目录
1、什么是三级缓存
2、三级缓存详解
-
Bean实例化前
-
属性赋值/注入前
-
初始化后
-
总结
3、怎么解决的循环依赖
4、不用三级缓存不行吗
5、总结
一、什么是三级缓存
就是在Bean生成流程中保存Bean对象三种形态的三个Map集合,如下:

用来解决什么问题 ?
这个大家应该熟知了,就是循环依赖
什么是循环依赖 ?
就像下面这样,AService 中注入了BService ,而BService 中又注入了AService ,这就是循环依赖

这几个问题我们结合源码来一起看一下:
三级缓存分别在什么地方产生的?
三级缓存是怎么解决循环依赖的?
一定需要三级缓存吗?二级缓存不行?
二、三级缓存详解
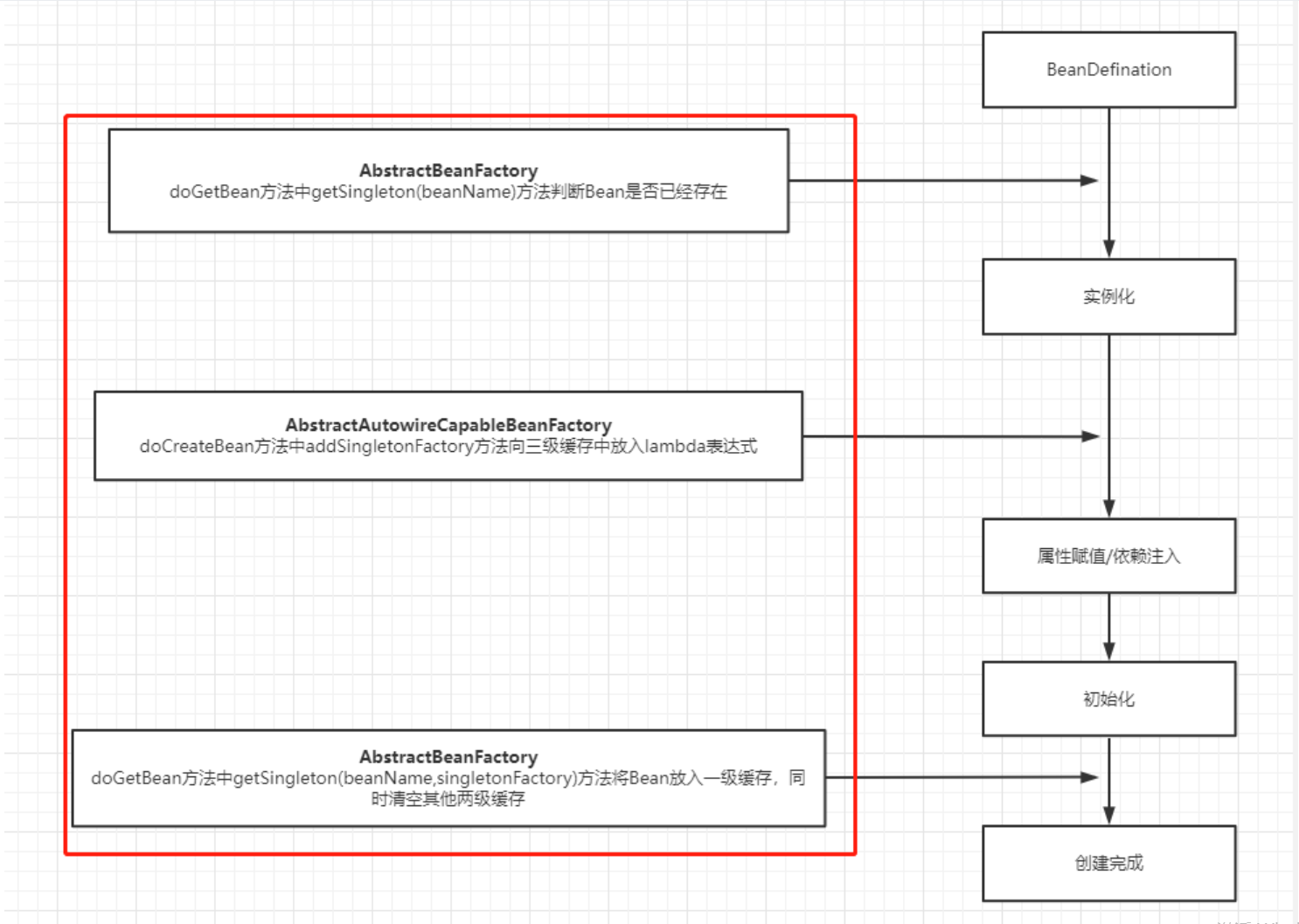
不管你了不了解源码,我们先看一下Bean的生成流程,看看三级缓存是在什么地方有调用,就三个地方:
1、Bean实例化前会先查询缓存,判断Bean是否已经存在
2、Bean属性赋值前会先向三级缓存中放入一个lambda表达式,该表达式执行时会获取一个半成品Bean放入二级缓存并删除三级缓存
3、Bean初始化完成后将完整的Bean放入一级缓存,同时清空二、三级缓存
接下来我们一个一个看!
1、Bean实例化前
AbstractBeanFactory.doGetBean
Bean实例化前会从缓存里面获取Bean,防止重复实例化

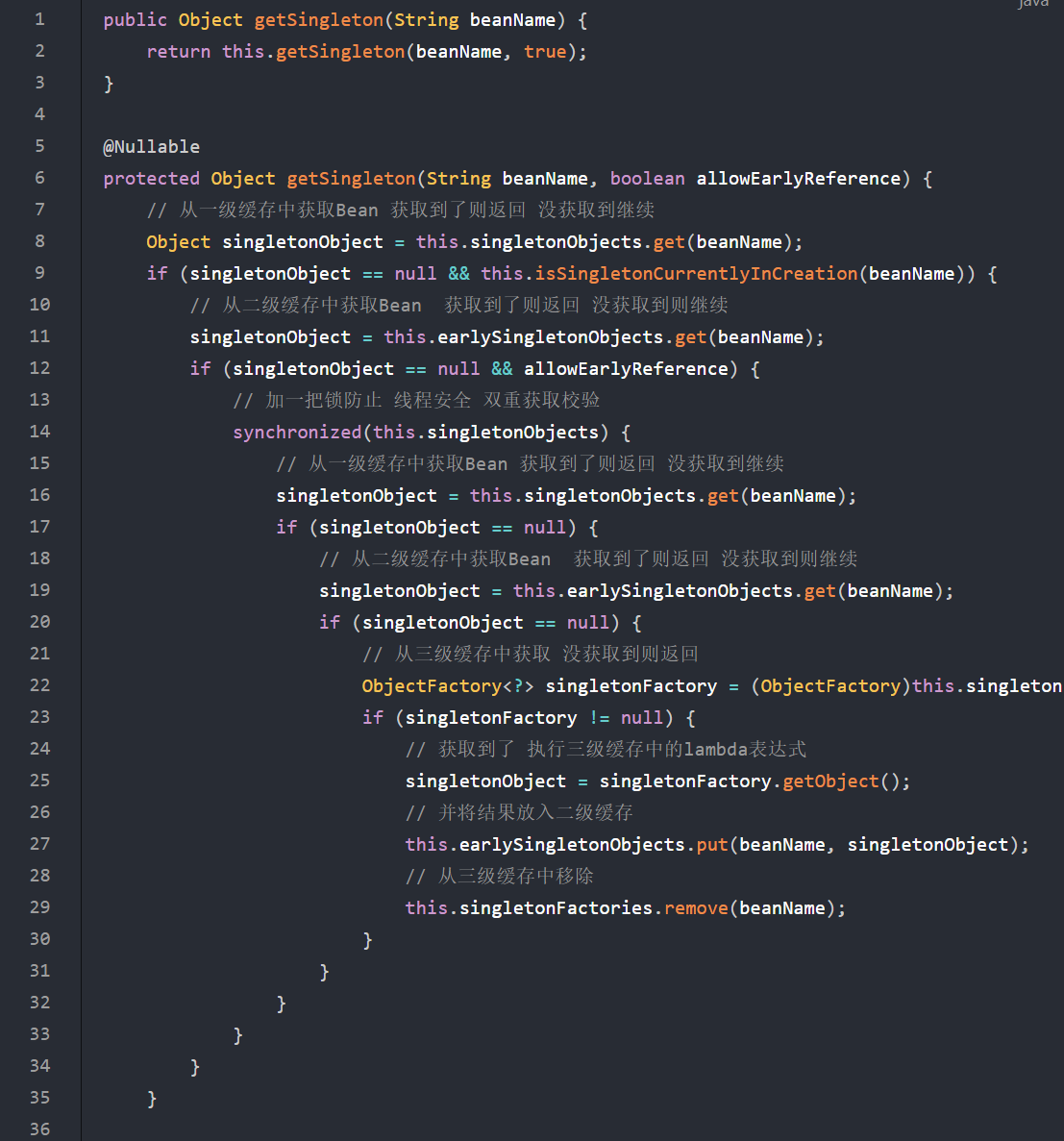
DefaultSingletonBeanRegistry.getSingleton(String beanName, boolean allowEarlyReference)
我们看看这个获取的方法逻辑:
a、从一级缓存获取,获取到了,则返回
b、从二级缓存获取,获取到了,则返回
c、从三级缓存获取,获取到了,则执行三级缓存中的lambda表达式,将结果放入二级缓存,清除三级缓存
2、属性赋值/注入前
AbstractAutowireCapableBeanFactory.doCreateBean
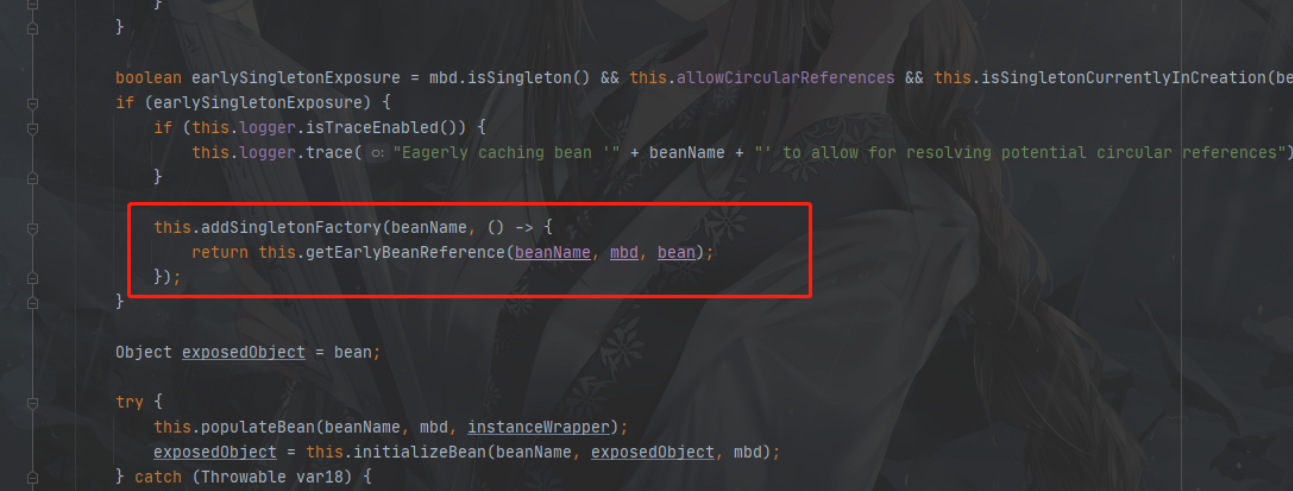
DefaultSingletonBeanRegistry.addSingletonFactory
这里就是将一个lambda表达式放入了三级缓存,我们需要去看一下这个表达式是干什么的!!

AbstractAutowireCapableBeanFactory.getEarlyBeanReference 该方法在属性赋值之前、初始化之前执行
重点,该方法说白了就是会判断该Bean是否需要被动态代理,两种返回结果:
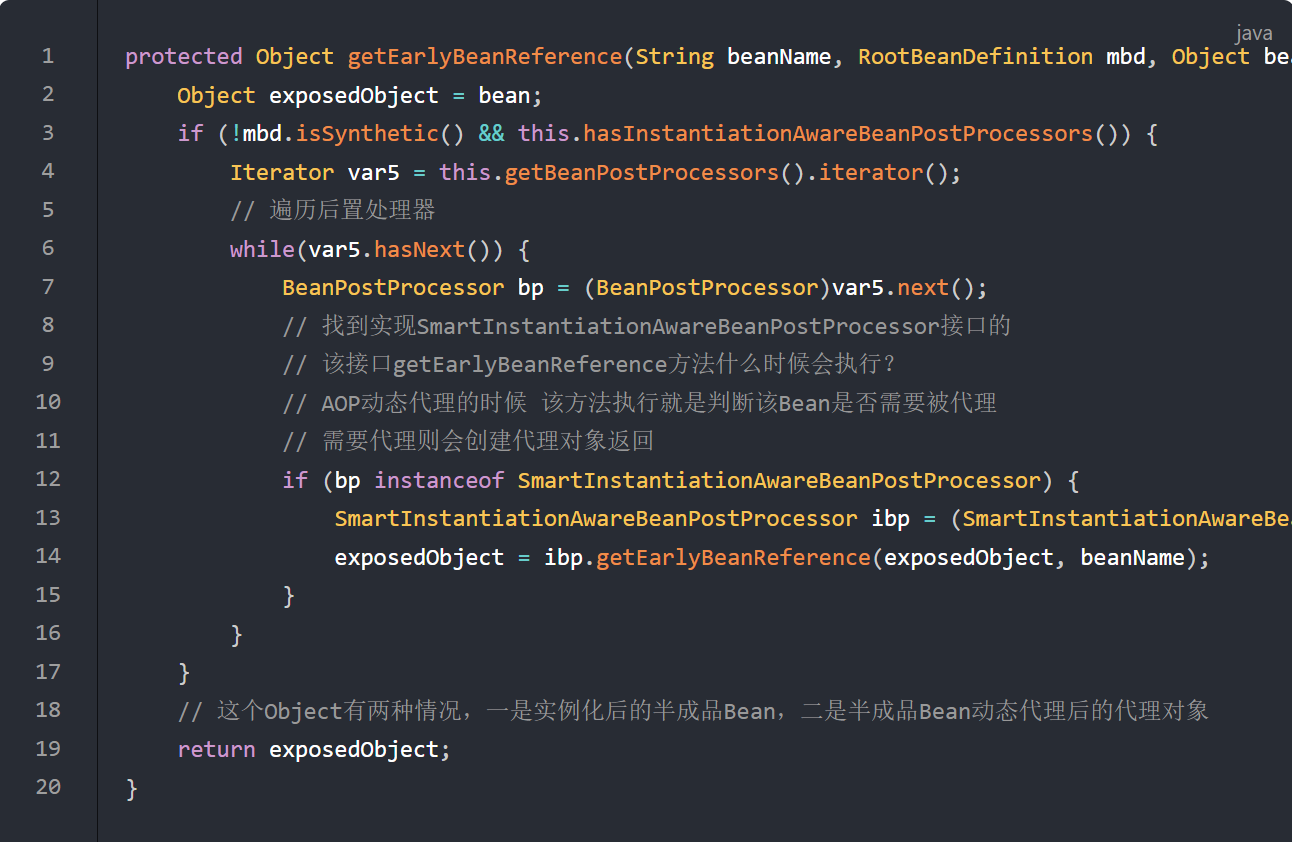
注意:这里只是把lambda表达式放入了三级缓存,如果不从三级缓存中获取,这个表达式是不执行的,一旦执行了,就会把半成品Bean 或 者半成品Bean的代理对象放入二级缓存中了
3、初始化后
AbstractBeanFactory.doGetBean
执行流程,sharedInstance = getSingleton(beanName, new ObjectFactory



 浙公网安备 33010602011771号
浙公网安备 33010602011771号