRIBUTED BY HASH(user_id, page_url) BUCKETS 100
PROPERTIES (
"replication_num" = "3",
"storage_medium" = "SSD" -- 汇总表查询频繁,用SSD加速
);
2. ClickHouse 建表(宽表明细表,原生适配日志场景)
CREATE TABLE log_wide (
dt Date COMMENT '日期(分区键)',
log_id UInt64 COMMENT '日志唯一ID',
log_time DateTime COMMENT '日志产生时间',
user_id UInt64 COMMENT '用户ID',
device_type String COMMENT '设备类型',
device_id String COMMENT '设备唯一标识',
page_url String COMMENT '访问页面URL',
page_title String COMMENT '页面标题',
action_type String COMMENT '行为类型',
stay_duration UInt32 COMMENT '停留时长(秒)',
referer_url String COMMENT '来源URL',
ip String COMMENT '用户IP',
user_agent String COMMENT '浏览器UA'
) ENGINE = MergeTree()
ORDER BY (dt, log_time, user_id) -- 排序键:时间+用户,适配按时间范围+用户查询
PARTITION BY dt -- 按天分区
PRIMARY KEY (dt, device_type, action_type) -- 主键:加速设备类型+行为类型过滤
TTL dt + INTERVAL 180 DAY -- 日志保留180天
SETTINGS
storage_policy = 'default',
index_granularity = 8192,
enable_mixed_granularity_parts = 1,
min_bytes_for_wide_part = 1073741824; -- 1GB以上分区用宽格式存储,提升查询效率
-- 布隆过滤器(优化高频过滤字段)
ALTER TABLE log_wide ADD INDEX idx_page_url page_url TYPE bloom_filter GRANULARITY 4;
ALTER TABLE log_wide ADD INDEX idx_device_id device_id TYPE bloom_filter GRANULARITY 4;
-- 跳数索引(加速停留时长统计)
ALTER TABLE log_wide ADD INDEX idx_stay_duration stay_duration TYPE minmax GRANULARITY 1;
小结:建表关键配置说明(避坑指南)
1. 分区设计
- 两者均按 天分区(适合日增千万级数据),Doris 支持分区冷热迁移,ClickHouse 支持 TTL 自动清理;
- 分区范围建议提前创建 1-2 年,避免动态创建分区影响写入性能。
2. 分桶 / 排序键
- Doris:事实表用 复合分桶(如 user_id+product_id),避免单字段分桶倾斜;维度表分桶数 = 节点数 ×2~3;
- ClickHouse:排序键(ORDER BY)优先放 分区字段 + 高频过滤字段,主键(PRIMARY KEY)是排序键的前缀,无需重复设置。
3. 索引优化
- Doris:Aggregate 模型依赖聚合主键去重,物化视图优先覆盖热门维度组合;
- ClickHouse:布隆过滤器适合 字符串类型过滤字段(如 URL、设备 ID),跳数索引适合 数值型聚合字段(如 GMV、停留时长)。
4. 存储介质
- 高频查询表(Doris 事实表 / 汇总表、ClickHouse 核心宽表)用 SSD;
- 低频明细表、维度表用 HDD,降低存储成本。
5 易用性和生态
运维难度
Doris集群管理简单,支持自动扩缩容;ClickHouse需手动配置分布式表和ZooKeeper,运维门槛较高。
生态支持

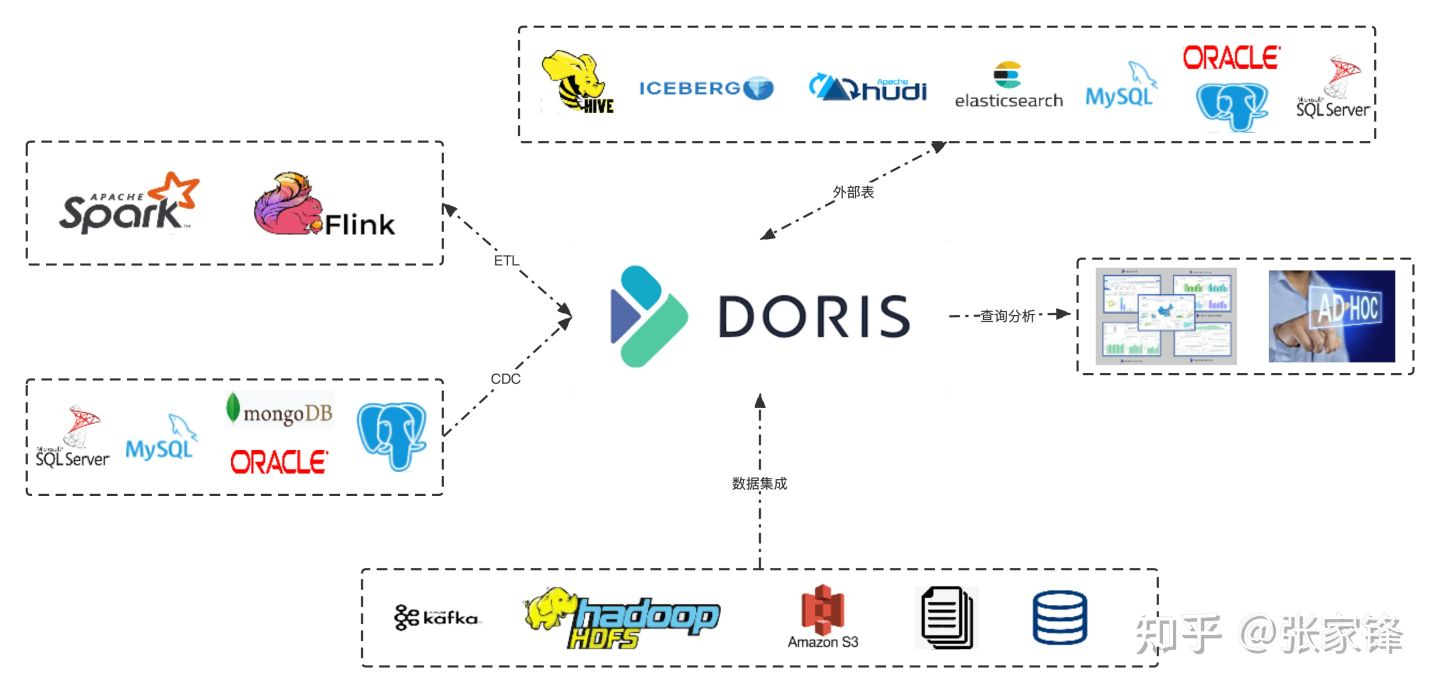
-
Doris与主流BI工具(如Superset、FineBI)兼容性好,支持Iceberg、Hive等数据湖对接; -
ClickHouse生态以日志分析场景为主,BI工具适配性稍弱。
6 运维复杂度
Doris
- Doris提供了简洁的运维体验。
- 例如,它支持自动故障节点恢复和灵活的扩缩容能力,降低了手动介入的频率。
- 提供了丰富的监控和诊断工具,帮助运维人员快速定位和解决问题。
- 社区活跃,提供了良好的支持,使得运维过程中遇到的问题可以得到及时解答。
ClickHouse
- ClickHouse在运维方面相对复杂一些。
例如,对于Shard和Replica的维护,ClickHouse需要在配置文件中进行人工配置。
- 虽然也提供了一些监控和诊断工具,但在易用性和功能丰富性上可能不如Doris。
- 社区同样活跃,但由于某些特性较为独特,可能需要更深入的了解和学习才能有效解决问题。
7 扩展性
| 特性 | Doris | ClickHouse |
|---|---|---|
| 分区支持 | 支持 range | 支持 expression |
| 分桶支持 | 是 | 否 |
| 动态分区 | 是 | 是 |
| 冷热数据分级 | 是 | 是 |
| 二级分区 | 否 | 否 |
| 索引 | 前缀索引 | 任意字段 |
- Doris:
- Doris支持在线扩容和缩容,可以轻松应对数据量和计算需求的变化。
- 通过动态分区功能,可以方便地对数据进行细粒度管理,提高查询性能。
- 支持多种数据导入方式,包括批量导入和实时导入,可以灵活地应对不同场景下的数据导入需求。
- ClickHouse:
- ClickHouse也支持在线扩容和缩容,但需要更复杂的配置和管理。
- 通过使用分布式表和数据复制功能,可以实现数据的水平扩展和高可用性。
- 提供了多种表引擎和优化选项,以满足不同场景下的查询和数据处理需求。但在某些复杂场景下,可能需要额外的配置和优化才能实现最佳性能。
8 劣势对比
核心结论:劣势本质是“引擎设计目标的取舍”
-
Doris 劣势集中在 明细查询性能、极致吞吐场景适配
-
ClickHouse 劣势集中在 复杂关联、事务支持、维度动态更新
两者劣势均源于核心定位(Doris 求稳求灵活,ClickHouse 求快求极致)。
Doris 的核心劣势
1. 明细数据查询与高吞吐写入支撑不足
- 列存+行存混合架构,对超宽表(200+列)、全量明细扫描场景(如日志溯源)的性能远不如 ClickHouse,相同数据量下查询耗时是 ClickHouse 的 3-10 倍。
- 写入吞吐上限较低,单节点峰值写入 QPS 约 10 万-30 万,无法支撑每秒百万级的实时写入(如高并发埋点日志),需依赖 Flink 预聚合后导入。
2. 极致性能场景的优化空间有限
-
缺乏 ClickHouse 那样的字典编码、跳数索引、布隆过滤器等精细化存储优化,纯聚合查询(如全量数据 SUM/COUNT)性能比 ClickHouse 低 20%-50%。
-
不支持向量执行引擎(ClickHouse 核心优势),单条查询的 CPU 利用率无法拉满,大数据量下的响应速度天花板较低。
3. 生态工具与场景适配的局限性
- 实时写入依赖外部工具(如 Flink、Kafka Connect),无原生 Kafka 引擎直接消费数据,实时性落地成本高。
- 对时序数据场景(如监控指标存储)支持薄弱,缺乏 TTL 自动分区清理、时序索引等特性,不如 ClickHouse 原生适配。
ClickHouse 的核心劣势
1. 复杂关联查询与维度模型适配差
-
不支持多层 Join(如: 雪花模型场景),即使是星型模型,当维度表数据量超千万级时,Lookup Join 会出现内存溢出、查询超时,必须扁平化宽表。
-
缺乏成熟的查询优化器,多表 Join 时无法自动选择最优 Join 顺序,需手动调整关联逻辑,开发成本高。
2. 事务与数据一致性支持薄弱
-
仅支持单表原子写入,不支持跨表事务,无法满足“事实表+维度表”原子更新的场景(如订单支付后同步更新库存和销售数据)。
-
数据更新(UPDATE/DELETE)性能极差,采用“标记删除+合并重写”机制,大表更新会产生大量临时文件,引发磁盘 IO 风暴,甚至导致查询阻塞。
3. 维度动态更新与数据治理成本高
-
宽表模型下,维度属性变更(如商品分类调整、用户会员等级升级)需全表重写或批量更新,数据量千万级以上时,更新耗时达小时级,且易丢失历史版本。
-
缺乏数据权限精细化控制(如行级、列级权限)、数据质量校验等企业级数据治理功能,需依赖外部系统(如 Ranger、DataWorks)补充,架构复杂度高。
4. 高可用与运维门槛高
-
原生不支持主从自动切换,集群扩容/缩容时需手动迁移数据,易出现数据倾斜。
-
对硬件依赖强,需 SSD 磁盘+高 CPU 核心数才能发挥性能,且参数调优项多(如索引粒度、合并策略),运维成本远超 Doris。
劣势对比总结表
| 对比维度 | Doris 劣势 | ClickHouse 劣势 |
|---|---|---|
| 查询性能 | 明细扫描、超宽表查询慢 | 多表 Join、复杂关联查询差 |
| 写入能力 | 高吞吐实时写入支撑不足 | 无明显劣势(写入吞吐极强) |
| 事务与更新 | 支持有限事务,更新性能一般 | 不支持跨表事务,大表更新性能极差 |
| 维度模型适配 | 无明显劣势(星型/雪花模型均兼容) | 仅适配宽表,维度动态更新成本高 |
| 生态与工具 | 实时写入生态依赖外部组件 | 数据治理、权限控制生态薄弱 |
| 运维与高可用 | 运维简单,高可用成熟 | 运维门槛高,高可用需手动保障 |
扩展: Doris vs MYSQL
核心结论:Doris 是 OLAP 分析型数据库(侧重批量聚合、多维度下钻),MySQL 是 OLTP 事务型数据库(侧重单条读写、事务一致性),核心定位差异导致功能、性能、场景适配完全不同。
核心定位与设计目标差异
-
Doris:专为大数据量 OLAP 场景设计,目标是快速响应复杂聚合查询(如百万级数据 SUM/COUNT、多维度分组),支持PB级数据存储与分析。
-
MySQL:专为联机事务处理(OLTP)设计,目标是保证单条/少量数据的读写一致性、低延迟(如用户注册、订单创建),支持事务ACID特性。
关键特性对比
1. 数据模型与存储
-
Doris:支持宽表、星型、雪花模型,以列存为主(兼顾部分行存特性),数据按分区+分桶存储,适合高压缩比、批量读取。
-
MySQL:基于关系模型,严格遵循三范式,以行存为主,按表+索引存储,数据冗余低,适合单条数据随机读写。
2. 事务与更新
-
Doris:仅支持有限事务(如单表原子导入),不支持跨表事务,
UPDATE/DELETE性能较弱,更适合写入后少更新的场景(如日志、报表数据)。 -
MySQL:原生支持 ACID 事务(InnoDB 引擎),支持行级锁、事务隔离级别,更新/删除性能优异,适合高频数据变更场景(如订单状态更新)。
3. 查询能力
- Doris:擅长复杂聚合查询(多表 Join、Group By、窗口函数),支持物化视图、预聚合,可快速响应多维度下钻分析。
- MySQL:擅长简单查询(单表 CRUD、少量条件过滤),复杂聚合(如大数据量 Group By)性能极差,多表 Join 上限低(支持但仅适合小数据量)。
4. 数据量级与性能
- Doris:支持 PB 级数据存储,单表千万级/亿级数据聚合查询响应时间在秒级/毫秒级,吞吐量高。
- MySQL:单表数据量建议控制在千万级以内,超千万级后查询/写入性能暴跌,无法支撑大数据量分析。
5. 扩展性
- Doris:支持水平扩展(增加 BE 节点提升存储和计算能力),集群部署可应对数据量增长。
- MySQL:主从复制仅能提升读性能,写性能扩展依赖分库分表(如 Sharding-JDBC),架构复杂且扩展成本高。
典型场景适配对比
| 场景类型 | 适合 Doris 的场景 | 适合 MySQL 的场景 |
|---|---|---|
| 业务场景 | 电商销售分析、用户行为报表、日志统计、多维下钻 | 网站后台管理、用户注册登录、订单创建支付、库存管理 |
| 数据操作 | 批量导入、聚合查询、报表生成 | 单条插入/更新/删除、简单条件查询 |
| 数据量级 | 百万级→PB级 | 千级→千万级(单表) |
| 响应要求 | 聚合查询秒级/毫秒级,对单条读写延迟不敏感 | 单条操作毫秒级,延迟要求严格 |
核心劣势对比
- Doris 的劣势(vs MySQL):事务支持弱,不适合高频数据变更;单条数据读写延迟高;生态工具(如ORM框架适配)不如MySQL成熟。
- MySQL 的劣势(vs Doris):大数据量聚合分析性能极差;不支持分区/分桶的大规模数据存储;多维度查询能力薄弱。
Z 总结:适用场景
-
选
Doris的情况:需实时更新、复杂数据建模、流式数据处理(如Flink/Kafka)、高并发查询,或对数据一致性要求高的场景。 -
选
ClickHouse的情况:数据以追加写为主、查询场景简单、对单表查询性能要求极高(如日志分析、监控报表),且团队有相关经验。
两者并非完全替代关系,可根据具体业务需求和技术团队能力选择。
若需兼顾实时性、更新能力和易用性,Doris更合适;若追求极致单表查询性能且运维能力较强,ClickHouse是不错的选择。
K FAQ for Clickhouse vs. Doris
Q: Clickhouse 与 Doris 在 Update / Delete 操作方面的对比?
核心结论:ClickHouse 和 Doris 均不擅长高频 Update/Delete 操作,ClickHouse 仅支持单表“标记删除+合并重写”,大表更新性能极差;Doris 支持单表原子更新/删除,性能略优但仍有限制,两者均不适合事务型高频变更场景。
Update/Delete 核心实现机制
1. ClickHouse
- 无原生行级更新能力,依赖 ALTER TABLE ... UPDATE/DELETE 语句,本质是“标记删除+后台合并重写”。
- 执行时会扫描目标分区的所有数据,标记需更新/删除的行,后续通过 MergeTree 的合并进程(background_merge_process)重写数据文件。
- 不支持跨分区更新/删除,且操作是非原子的(可能出现部分数据更新成功、部分失败的情况)。
2. Doris
- 支持单表 UPDATE/DELETE 原子操作,基于“行存索引+列存数据”的混合架构实现。
- 明细模型(Duplicate Model)通过主键索引定位目标行,直接修改数据;聚合模型(Aggregate Model)需先删除旧聚合值,再插入新聚合值。
- 支持跨分区更新/删除,操作具备原子性(要么全成,要么全败),但依赖事务日志保证一致性。
关键性能与功能对比
| 对比维度 | ClickHouse | Doris |
|---|---|---|
| 操作原子性 | 非原子(无事务保障),失败可能导致数据不一致 | 单表原子操作(支持事务日志回滚) |
| 大表操作性能 | 极差(千万级数据更新耗时小时级,引发IO风暴) | 一般(千万级数据更新耗时分钟级,影响查询性能) |
| 跨分区支持 | 不支持(仅能操作单个分区) | 支持(可跨多个分区更新/删除) |
| 批量操作效率 | 批量更新/删除与单条操作效率无差异,均需全分区扫描 | 支持批量过滤条件(如 WHERE dt > '2024-01-01'),效率优于单条操作 |
| 并发支持 | 不支持并发更新/删除,同一分区会锁表 | 支持低并发更新/删除,通过行锁减少冲突 |
| 历史版本保留 | 合并后删除标记失效,无法恢复历史数据 | 支持事务日志归档,可通过日志恢复历史版本(需手动配置) |
适用场景与限制
1. ClickHouse
- 适用场景:仅适合低频、小数据量更新/删除(如修正少量错误日志、清理过期测试数据),且更新条件需精准命中分区(减少扫描范围)。
- 核心限制:
- 千万级以上大表更新/删除会导致磁盘 IO 飙升,阻塞查询和写入。
- 频繁更新会产生大量小数据文件,触发频繁合并,进一步消耗 CPU 和磁盘资源。
- 无事务保障,异常中断后需手动清理脏数据。
2. Doris
- 适用场景:支持低频至中低频单表更新/删除(如维度表属性调整、事实表少量数据补录),适合需保证数据一致性的场景。
- 核心限制:
- 聚合模型更新需重算聚合值,性能比明细模型差 3-5 倍。
- 高频更新(如每秒数十次)会导致事务日志堆积,查询性能下降。
- 不支持跨表更新/删除,无法满足关联数据同步变更需求。
实操建议
- 若需高频更新/删除(如订单状态实时变更):两者均不推荐,优先选择 MySQL、TiDB 等事务型数据库。
- 若仅需低频修正数据(如每日少量数据补录):Doris 更优,原子性和一致性有保障,操作更简洁。
- 若必须在 ClickHouse 中处理更新:尽量将数据按“更新频率”分区,仅更新小分区数据;避免全表更新,通过 WHERE 条件精准过滤目标行。
Q: Doris / Clickhouse 的 Update/Delete 实现经验?
一、Update/Delete 实操 SQL 示例(含优化技巧)
1. ClickHouse 实操示例(低频小数据量场景)
(1)单条/少量数据 Delete
-- 优化点:精准命中分区+主键,减少扫描范围
DELETE FROM sales_wide
WHERE dt = '2024-10-01' -- 必带分区键,避免全表扫描
AND order_id = 'OD2024100100001'; -- 结合主键字段,快速定位
-- 禁止写法(全分区扫描,千万级数据耗时小时级)
DELETE FROM sales_wide WHERE order_id = 'OD2024100100001';
(2)批量 Update(小分区内)
-- 优化点:限定小分区,批量更新同维度数据
ALTER TABLE sales_wide
UPDATE member_level = 5, gmv = gmv * 1.05 -- 批量更新多字段
WHERE dt = '2024-10-01' -- 仅操作1天小分区(数据量控制在百万级内)
AND user_id IN (10001, 10002, 10003); -- 精准过滤目标用户
-- 关键优化:执行后手动触发小合并(减少临时文件)
OPTIMIZE TABLE sales_wide PARTITION '2024-10-01' FINAL;
(3)高频更新替代方案:新增版本字段(避免直接更新)
-- 1. 表结构新增版本字段(version)和生效标识(is_valid)
ALTER TABLE user_info ADD COLUMN version UInt32 DEFAULT 1;
ALTER TABLE user_info ADD COLUMN is_valid UInt8 DEFAULT 1;
-- 2. 更新时插入新版本,标记旧版本失效(写比更高效)
INSERT INTO user_info (user_id, member_level, version, is_valid)
VALUES (10001, 5, 2, 1); -- 插入新版本数据
UPDATE user_info SET is_valid = 0
WHERE user_id = 10001 AND version = 1 AND dt = '2024-10-01';
-- 3. 查询时取最新有效版本
SELECT * FROM user_info
WHERE user_id = 10001 AND is_valid = 1
ORDER BY version DESC LIMIT 1;
2. Doris 实操示例(中低频更新场景)
(1)明细模型 Delete(原子操作)
-- 优化点:结合分区+主键,利用索引快速定位
DELETE FROM log_detail
WHERE dt = '2024-10-01' -- 分区键过滤
AND log_id IN (100001, 100002); -- 主键字段,命中索引
-- 支持跨分区删除(原子性保障)
DELETE FROM log_detail
WHERE dt BETWEEN '2024-09-01' AND '2024-09-30'
AND device_type = 'test'; -- 批量清理测试数据
(2)聚合模型 Update(重算聚合值)
-- 聚合模型需先删除旧聚合值,再插入新值(Doris 内部自动完成)
UPDATE sales_fact
SET gmv = 199.99, order_cnt = 1 -- 更新聚合字段
WHERE dt = '2024-10-01'
AND user_id = 10001
AND product_id = 20001;
-- 优化点:聚合模型更新尽量批量执行,减少重复计算
UPDATE sales_fact
SET pay_cnt = pay_cnt + 1
WHERE dt = '2024-10-01'
AND product_id IN (20001, 20002, 20003); -- 批量更新同分区多商品
(3)维度表更新(适合中低频属性变更)
-- 维度表(Duplicate Model)更新,支持多字段批量修改
UPDATE product_dim
SET category2 = '手机配件', price = 129.99
WHERE product_id IN (20001, 20002);
-- 关键优化:开启分区缓存,提升更新效率
SET enable_partition_cache = true;
二、高频变更场景替代方案(核心:避直接更新,用“写替代更”)
1. 方案一:数据冗余+延迟合并(适合日志/行为数据)
- 核心逻辑:不直接更新原始数据,新增“变更日志表”记录修改内容,定期合并到主表。
- 实操步骤:
- ClickHouse/Doris 主表存储原始数据,不做更新。
- 新增变更表(如 sales_change),记录 order_id、变更字段、变更时间。
- 每日凌晨通过定时任务,将变更表数据合并到主表(批量 INSERT + DELETE)。
- 优势:避免高频更新对查询的影响,批量操作效率更高。
2. 方案二:分桶按更新频率拆分(适合用户/商品维度表)
- 核心逻辑:将高频变更数据和低频变更数据拆分到不同表/分区。
- 实操步骤:
- 高频变更维度(如用户会员等级)单独建表(user_level_info),按 user_id 分桶。
- 低频变更维度(如用户注册信息)建主表(user_base_info)。
- 查询时通过 Join 关联两表,更新时仅操作小表(user_level_info)。
- 优势:减少更新的数据量,降低 IO 和计算开销。
3. 方案三:冷热数据分离(适合历史数据极少变更场景)
- 核心逻辑:热数据(近30天,可能变更)存储在 MySQL/TiDB 等事务型数据库,冷数据(30天前,无变更)同步到 Doris/ClickHouse。
- 实操步骤:
- 热数据写入 MySQL,支持高频更新/删除。
- 每日同步30天前的冷数据到 Doris/ClickHouse,用于分析。
- 查询时通过联邦查询(如 Doris 外部表)关联热冷数据。
- 优势:兼顾事务一致性和分析性能,避开 Doris/ClickHouse 的更新短板。
三、实操避坑指南
- 无论 ClickHouse 还是 Doris,均禁止“秒级/分钟级高频更新”,否则会导致性能崩溃。
- ClickHouse 更新后需避免频繁触发合并,可通过调整
merge_max_block_size等参数控制合并频率。 - Doris 聚合模型更新时,避免跨多个大分区操作,建议按天分区逐步更新。
- 若必须高频更新,优先选择 TiDB、HBase 等支持高效更新的数据库,Doris/ClickHouse 仅作为分析副本。
要不要我针对“变更日志表合并主表”的场景,提供具体的定时任务 SQL(如 Doris 存储过程、ClickHouse 合并脚本)?
Y 推荐文献
X 参考文献

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号