[Text2SQL/AI/GPT/AWEL/RAG] DB-GPT : 开源的 AI 原生数据应用程序开发框架(MIT)
概述:DB-GPT
简介 : 什么是 DB-GPT?
-
使用
AWEL(代理工作流表达语言)和代理的AI原生数据应用程序【开发框架】 -
🤖
DB-GPT是一个开源的 AI 原生数据应用程序开发框架,具有AWEL(代理工作流表达式语言)和代理。
目的是通过开发多模型管理(
SMMF)、Text2SQL效果优化、RAG框架和优化、Multi-Agents框架协作、AWEL(代理工作流编排)等多种技术能力,构建大型模型领域的基础设施。
这使得包含数据的大型模型应用程序更简单、更方便。
🚀 在 Data 3.0 时代,基于模型和数据库,企业和开发人员可以用更少的代码构建自己的定制应用程序。
- URL
-
主要编程语言: Python / TypeScript
-
开源协议: MIT
AI原生数据库应用
- 已发布 V0.6.0 |一系列重大升级
- AWEL 升级到 2.0
- 图形 RAG
- AI Native Data App 构建和管理
- GPT-Vis 升级,支持多种可视化图表
- 支持 Text2NLU 和 Text2GQL 微调
- 支持 Intent 识别、slot 填充和 Prompt 管理
Text2SQL支持微调
支持的 LLM
- LLaMA
- LLaMA-2
- BLOOM
- BLOOMZ
- Falcon
- Baichuan
- Baichuan2
- InternLM
- Qwen
- XVERSE
- ChatGLM2
SFT Accuracy
- 截至2023年10月10日,通过该项目对一个拥有130亿个参数的开源模型进行微调,我们在Spider数据集上的执行精度甚至超过了GPT-4!
SFT Accuracy As of October 10, 2023, through the fine-tuning of an open-source model with 13 billion parameters using this project, we have achieved execution accuracy on the Spider dataset that surpasses even GPT-4!
DB-GPT-Plugins
- DB-GPT Plugins that can run Auto-GPT plugin directly
GPT-Vis
- GPT-Vis Visualization protocol
Features
私人域问答和数据处理(Retrieval-Augmented Generation)
- DB-GPT 项目提供了一系列功能,旨在改进知识库构建并实现结构化和非结构化数据的高效存储和检索。
这些功能包括对上传多种文件格式的内置支持、集成自定义数据提取插件的能力以及用于有效管理大量信息的统一矢量存储和检索功能。
支持内置、多文件格式上传、插件自抓取等方式自定义构建知识库,对海量结构化,非结构化数据做统一向量存储与检索
多数据源 & GBI(生成式商业智能/Generative Business Intelligence)
- DB-GPT 项目促进了与各种数据源(包括 Excel、数据库和数据仓库)的无缝自然语言交互,并支持分析报告。
它简化了从这些来源查询和检索信息的过程,使用户能够进行直观的对话并获得见解。
此外,DB-GPT 支持生成分析报告,为用户提供有价值的数据摘要和解释。
多代理 & 插件(Data-Driven Multi-Agents&Plugins)
- 它支持自定义插件来执行各种任务,并原生集成了
Auto-GPT插件模型。
代理协议遵循AI Agent Protocol标准。
自动化微调 text2SQL
- 围绕大语言模型、Text2SQL数据集、LoRA/QLoRA/Pturning等微调方法构建的自动化微调轻量框架, 让
TextSQL微调像流水线一样方便。
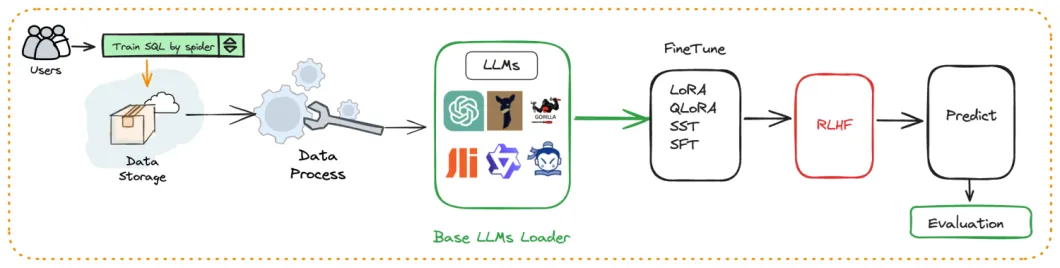
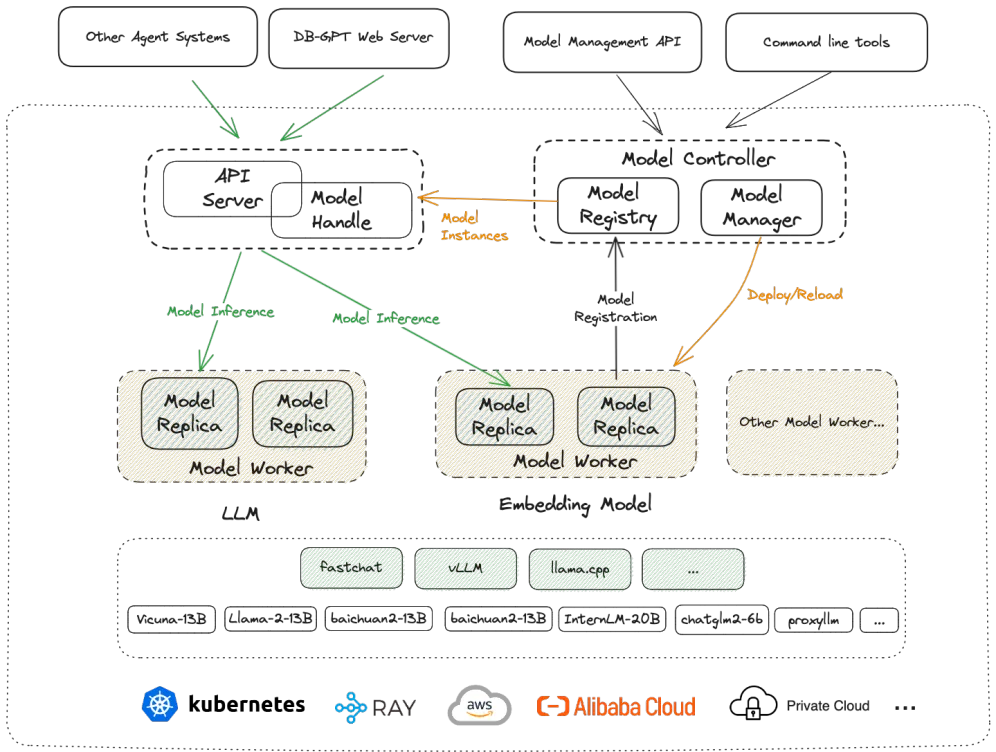
SMMF(Service-oriented Multi-Model Management Framework,面向服务的多模型管理框架)
- 我们提供广泛的模型支持,包括来自开源和 API 代理的数十种大型语言模型 (LLM),例如 LLaMA/LLaMA2、百川、ChatGLM、文心、通义、智谱等。
- News
- 🔥🔥🔥 Qwen2.5-72B-Instruct
- 🔥🔥🔥 Qwen2.5-32B-Instruct
- 🔥🔥🔥 Qwen2.5-14B-Instruct
- 🔥🔥🔥 Qwen2.5-7B-Instruct
- 🔥🔥🔥 Qwen2.5-3B-Instruct
- 🔥🔥🔥 Qwen2.5-1.5B-Instruct
- 🔥🔥🔥 Qwen2.5-0.5B-Instruct
- 🔥🔥🔥 Qwen2.5-Coder-7B-Instruct
- 🔥🔥🔥 Qwen2.5-Coder-1.5B-Instruct
- 🔥🔥🔥 Meta-Llama-3.1-405B-Instruct
- 🔥🔥🔥 Meta-Llama-3.1-70B-Instruct
- 🔥🔥🔥 Meta-Llama-3.1-8B-Instruct
- 🔥🔥🔥 gemma-2-27b-it
- 🔥🔥🔥 gemma-2-9b-it
- 🔥🔥🔥 DeepSeek-Coder-V2-Instruct
- 🔥🔥🔥 DeepSeek-Coder-V2-Lite-Instruct
- 🔥🔥🔥 Qwen2-57B-A14B-Instruct
- 🔥🔥🔥 Qwen2-72B-Instruct
- 🔥🔥🔥 Qwen2-7B-Instruct
- 🔥🔥🔥 Qwen2-1.5B-Instruct
- 🔥🔥🔥 Qwen2-0.5B-Instruct
- 🔥🔥🔥 glm-4-9b-chat
- 🔥🔥🔥 Phi-3
- 🔥🔥🔥 Yi-1.5-34B-Chat
- 🔥🔥🔥 Yi-1.5-9B-Chat
- 🔥🔥🔥 Yi-1.5-6B-Chat
- 🔥🔥🔥 Qwen1.5-110B-Chat
- 🔥🔥🔥 Qwen1.5-MoE-A2.7B-Chat
- 🔥🔥🔥 Meta-Llama-3-70B-Instruct
- 🔥🔥🔥 Meta-Llama-3-8B-Instruct
- 🔥🔥🔥 CodeQwen1.5-7B-Chat
- 🔥🔥🔥 Qwen1.5-32B-Chat
- 🔥🔥🔥 Starling-LM-7B-beta
- 🔥🔥🔥 gemma-7b-it
- 🔥🔥🔥 gemma-2b-it
- 🔥🔥🔥 SOLAR-10.7B
- 🔥🔥🔥 Mixtral-8x7B
- 🔥🔥🔥 Qwen-72B-Chat
- 🔥🔥🔥 Yi-34B-Chat
- More Supported LLMs
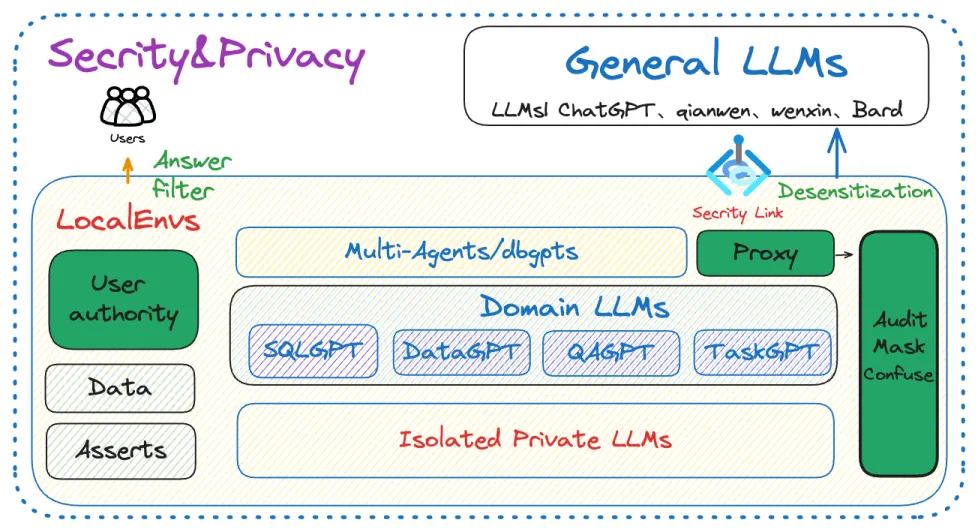
隐私与安全
- Privacy and Security
我们通过实施各种技术来确保数据的隐私和安全,包括私有化的大型模型和代理脱敏。
支持丰富的数据源
原理与架构
架构
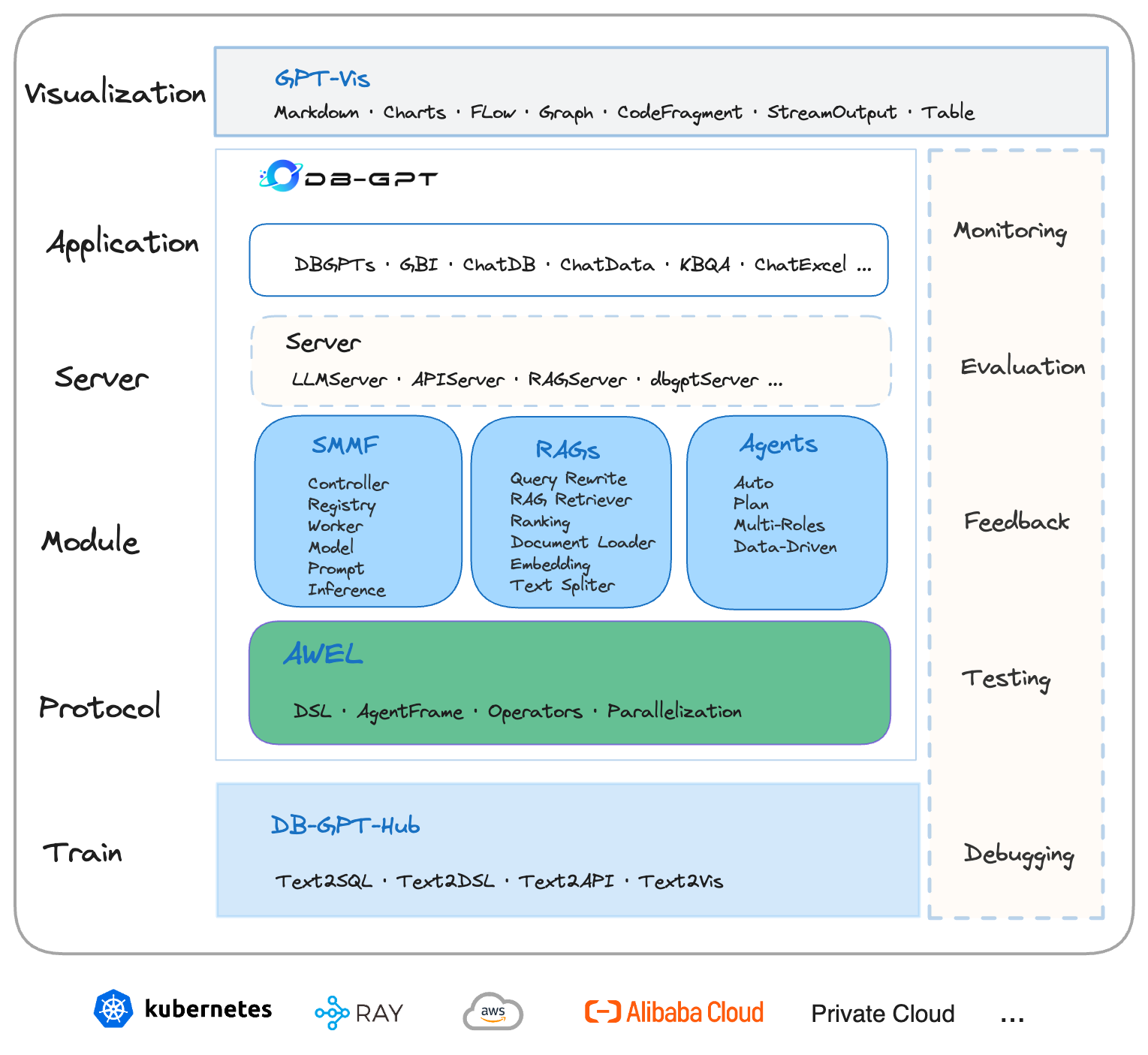
核心能力
- RAG(检索增强生成):RAG 是目前实施最实际和最迫切需要的领域。
DB-GPT 已经实现了一个基于 RAG 的框架,允许用户使用 DB-GPT 的 RAG 功能构建基于知识的应用程序。
-
GBI(生成式商业智能):生成式 BI 是 DB-GPT 项目的核心功能之一,为构建企业报告分析和业务洞察提供基础数据智能技术。
-
微调框架:模型微调是任何企业在垂直和利基领域实施不可或缺的能力。
DB-GPT 提供了一个完整的微调框架,可与
DB-GPT项目无缝集成。
在最近的微调工作中,基于Spider数据集的准确率已达到 82.5%。
-
数据驱动的多智能体框架:DB-GPT 提供了一个数据驱动的自我进化的多智能体框架,旨在根据数据不断做出决策和执行。
-
数据工厂:数据工厂主要是在大模型时代清洗和处理可信知识和数据。
-
数据源:集成各种数据源,将生产业务数据与 DB-GPT 的核心能力无缝连接。
子模块
DB-GPT-Hub
通过对大型语言模型 (LLM) 应用监督式微调 (SFT) 实现高性能的文本到 SQL 工作流。
dbgpts
dbgpts 是官方的仓库,其中包含了一些基于 DB-GPT 构建的数据应用、AWEL 运算符、AWEL 工作流模板和代理。
名词术语表
| 名词 | 说明 |
|---|---|
| DB-GPT | 一个开源的AI原生数据应用开发框架 |
| Data App/(App) | 数据应用程序,具备一组完成功能数据类应用 |
| AWEL | Agentic Workflow Expression Language, 智能体工作流表达式语言 |
| AWEL Flow | 使用智能体工作流语言编排的工作流 |
| Plugin | 插件, 主要用来完成某一个或者某一类具体的动作。 |
| Datasource | 数据源,比如MySQL、PG、StarRocks、Clickhouse等。 |
| Text2SQL/NL2SQL | Text to SQL,利用大语言模型能力,根据自然语言生成SQL语句,或者根据SQL语句给出解释说明 |
| KBQA | Knowledge-Based Q&A 基于知识库的问答系统 |
| GBI | Generative Business Intelligence 生成式商业智能,基于大模型与数据分析,通过对话方式提供商业智能分析与决策 |
| LLMOps | 大语言模型操作框架,提供标准的端到端工作流程,用于训练、调整、部署和监控LLM,以加速生成AI模型的应用程序部署 |
| Embedding | 将文本、音频、视频等资料转换为向量的方法 |
| RAG | Retrieval-Augmented Generation 检索能力增强 |
智能体编排语言(AWEL)
AWEL是什么?
AWEL(Agentic Workflow Expression Language)是一套专为大模型应用开发设计的智能体工作流表达语言
它提供了强大的功能和灵活性。
通过AWEL API您可以专注于大模型应用业务逻辑的开发,而不需要关注繁琐的模型和环境细节
AWEL采用分层 API 的设计, AWEL 的分层 API 设计架构,如下图所示:
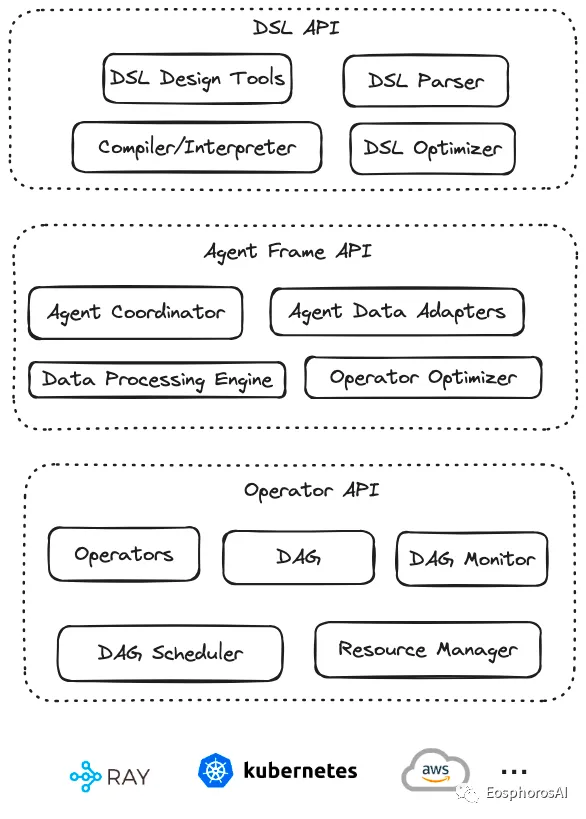
AWEL分层设计
AWEL在设计上分为三个层次,依次为算子层、AgentFrame层以及DSL层
以下对三个层次做简要介绍。
-
算子层
算子层是指LLM应用开发过程中一个个最基本的操作原子,比如在一个RAG应用开发时。
检索、向量化、模型交互、Prompt处理等都是一个个基础算子。
在后续的发展中,框架会进一步对算子进行抽象与标准化设计。
可以根据标准API快速实现一组算子。 -
AgentFrame层
AgentFrame层将算子做进一步封装,可以基于算子做链式计算。
这一层链式计算也支持分布式,支持如filter、join、map、reduce等一套链式计算操作。
后续也将支持更多的计算逻辑。 -
DSL层
DSL层提供一套标准的结构化表示语言,可以通过写DSL语句完成AgentFrame与算子的操作,让围绕数据编写大模型应用更具确定性,避免通过自然语言编写的不确定性,使得围绕数据与大模型的应用编程变为确定性应用编程。
使用案例
AWEL初步的版本也已经在V0.4.2发布,我们内置提供了一些使用样例。
算子层API-RAG例子
- 源码在项目中位置 examples/awel/simple_rag_example.py
with DAG("simple_rag_example") as dag:
trigger_task = HttpTrigger(
"/examples/simple_rag", methods="POST", request_body=ConversationVo
)
req_parse_task = RequestParseOperator()
# TODO should register prompt template first
prompt_task = PromptManagerOperator()
history_storage_task = ChatHistoryStorageOperator()
history_task = ChatHistoryOperator()
embedding_task = EmbeddingEngingOperator()
chat_task = BaseChatOperator()
model_task = ModelOperator()
output_parser_task = MapOperator(lambda out: out.to_dict()["text"])
(
trigger_task
>> req_parse_task
>> prompt_task
>> history_storage_task
>> history_task
>> embedding_task
>> chat_task
>> model_task
>> output_parser_task
)
- 位运算会将整个过程以DAG的形式编排。
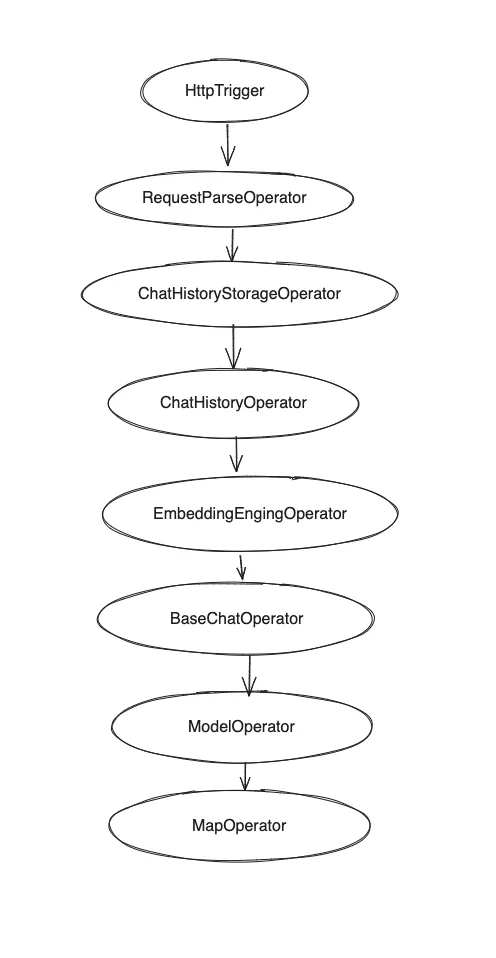
算子层API调用模型+缓存例子
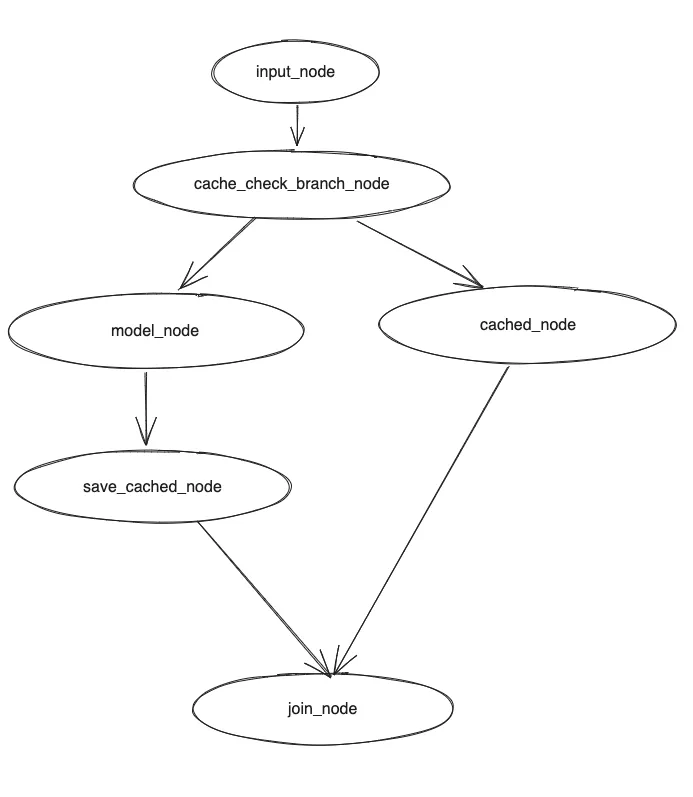
AgentFream层API样例
af = AgentFream(HttpSource("/examples/run_code", method = "post"))
result = (
af
.text2vec(model="text2vec")
.filter(vstore, store = "chromadb", db="default")
.llm(model="vicuna-13b", temperature=0.7)
.map(code_parse_func)
.map(run_sql_func)
.reduce(lambda a, b: a + b)
)
result.write_to_sink(type='source_slink')
DSL层API样例
- DSL 采用ANTLR4 / Lark解析器
CREATE WORKFLOW RAG AS
BEGIN
DATA requestData = RECEIVE REQUEST FROM
http_source("/examples/rags", method = "post");
DATA processedData = TRANSFORM requestData USING embedding(model = "text2vec");
DATA retrievedData = RETRIEVE DATA
FROM vstore(database = "chromadb", key = processedData)
ON ERROR FAIL;
DATA modelResult = APPLY LLM "vicuna-13b"
WITH DATA retrievedData AND PARAMETERS (temperature = 0.7)
ON ERROR RETRY 2 TIMES;
RESPOND TO http_source WITH modelResult
ON ERROR LOG "Failed to respond to request";
END;
当前支持的算子
- 基础算子
- BaseOperator
- JoinOperator
- ReduceOperator
- MapOperator
- BranchOperator
- InputOperator
- TriggerOperator
- 流算子
- StreamifyAbsOperator
- UnstreamifyAbsOperator
- TransformStreamAbsOperator
可执行环境
- 普通单机环境
- Ray环境
使用指南
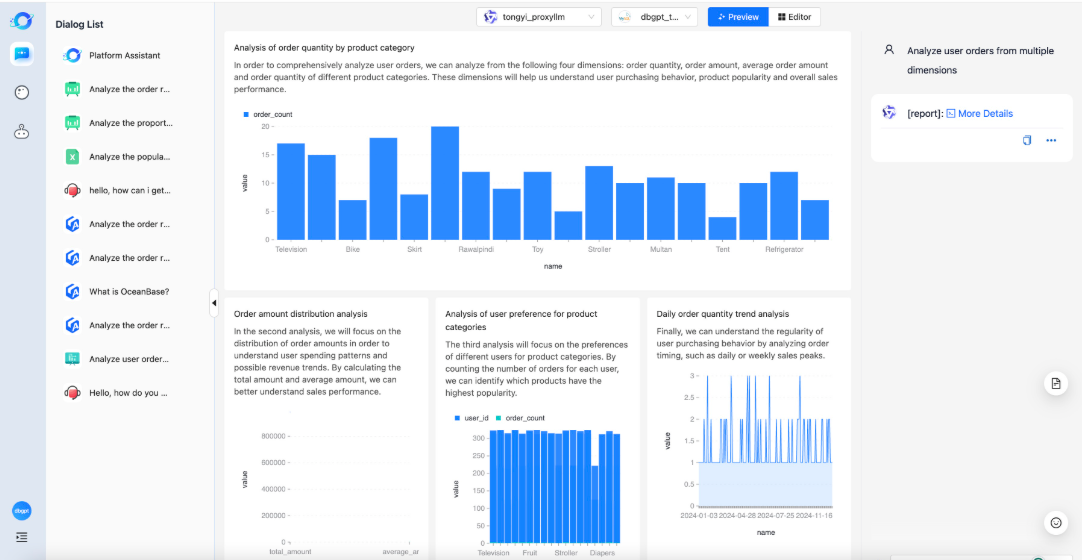
ChatExcel
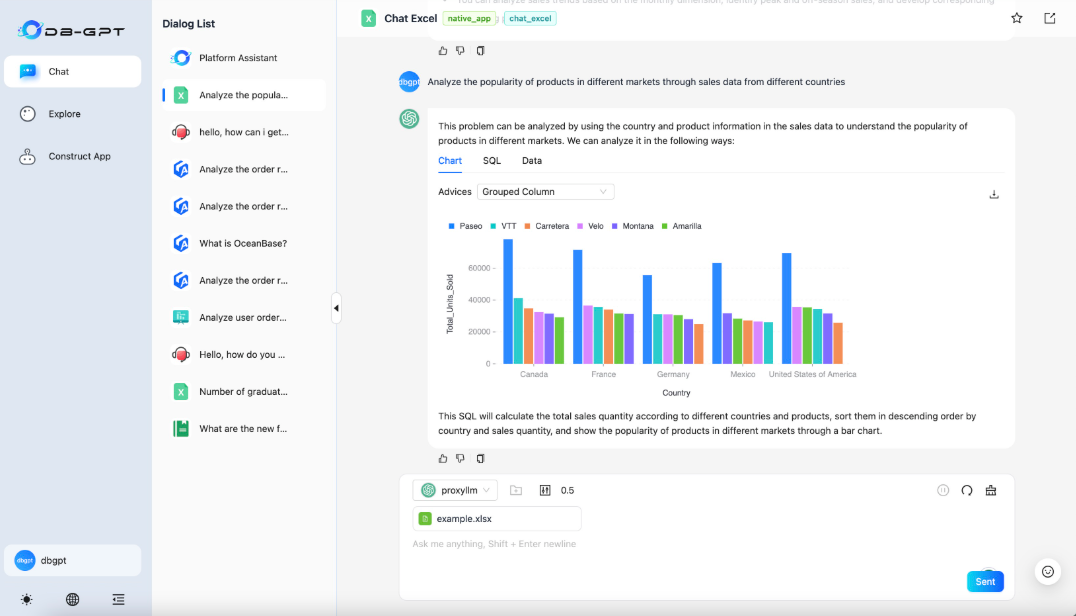
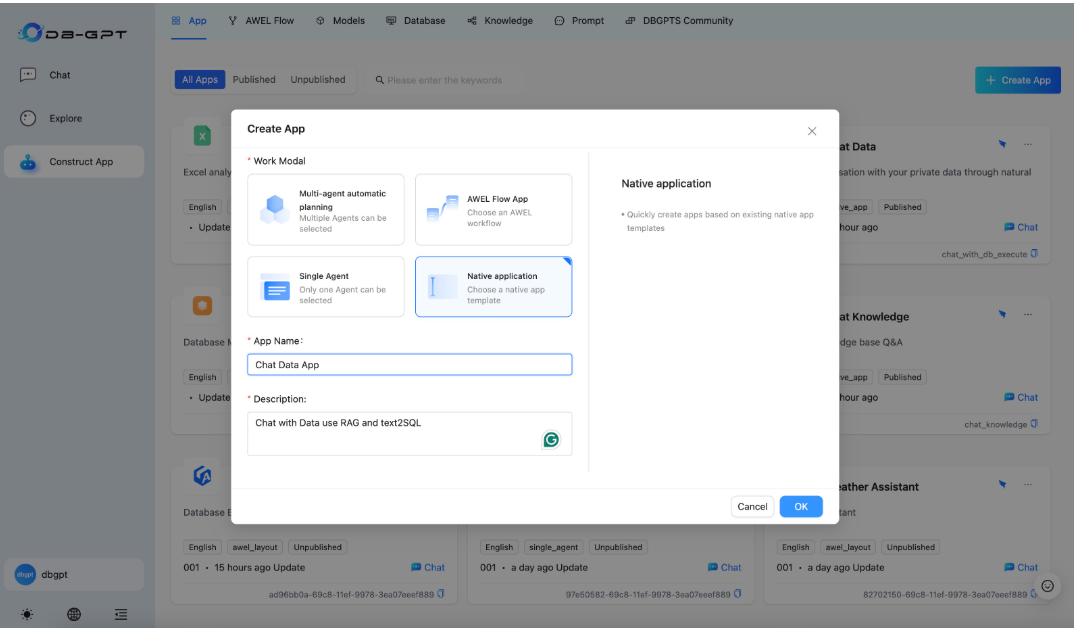
Create Application
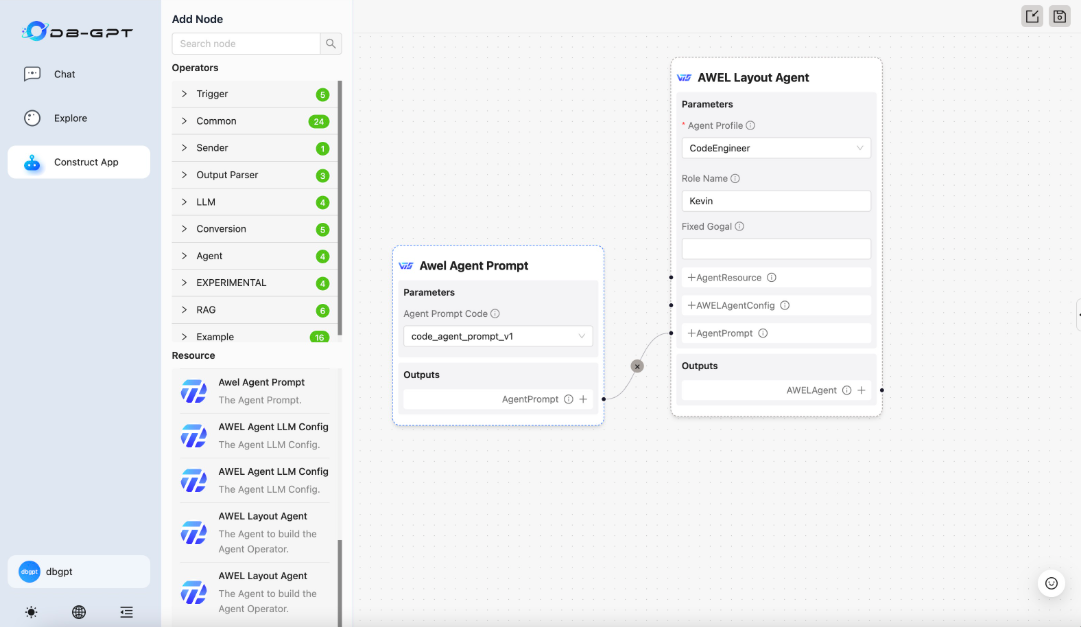
Agent Workflow/代理工作流
...
Y 推荐文献
- DB-GPT
X 参考文献

本文链接: https://www.cnblogs.com/johnnyzen
关于博文:评论和私信会在第一时间回复,或直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
日常交流:大数据与软件开发-QQ交流群: 774386015 【入群二维码】参见左下角。您的支持、鼓励是博主技术写作的重要动力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号