

hashtable底层
一、单线程环境下
底层:hash表结构 (数组 + 链表)
使用无参构造创建对象时 会默认长度11的数组 加载因子0.75
Hashtable<Object, Object> hashtable = new Hashtable<>();

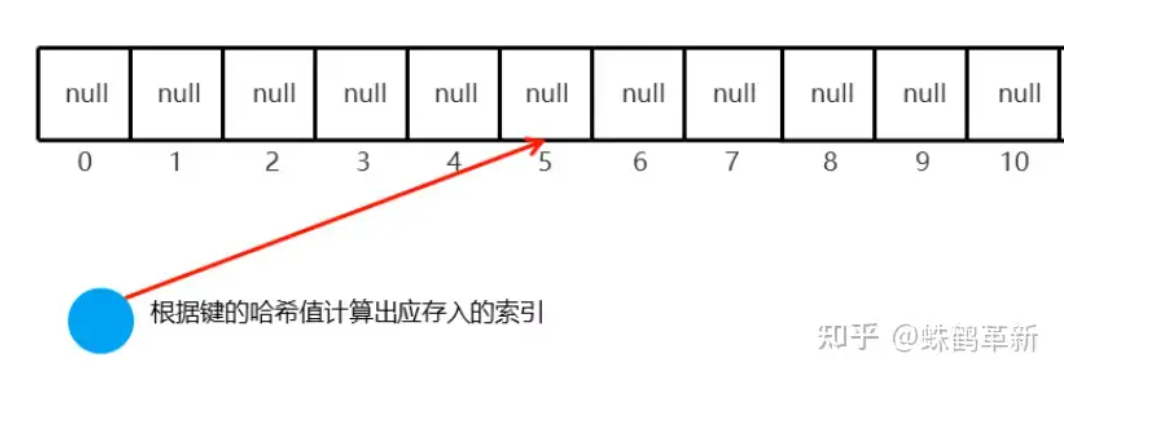
添加第一个元素
hashtable.put("键","值");
根据键的哈希值计算出应存入的索引 例: 5;然后判断 5索引上是否为 null 如果为null 直接存入元素
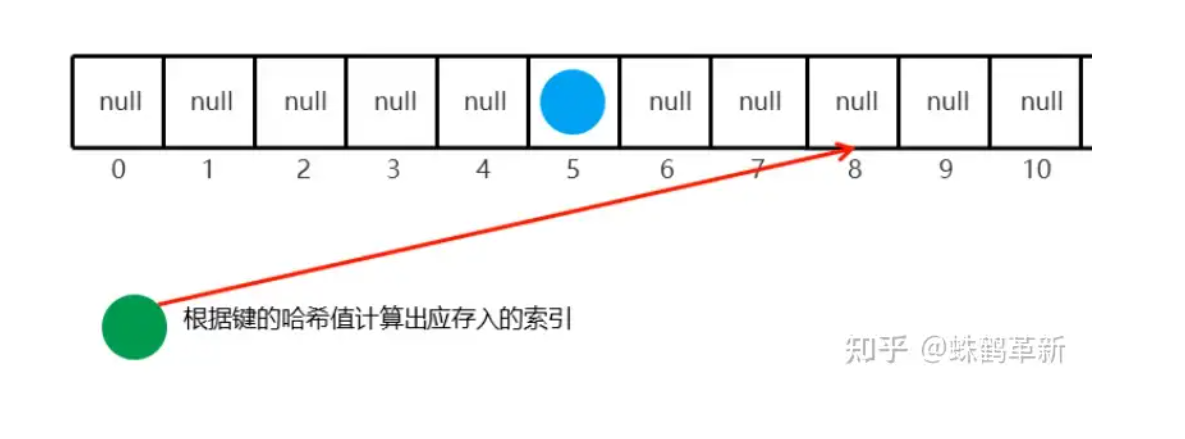
添加第二个元素
根据键的哈希值计算出应存入的索引 例: 8;然后判断 8索引上是否为 null 如果为null 直接存入元素
添加第三个元素
根据键的哈希值计算出应存入的索引 例: 5
然后判断 5索引上是否为 null
此时 5 索引上 已经有了一个元素 不为null ,则会调用equals方法比较键的属性值
如果一样,则覆盖,如果不一样,则存入数组,头插的形式,老元素挂在新元素下面 形成链表结构

二、多线程环境下
采用悲观锁的方式

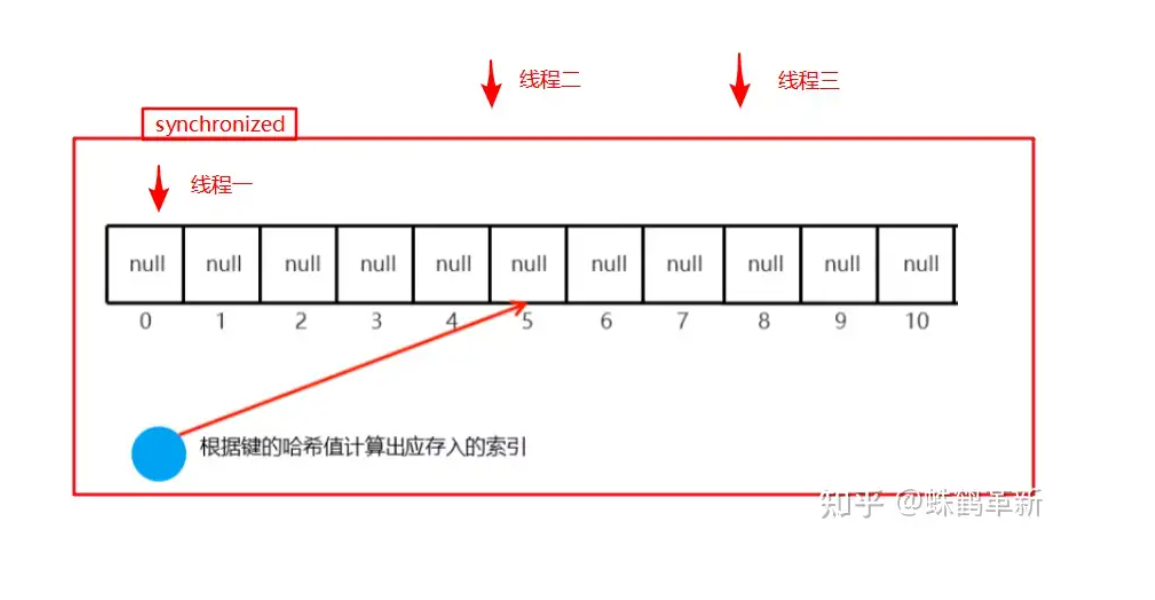
添加元素
多个线程添加元素时 ,线程一进入后 synchronized锁住整个数组 其他线程 等待锁释放 其他操作不变
三、JDK1.8 hashtable的put方法的底层源码
在 JDK 1.8 中,Hashtable 的 put 方法是线程安全的哈希表操作核心方法之一,其源码设计体现了同步机制、哈希冲突解决和动态扩容等关键逻辑。以下是详细的源码解析和实现原理:
1、put 方法源码
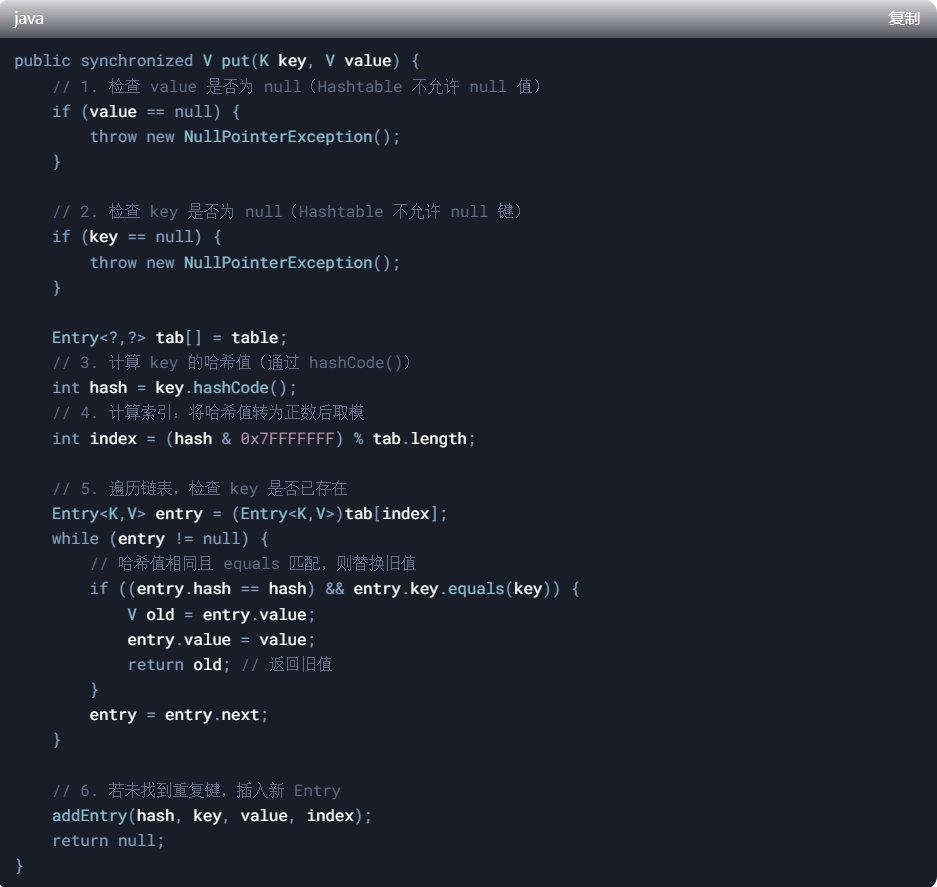
关键步骤解析
a、线程安全保证
-
put 方法被 synchronized 修饰,同一时间仅允许一个线程操作,确保线程安全
-
缺点:在高并发场景下,同步粒度较粗,可能导致性能瓶颈(相比之下,ConcurrentHashMap 使用分段锁优化)
b、空值检查
-
强制约束:Hashtable 不允许 key 或 value 为 null,直接抛出 NullPointerException
-
对比:HashMap 允许 null 键和值,但需特殊处理(如 hashCode 为 0)
c、哈希值计算
-
通过 key.hashCode() 获取哈希值
-
哈希修正:hash & 0x7FFFFFFF 将哈希值转为正数(索引必须非负)
d、索引定位
-
通过 (hash % tab.length) 计算索引(tab.length 是哈希表数组长度)
-
问题:取模运算可能效率较低(HashMap 使用位运算优化)
e、链表遍历
-
在计算出的索引位置遍历链表,检查是否存在相同键:
-
若存在,直接替换旧值并返回旧值
-
若不存在,调用 addEntry 插入新节点
-
2、插入新节点(addEntry)
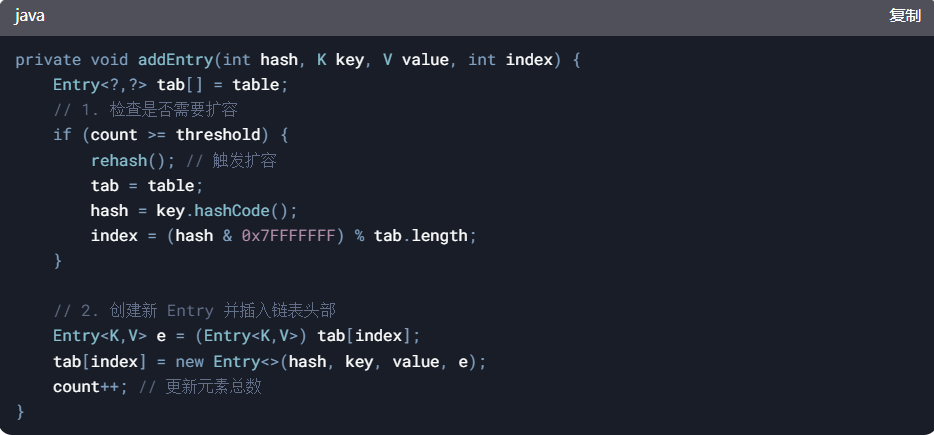
-
扩容条件:当元素数量 count 超过阈值 threshold(默认 capacity * loadFactor)
-
头插法:新节点插入链表头部(JDK 1.8 的 HashMap 改为尾插法避免循环链表问题)
3、扩容机制(rehash)
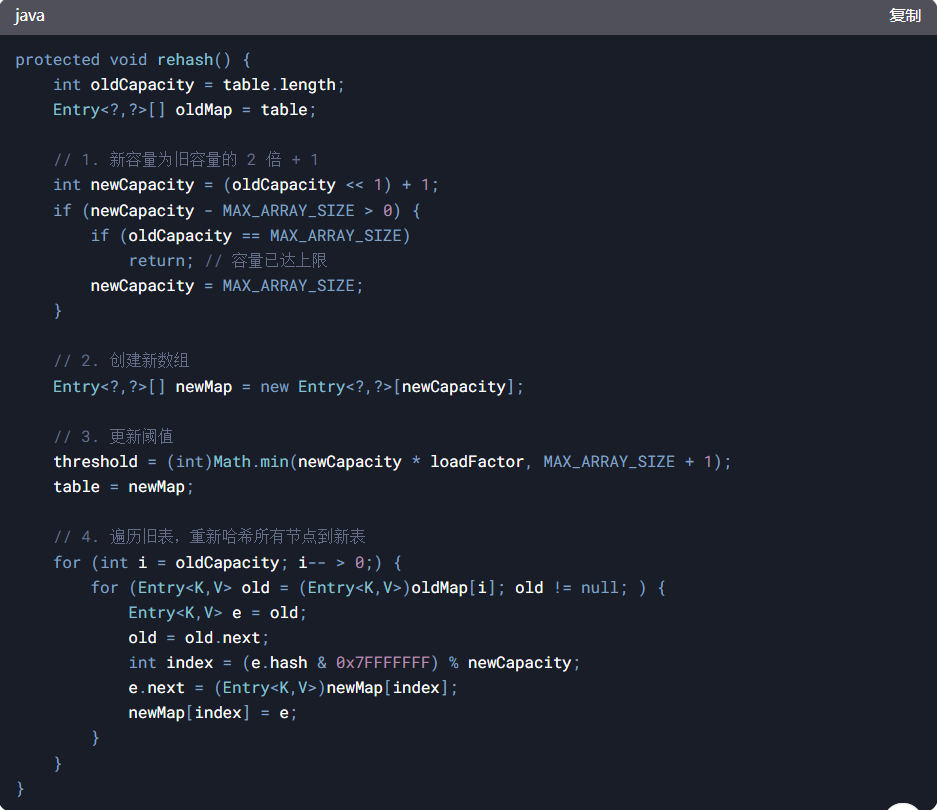
-
新容量:newCapacity = 2 * oldCapacity + 1(非严格的 2 倍扩容)
-
重新哈希:所有节点需重新计算索引,并迁移到新数组
四、put方法的整个处理流程分析
put方法的整个处理流程是:计算key的hash值,根据hash值获得key在table数组中的索引位置,然后迭代该key处的Entry链表,若该链表中存在一个这个的key对象,那么就直接替换其value值即可,
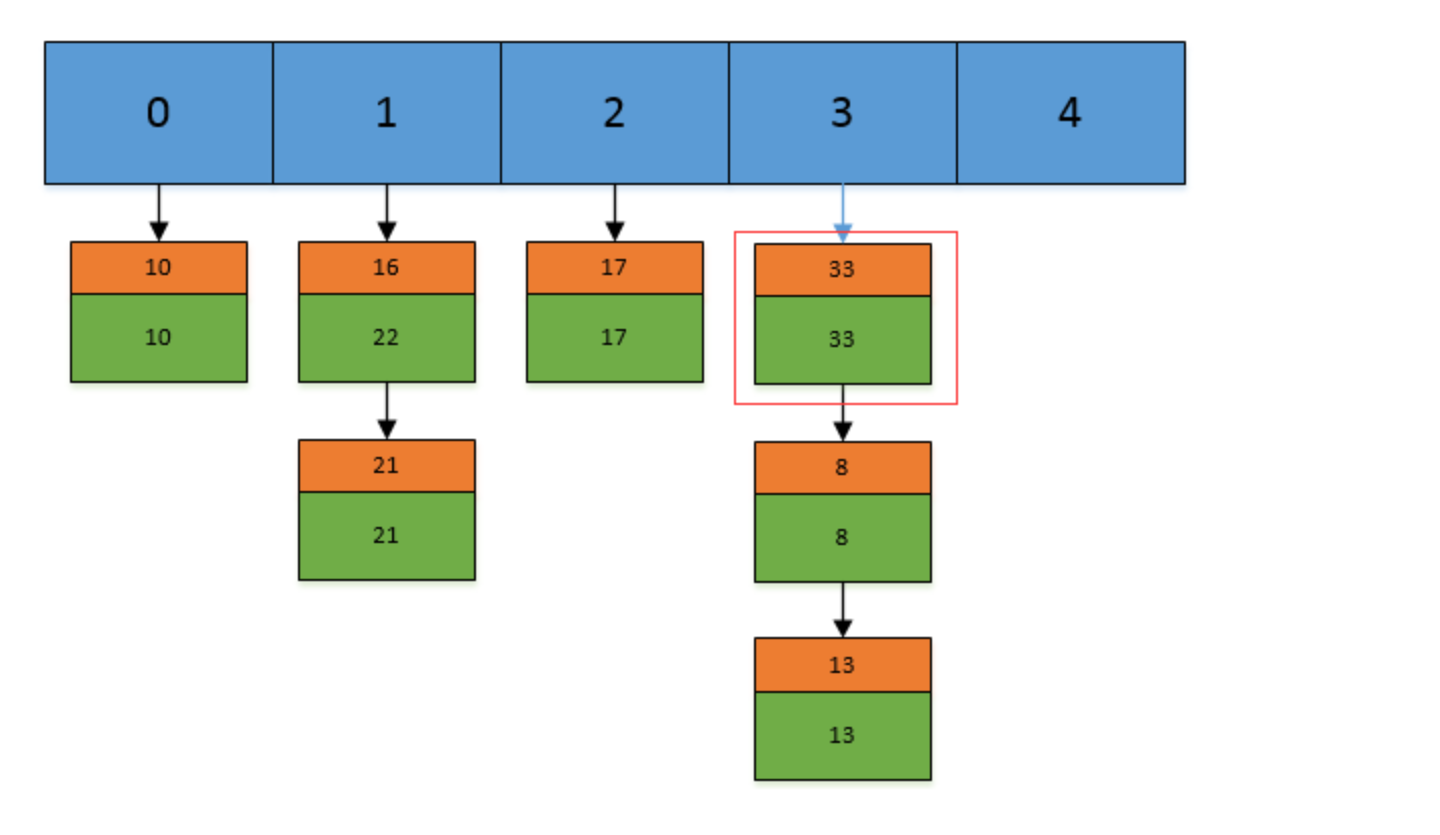
否则在将改key-value节点插入该index索引位置处。如下:假设我们现在Hashtable的容量为5,已经存在了(5,5),(13,13),(16,16),(17,17),(21,21)这 5 个键值对,目前他们在Hashtable中的位置如下:
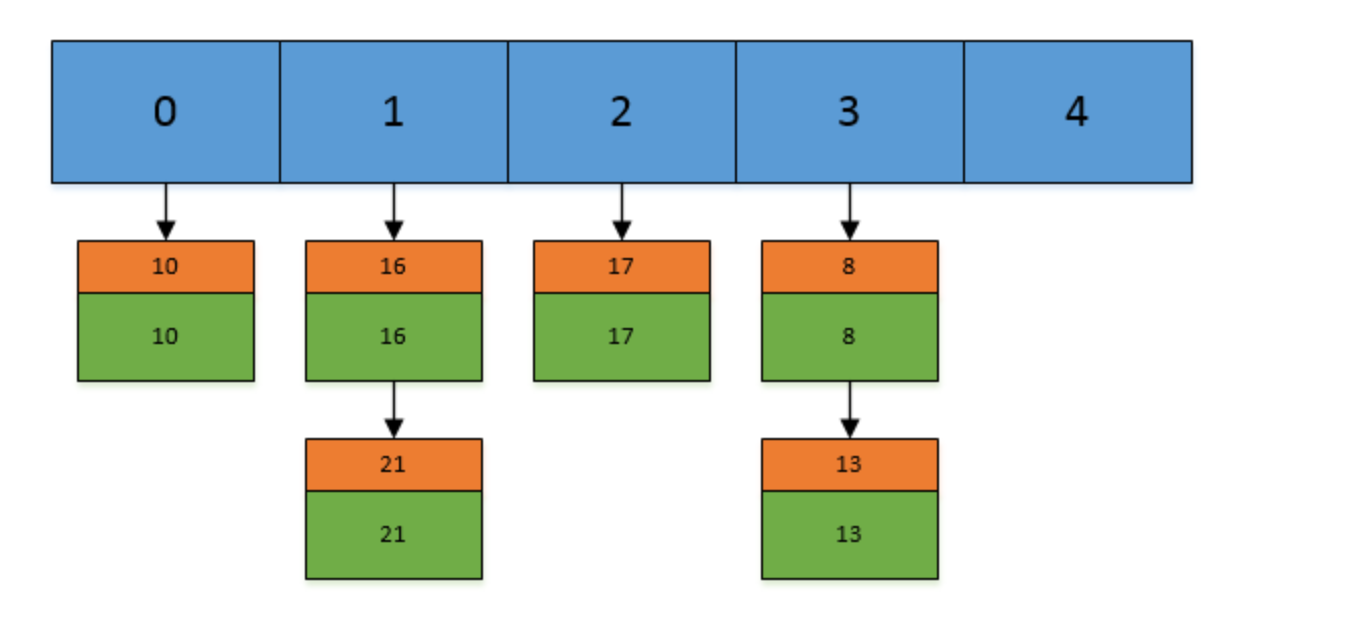
现在,我们插入一个新的键值对,put(16,22),假设key=16的索引为1.但现在索引1的位置有两个Entry了,所以程序会对链表进行迭代。迭代的过程中,发现其中有一个Entry的key和我们要插入的键值对的key相同,
所以现在会做的工作就是将newValue=22替换oldValue=16,然后返回oldValue=16.
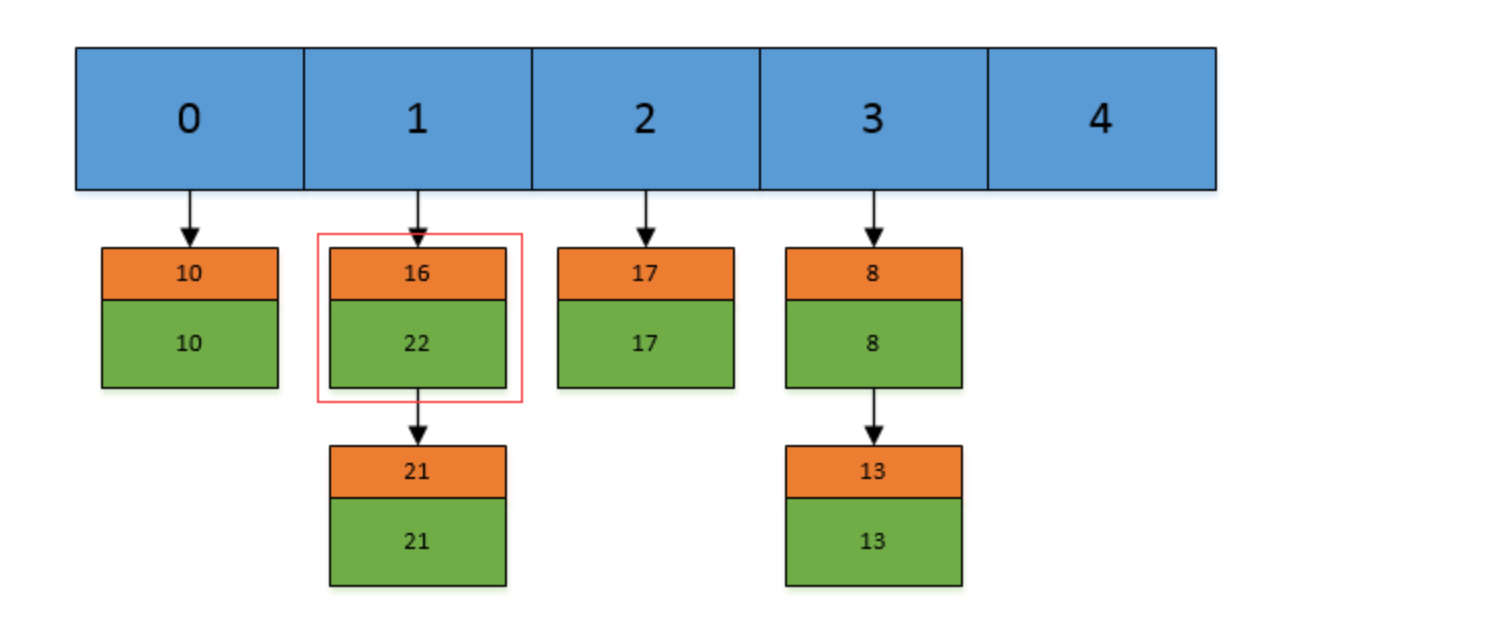
然后我们现在再插入一个,put(33,33),key=33的索引为3,并且在链表中也不存在key=33的Entry,所以将该节点头插入链表的第一个位置。
五、总结
-
设计目标:Hashtable 是早期线程安全哈希表实现,通过方法级同步保证安全
-
缺点:
-
锁粒度粗,并发性能差
-
不支持 null 键值
-
哈希冲突处理简单(仅链表,无红黑树优化)
-
-
适用场景:低并发环境或需要兼容旧代码时(现代开发更推荐 ConcurrentHashMap)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号