Redis的主从复制原理
一、Redis主从复制的工作流程大概可以分为如下几步:
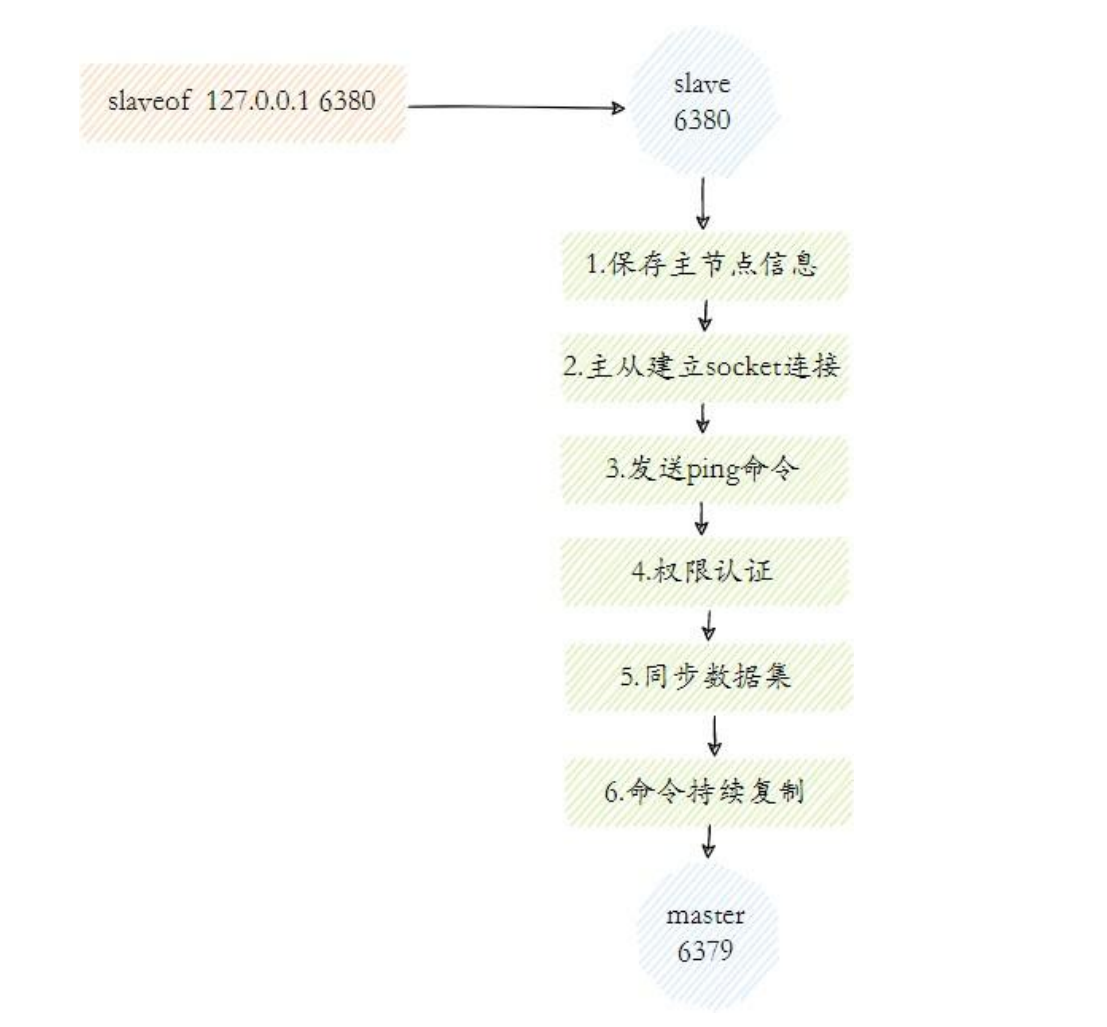
1、保存主节点(master)信息:
这一步只是保存主节点信息,保存主节点的 ip 和 port
2、主从建立连接:
从节点(slave)发现新的主节点后,会尝试和主节点建立网络连接
3、发送ping命令:
连接建立成功后从节点发送ping请求进行首次通信,主要是检测主从之间网络套接字是否可用、主节点当前是否可接受处理命令
4、权限验证:
如果主节点要求密码验证,从节点必须正确的密码才能通过验证
5、同步数据集:
主从复制连接正常通信后,首次通信主节点会把持有的数据全部发送给从节点
6、命令持续复制:
接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性
二、说说主从数据同步的方式
Redis在2.8及以上版本使用psync命令完成主从数据同步,同步过程分为:全量复制和部分复制

二、全量复制
一般用于初次复制场景,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销
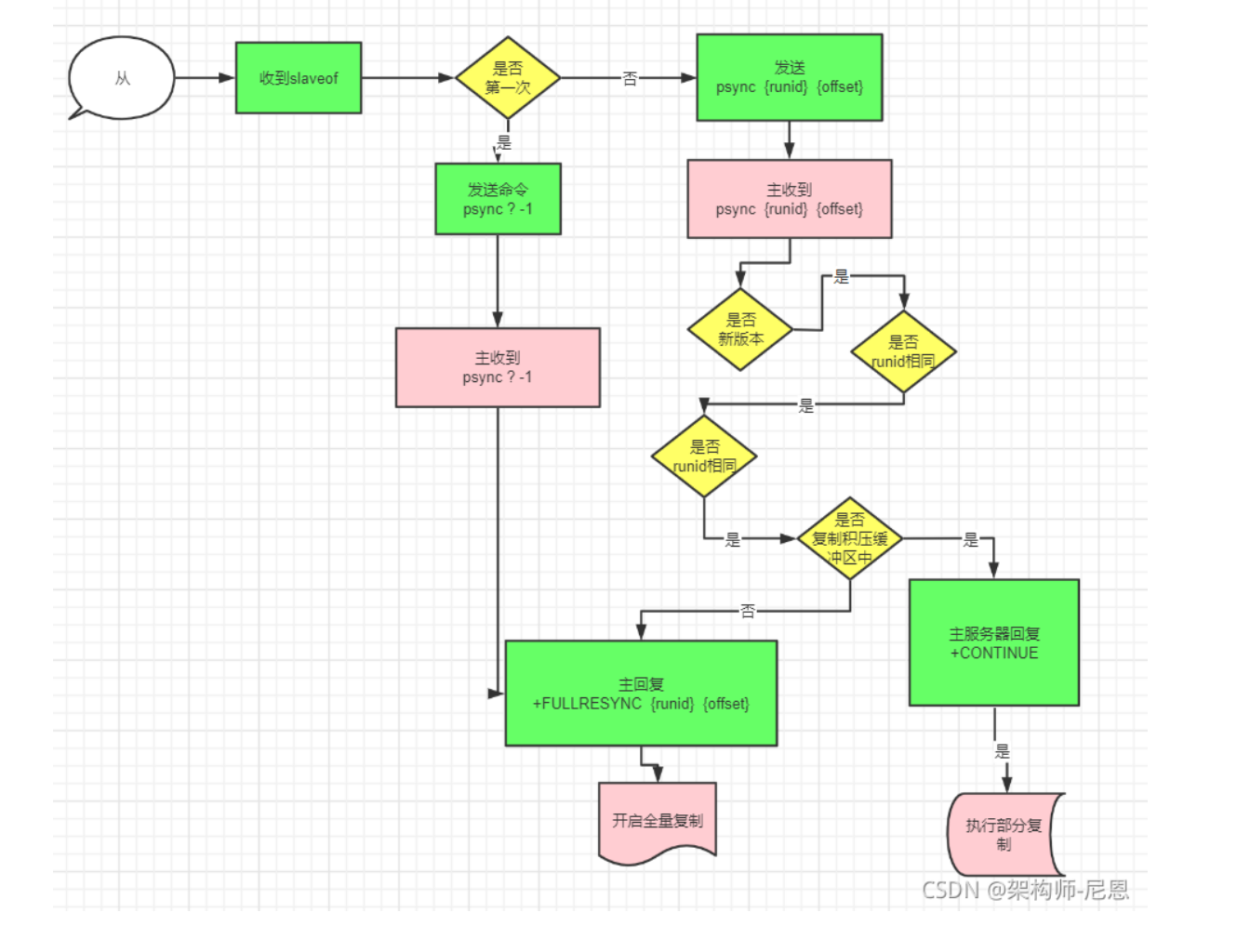
全量复制的完整运行流程如下:
复制ID与偏移量:
-
runId:主节点的唯一标识,当前主节点的运行Id
-
Offset(复制偏移量):主从节点维护的递增数字,记录当前同步的数据位置。

1. 从节点发送要进行数据同步请求的 psync命令 ,由于是第一次进行复制,从节点没有复制 偏移量 Offset 和 主节点的运行 runId,所以发送 psync-1
2. 主节点根据 psync-1 解析出,当前从节点要进行全量复制,回复从节点 FullResync响应
3. 从节点接收到主节点的响应,并在其本地保存其偏移量Offset 和 主节点的运行runId
4. 主节点执行bgsave命令,创建RDB文件并将客户端写入的命令保存到RDB中,后保存到本地
5. 主节点发送RDB文件给从节点,从节点把接收的RDB文件保存在本地并直接作为从节点的数据文件
6. 对于从节点开始接收RDB快照到执行完成这期间,如果主节点还接收到其它写命令,此时主节点会把写命令数据保存在客户端缓冲区内,
当从节点加载完RDB文件后,主节点再将缓冲区内的数据发送给从节点,保证主从之间数据一致性
7. 从节点接收完主节点传送来的全部数据后会清空自身旧数据
8. 从节点清空数据后开始加载其RDB文件
9. 从节点成功加载完RDB后,如果当前节点开启了AOF持久化功能, 它会立刻做bgrewriteaof操作,为了保证全量复制后AOF持久化文件立刻可用。
下面的流程图,也是类似的
三、部分复制
部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施, 使用psync{runId}{offset}命令实现。
当从节点(slave)正在复制主节点 (master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向主节点要求补发丢失的命令数据,
如果主节点的复制积压缓冲区内存在这部分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性

1. 当主从节点之间网络出现中断时,如果超过 repl-timeout 时间,主节点会认为从节点故障并中断复制连接
2. 主从连接中断期间,主节点依然能响应客户端发送来的命令,但因复制连接中断命令无法发送给从节点,
不过主节点将其命令保存在内部的Repl Backlog Buffer缓存中,默认最大缓存1MB
3. 当主从节点网络恢复后,从节点会再次连上主节点
4. 当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量 Offset 和 主节点的运行runId。因此会把它们当作psync参数发送给主节点,要求进行部分复制操作
5. 主节点接到psync命令后首先核对参数运行runId是否与自身一致,如果一 致,说明之前复制的是当前主节点;
之后根据参数offset在自身积压缓冲区 Repl Backlog Buffer中查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送+CONTINUE响应,表示可以进行部分复制
6. 主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态
下面的流程图,也是类似的

四、主从复制存在哪些问题呢 ?
主从复制虽好,但也存在一些问题:
-
一旦主节点出现故障,需要手动将一个从节点晋升为主节点,同时需要修改应用方的主节点地址,还需要命令其他从节点去复制新的主节点,整个过程都需要人工干预
-
主节点的写能力受到单机的限制。
-
主节点的存储能力受到单机的限制。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号