UDP 协议笔记
U D P是一个简单的面向数据报的运输层协议:进程的每个输出操作都正好产生一个 U D P数据报,并组装成一份待发送的 I P数据报。这与面向流字符的协议不同,如 T C P,应用程序产生的全体数据与真正发送的单个 I P数
据报可能没有什么联系。U D P数据报封装成一份 I P数据报的格式如图11 - 1所示
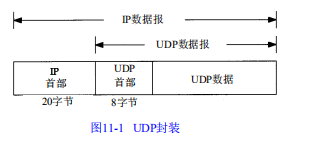
U D P不提供可靠性:它把应用程序传给 I P层的数据发送出去,但是并不保证它们能到达目的地。
应用程序必须关心 I P数据报的长度。如果它超过网络的 M T U(2 . 8节),那么就要对 I P数据报进行分片。如果需要,源端到目的端之间的每个网络都要进行分片,并不只是发送端主机连接第一个网络才这样做.

端口号表示发送进程和接收进程。在图 1 - 8中,我们画出了 T C P和U D P用目的端口号来分用来自I P层的数据的过程。由于 I P层已经把I P数据报分配给T C P或U D P(根据I P首部中协议字段值),因此T C P端口号由T C P来查看,而U D P端口号由U D P来查看。T C P端口号与U D P端口号是相互独立的。
尽管相互独立,如果T C P和U D P同时提供某种知名服务,两个协议通常选择相同的端口号。这纯粹是为了使用方便,而不是协议本身的要求。
U D P长度字段指的是U D P首部和U D P数据的字节长度。该字段的最小值为 8字节(发送一份0字节的 U D P数据报是O K)。这个 U D P长度是有冗余的。 I P数据报长度指的是数据报全长(图3 - 1),因此U D P数据报长度是全长减去 I P首部的长度。
U D P检验和覆盖U D P首部和U D P数据。回想I P首部的检验和,它只覆盖 I P的首部—并不覆盖I P数据报中的任何数据。
U D P和T C P在首部中都有覆盖它们首部和数据的检验和。 U D P的检验和是可选的,而T C P的检验和是必需的。
尽管U D P检验和的基本计算方法与我们在 3 . 2节中描述的 I P首部检验和计算方法相类似(16 bit字的二进制反码和),但是它们之间存在不同的地方。首先, U D P数据报的长度可以为奇数字节,但是检验和算法是把若干个 16 bit字相加。解决方法是必要时在最后增加填充字节0,这只是为了检验和的计算(也就是说,可能增加的填充字节不被传送)。
其次,U D P数据报和T C P段都包含一个 1 2字节长的伪首部,它是为了计算检验和而设置的。伪首部包含 I P首部一些字段。其目的是让 U D P两次检查数据是否已经正确到达目的地(例如, I P没有接受地址不是本主机的数据报,以及 I P没有把应传给另一高层的数据报传给U D P)。U D P数据报中的伪首部格式如图 11 - 3所示。
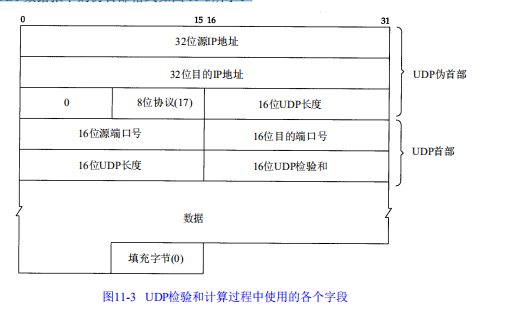
如果检验和的计算结果为 0,则存入的值为全 1(6 5 5 3 5),这在二进制反码计算中是等效的。如果传送的检验和为0,说明发送端没有计算检验和。
如果发送端没有计算检验和而接收端检测到检验和有差错,那么 U D P数据报就要被悄悄地丢弃。不产生任何差错报文(当 I P层检测到I P首部检验和有差错时也这样做)。
U D P检验和是一个端到端的检验和。它由发送端计算,然后由接收端验证。其目的是为了发现U D P首部和数据在发送端到接收端之间发生的任何改动。
尽管U D P检验和是可选的,但是它们应该总是在用。在 8 0年代,一些计算机产商在默认条件下关闭U D P检验和的功能,以提高使用 U D P协议的N F S(Network File System)的速度。在单个局域网中这可能是可以接受的,但是在数据报通过路由器时,通过对链路层数据帧进行循环冗余检验(如以太网或令牌环数据帧)可以检测到大多数的差错,导致传输失败。不管相信与否,路由器中也存在软件和硬件差错,以致于修改数据报中的数据。如果关闭端到端的U D P检验和功能,那么这些差错在 U D P数据报中就不能被检测出来。另外,一些数据链路层协议(如S L I P)没有任何形式的数据链路检验和。
Host Requirements RFC声明,U D P检验和选项在默认条件下是打开的。它还声明,如果发送端已经计算了检验和,那么接收端必须检验接收到的检验和(如接收到检验和不为0)。但是,许多系统没有遵守这一点,只是在出口检验和选项被打开时才验证接收到的检验和。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号