spring的循环依赖问题
一、循环依赖问题详解
1、产生循环依赖的流程图
有两个类A和B,A中调用了对象b,B中调用了对象a,在创建A需要b的时候会去创建B,而在创建B的时候又需要a,此时类A还没有创建完成,这样就形成了类A和类B之间依赖关系的闭环

如果想破开这个闭环,突破口就是最后一步的“没有找到A对象”。其实最后一步在容器中查找A对象的时候,此时对象A已经存在,这个要认识两种概念,“对象完成实例化且完成初始化”的称为“成品对象”,而“对象完成实例化但未完成初始化”的称为“半成品对象”,“实例化”和“初始化”不是同时进行的
2、源码中产生循环依赖的流程

3、循环依赖问题在spring中主要有三种情况
-
1、通过构造方法进行依赖注入时产生的循环依赖问题。
-
2、通过setter方法进行依赖注入且是在多例(原型)模式下产生的循环依赖问题。
-
3、通过setter方法进行依赖注入且是在单例模式下产生的循环依赖问题
第(3)种方式的循环依赖问题被解决了,因为Bean的创建与注入是可以分开的,即先创建Bean实例,再用反射调用方法或字段,完成注入
第(1)种构造方法注入的情况下,在new对象的时候就会堵塞住了,因为Bean的创建与注入是一体的,我们无法把它们分成两个阶段,也无法中断方法内部代码的执行,所以通过构造方法进行依赖注入时产生的循环依赖问题,是无解的。
第(2)种setter方法(多例)的情况下,每一次getBean()时,都会产生一个新的Bean,如此反复下去就会有无穷无尽的Bean产生了,最终就会导致OOM问题的出现
4、Spring支持的4种依赖注入模式
a、构造函数注入(Constructor Injection)
-
描述:通过构造函数将依赖项注入到bean中。Spring容器在创建bean时,通过构造函数将所有所需的依赖项传递给bean。
-
优点:构造函数注入使得bean的依赖项在创建时即被设置好,这使得bean在完全初始化后是不可变的,更符合面向对象编程的原则(即强制bean在创建时即完成所有必需的依赖项注入
@Component public class Student{ private final Address address; public Student(Address address) { this.address= address; } } spring的bean.xml配置 <bean id="student" class="com.itheima.entity.Student" init-method="init" destroy-method="destroy"> // 将address注入student的构造方法中 <constructor-arg name="address" ref="address" /> </bean>
b、Setter方法注入(Setter Injection)
-
描述:通过setter方法将依赖项注入到bean中。Spring容器会调用bean的setter方法来注入依赖项。
-
优点:setter方法注入允许依赖项在bean创建后被设置,使得bean在创建后可以有更多的灵活性来进行设置
@Component public class ExampleService { private DependencyService dependencyService; public void setDependencyService(DependencyService dependencyService) { this.dependencyService = dependencyService; } } spring的bean.xml配置 <bean id="student" class="com.itheima.entity.Student" init-method="init" destroy-method="destroy"> // 将address注入student <property name="address" ref="address" /> </bean>
c、字段注入(Field Injection)
-
描述:直接将依赖项注入到bean的字段中,通常使用@Autowired注解在字段上
-
优点:字段注入最简单,配置最少。但它不利于单元测试,因为字段是私有的,依赖项不能通过构造函数或setter方法注入,测试时可能需要使用反射
@Component public class ExampleService { @Autowired private DependencyService dependencyService; }
5、解决循环依赖问题的流程图

-
1、设置map缓存,用来存放对象,在完成实例化对象A的时候,将半成品对象A放进缓存
-
2、在实例化对象B的时候,将半成品对象B放进缓存
-
3、在容器中查找A对象的时候,能找到半成品的对象A,然后完成对象B的初始化工作,得到成品对象B,并且将成品对象B放进缓存
-
4、回到初始化A对象过程中从容器中查找B对象的那一步,此时就可以查找到一个成品对象B,接着就可以完成对象A的初始化工作了
6、三级缓存介绍
a、三级缓存的代码:DefaultSingletonBeanRegistry类
/**
* 一级缓存:存储所有已创建完毕的单例 Bean (完整的 Bean)
*
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/**
* 三级缓存:存储能建立这个 Bean 的一个工厂,通过工厂能获取这个 Bean,延迟化 Bean 的生成,工厂生成的 Bean 会塞入二级缓存
*
*
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
/**
* 二级缓存:存储所有仅完成实例化,但还未进行属性注入和初始化的 Bean
*
*
* Cache of early singleton objects: bean name --> bean instance */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
b、spring三大缓存介绍
(1)一级缓存:Map<String, Object> singletonObjects
1、第一级缓存的作用:
* 用于存储单例模式下创建的Bean实例(已经创建完毕)
* 该缓存是对外使用的,指的就是使用Spring框架的程序员
2、存储什么数据?
* K:bean的名称
* V:bean的实例对象(有代理对象则指的是代理对象,已经创建完毕)
(2)第二级缓存:Map<String, Object> earlySingletonObjects
第二级缓存的作用:
* 用于存储单例模式下创建的Bean实例(该Bean被提前暴露的引用,该Bean还在创建中,完成了实例化,但是属性都是空的)。
* 该缓存是对内使用的,指的就是Spring框架内部逻辑使用该缓存。
* 为了解决第一个classA引用最终如何替换为代理对象的问题(如果有代理对象)
(3)第三级缓存:Map<String, ObjectFactory<?>> singletonFactories
1、第三级缓存的作用:
* 通过ObjectFactory对象来存储单例模式下提前暴露的Bean实例的引用(提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象)
* 该缓存是对内使用的,指的就是Spring框架内部逻辑使用该缓存
* 此缓存是解决循环依赖最大的功臣
2、存储什么数据?
* K:bean的名称
* V:ObjectFactory,该对象持有提前暴露的bean的引用
7、三级缓存的debug流程详解
a、源码中留意的6个重要方法
(1)getBean
(2)doGetBean
(3)createBean
(4)doCreateBean
(5)createBeanIntance
(6)populateBean
在创建对象的时候,先到容器中根据beanName查一下是不是已经创建这么个bean对象了,调用getBean(beanName)方法来获取,接着调用doGetBean方法,在判断bean的单例对象是否存在的时候,此刻返回的bean对象应该是空的

既然是空的就会往下走去创建对象,跳过一系列的判断条件,走到下面这个getSingleton方法,这里方法的参数有一个lambda表达式,表达式中有一个方法createBean用来创建bean对象,实际上它并不会实际被调用,只是当做参数先被传递
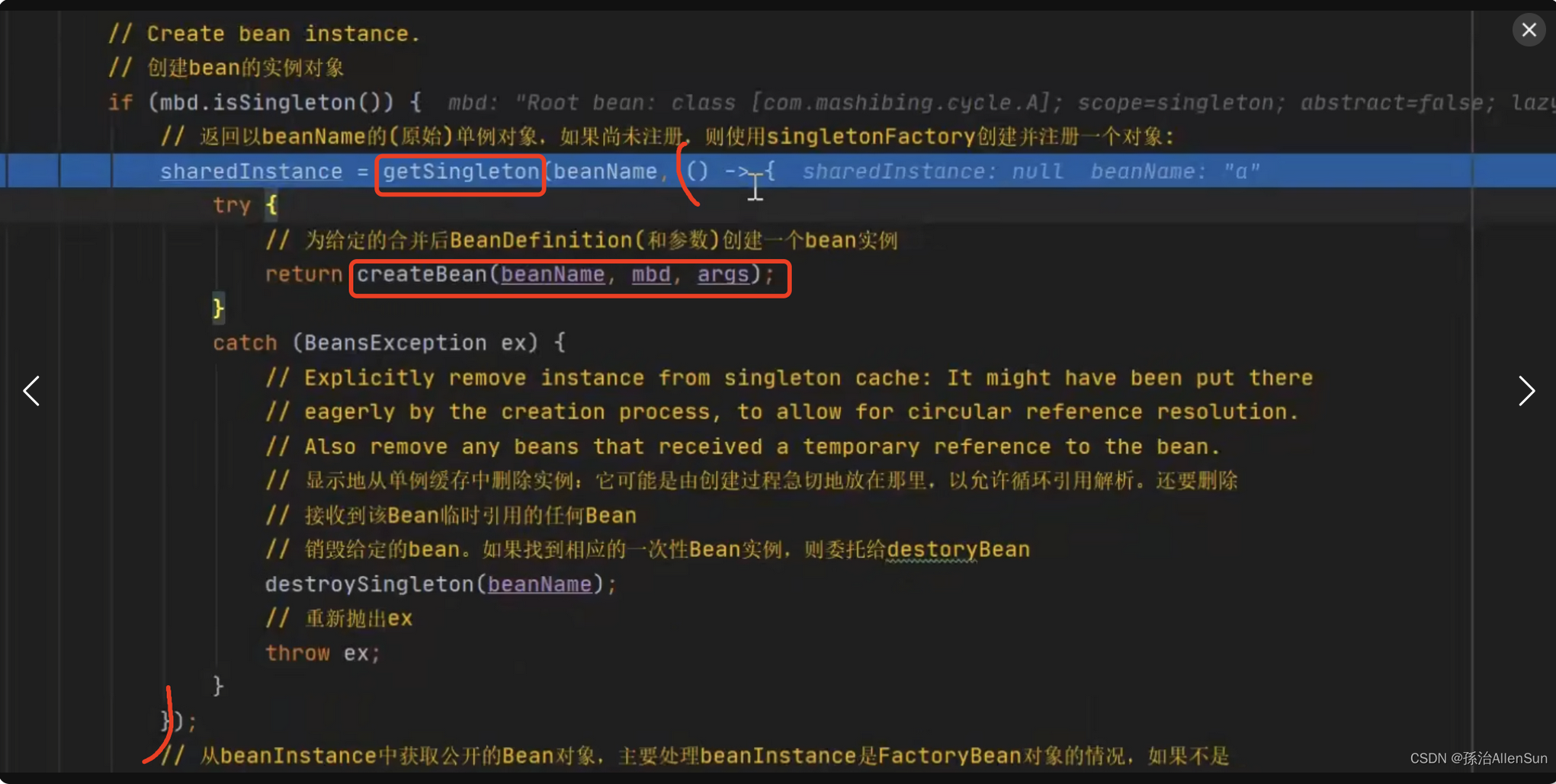
走到都doCreateBean方法

走到createBeanInstance方法,进行具体的实例化操作

往下走,通过反射获取构造器,然后创建具体的对象

在这里完成通过反射获取对象

此时对象A已经有了

在A完成实例化之前,创建代理对象放进三级缓存,传递的又是一个lambda表达式

详细看这个方法时如何实现把对象放入三级缓存的,这里是把参数传进来的lambda表达式当做value,把beanName当做key放进三级缓存的map中去

此时对象A已经完成了实例化,接下来开始属性填充,就会开始给B对象属性进行赋值

接下来进入属性赋值的最终方法

在赋值的过程中遍历属性,获取属性的名字(也就是对象b)和值(记住这个值)

上面获取的value值不是b类型对象,在必须的情况下要对这个值进行一个处理工作

进入处理方法后,判断value是否匹配,就跟前面的RuntimeBeanReference对应起来了,就可以进入判断内部。对value值进行强转和解析,得到封装的Bean对象,也就是b对象

进入解析的具体方法,就会接触到实际获取b对象的方法,实际就是getBean方法,开始套娃,循环上述流程开始创建b对象。getBean方法先去容器里判断是不是有已经创建好的b对象,然后再决定要不要开始创建。

接下来的步骤跟刚才创建对象a的步骤一模一样,省略其中的步骤,到对象b实例化最后一步的时候,要把对象b的代理对象放进三级缓存

接下来完成实例化后也要开始b对象的属性填充了,就会碰到属性a对象的填充了,依旧是解析对象a

往下走又遇到getBean方法,这次要获取的是对象a

走doGetBean方法进入getSingleton方法尝试去获取对象a

下面就是获取a对象方法的实际主体,在这里会依次到一级缓存、二级缓存、三级缓存中去尝试获取对象a,如果是在三级缓存缓存中找到的对象a的对象工厂(lambda表达式),就要通过getObject方法调用前面传的lambda表达式来创建一个单例对象a

getObject方法跳转进去的就是对应的lambda表达式

进入这个lambda表达式,提前暴露对象,设置代理对象,判断是否有AOP需要处理,返回最终的代理对象

通过getObject方法调用对象工厂的lambda表达式返回一个单例对象a之后,把这个新的单例对象a存入二级缓存,最后把三级缓存中的对象工厂a给删除

取到a对象了,刚才取a对象的目的就是因为要给b对象进行属性填充,所以有了a对象后就可以完成给b对象的属性填充了,此时b对象中的a是有值的,b也就是成品对象了,把成品对象b放进一级缓存里,并且从三级缓存里删除b的对象工厂。但是此时a对象中的b还是null,a对象还是半成品对象。

回到刚才创建b对象的那一步,创建b对象的目的就是为了给a对象进行属性填充,现在有了成品对象b且已经放进了一级缓存,这个时候就可以继续用对象b给对象a进行属性填充了。这个时候a也是成品对象了,其中的b对象不再是null

最后a对象完成了属性填充,重复上面b对象的那一步,把对象a放进一级缓存,并且从三级缓存中删除a对象工厂,并且从二级缓存中删除a对象

b、三级缓存debug流程的总结
1-第一阶段
通过反射获取构造器并实例化对象a,instanceWrapper = createBeanInstance(beanName, mbd, args);
当 a 创建实例后,填充属性之前 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean))
将【a对象工厂】往singletonFactories【三级缓存】中添加
2-第二阶段
完成对象a的实例化后,接着开始对象a的属性填充,遍历属性并且通过解析判断发现依赖对象b,先从容器的三个缓存中依次查找对象b,没有找到,于是开始调用getBean方法创建对象b
3-第三阶段
通过反射获取构造器并实例化对象b,instanceWrapper = createBeanInstance(beanName, mbd, args);
当 b 创建实例后,填充属性之前 addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean))
也将【b对象工厂】往singletonFactories【三级缓存】中添加,此时三级缓存里有【a对象工厂】和【b对象工厂】
4-第四阶段
完成对象b的实例化后,接着开始对象b的属性填充,遍历属性并且通过解析判断发现依赖对象a,先从容器的三个缓存中依次查找对象a,在三级缓存里找到了对象a的对象工厂(lambda表达式),于是开始通过getObject方法调用前面传到value里的lambda表达式来创建一个单例对象a,完成对象a创建后把对象a放进二级缓存,并且删除三级缓存里的a对象工厂
此时三级缓存里有【b对象工厂】,二级缓存里有【半成品对象A{b=null}】
删除了三级缓存里的【a对象工厂】
5-第五阶段
取到半成品对象a后继续到对象b的属性填充,b对象完成属性填充和初始化,B{a=null}变成B{a=@***},把对象b放进一级缓存,并且删除二级缓存和三级缓存中的b对象
此时三级缓存里啥也没有了,二级缓存里有【半成品对象A{b=null}】,一级缓存里有【成品对象B{a=@***}】
删除了三级缓存里的【b对象工厂】
6-第六阶段
取到成品对象b后继续到对象a的属性填充,a对象完成属性填充和初始化,A{b=null}变成A{b=@***},把对象a放进一级缓存,并且删除二级缓存和三级缓存中的a对象
此时三级缓存里啥也没有了,二级缓存里啥也没有了,一级缓存里有【成品对象B{a=@***}】 和【成品对象A{b=@—}】
删除了二级缓存里的【半成品对象A{b=null}】

8、三级缓存的重要问题
a、如果只有一级缓存
(1)实例化A对象。
(2)填充A的属性阶段时需要去填充B对象,而此时B对象还没有创建,所以这里为了完成A的填充就必须要先去创建B对象;
(3)实例化B对象。
(4)执行到B对象的填充属性阶段,又会需要去获取A对象,而此时Map【一级缓存】中没有A,因为A还没有创建完成,导致又需要去创建A对象。这样,就会循环往复,一直创建下去,只到堆栈溢出。
为什么不能在实例化A之后就放入Map?因为此时A尚未创建完整,所有属性都是默认值,并不是一个完整的对象,在执行业务时可能会抛出未知的异常。所以必须要在A创建完成之后才能放入Map【一级缓存】
b、如果只有二级缓存
此时我们引入二级缓存用另外一个Map2 {k:name; v:earlybean} 来存储尚未已经开始创建但是尚未完整创建的对象。
(1)实例化A对象之后,将A对象放入Map2【二级缓存】中>。
(2)在填充A的属性阶段需要去填充B对象,而此时B对象还没有创建,所以这里为了完成A的填充就必须要先去创建B对象。
(3)创建B对象的过程中,实例化B对象之后,将B对象放入Map2【二级缓存】中。
(4)执行到B对象填充属性阶段,又会需要去获取A对象,而此时Map【一级缓存】中没有A,因为A还没有创建完成,但是我们继续从Map2【二级缓存】中拿到尚未创建完毕的A的引用赋值给a字段。这样B对象其实就已经创建完整了,尽管B.a对象是一个还未创建完成的对象。
(5)此时将B放入Map【一级缓存】并且从Map2【二级缓存】中删除。
(6)这时候B创建完成,A继续执行b的属性填充可以拿到B对象,这样A也完成了创建。
(7)此时将A对象放入Map【一级缓存】并从Map2【二级缓存】中删除。
c、二级缓存已然解决了循环依赖问题,为什么还需要三级缓存?
三级缓存为什么要使用工厂而不是直接使用引用?换而言之,为什么需要这个三级缓存,直接通过二级缓存暴露一个引用不行吗?
这个工厂的目的在于延迟对实例化阶段生成的对象的代理,只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建对象
即使没有循环依赖,也会将其添加到三级缓存中,而且是不得不添加到三级缓存中,因为到目前为止Spring也不能确定这个Bean有没有跟别的Bean出现循环依赖。
假设我们在这里直接使用二级缓存的话,那么意味着所有的Bean在这一步都要完成AOP代理。这样做有必要吗?
不仅没有必要,而且违背了Spring在结合AOP跟Bean的生命周期的设计!Spring结合AOP跟Bean的生命周期本身就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。
d、Spring是如何解决的循环依赖?
Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!
9、Spring解决循环依赖的详细流程
(1)描述流程
- 1、什么是循环依赖?
- 2、什么情况下循环依赖可以被处理?
- 3、spring是如何解决的循环依赖
(2)错误说法
- 1、只有在setter方式注入的情况下,循环依赖才能解决(错)
- 2、三级缓存的目的是为了提高效率(错)
(3)什么情况下循环依赖可以被处理?
一、Spring解决循环依赖是有前置条件
- 1、出现循环依赖的Bean必须要是单例
- 2、依赖注入的方式不能全是构造器注入的方式(很多博客上说,只能解决setter方法的循环依赖,这是错误的)
中注入B的方式是通过构造器,B中注入A的方式也是通过构造器,这个时候循环依赖是无法被解决,如果你的项目中有两个这样相互依赖的Bean,在启动时就会报出以下错误:


10、Spring是如何解决的循环依赖?
一、案例demo

二、Spring在创建Bean的时候默认是按照自然排序来进行创建的,所以第一步Spring会去创建A
Spring在创建Bean的过程中分为三步:
-
1、实例化,简单理解就是new了一个对象。对应方法:AbstractAutowireCapableBeanFactory中的createBeanInstance方法
-
2、属性注入,为实例化中new出来的对象填充属性。对应方法:AbstractAutowireCapableBeanFactory的populateBean方法
-
3、初始化,执行aware接口中的方法,初始化方法,完成AOP代理。对应方法:AbstractAutowireCapableBeanFactory的initializeBean
三、循环依赖处理过程的关键方法步骤流程图

创建A的过程实际上就是调用getBean方法,这个方法有两层含义:
-
1、创建一个新的Bean
-
2、从缓存中获取到已经被创建的对象
此时步骤中的是第一层含义,因为这个时候缓存中还没有A
【1】调用getSingleton(beanName)
首先调用getSingleton(a)方法,这个方法又会调用getSingleton(beanName, true),在上图中我省略了这一步

getSingleton(beanName, true)这个方法实际上就是到缓存中尝试去获取Bean,整个缓存分为三级:
-
a、singletonObjects,一级缓存,存储的是所有创建好了的单例Bean
-
b、earlySingletonObjects,完成实例化,但是还未进行属性注入及初始化的对象
-
c、singletonFactories,提前暴露的一个单例工厂,二级缓存中存储的就是从这个工厂中获取到的对象
因为A是第一次被创建,所以不管哪个缓存中必然都是没有的,因此会进入getSingleton的另外一个重载方法getSingleton(beanName, singletonFactory)
【2】调用getSingleton(beanName, singletonFactory)
这个方法就是用来创建Bean的,其源码如下:

上面的代码我们主要抓住一点,通过createBean方法返回的Bean最终被放到了一级缓存,也就是单例池中。
那么到这里我们可以得出一个结论:一级缓存中存储的是已经完全创建好了的单例Bean
【3】调用addSingletonFactory方法

在完成Bean的实例化后,属性注入之前Spring将Bean包装成一个工厂添加进了三级缓存中,对应源码如下:

这里只是添加了一个工厂,通过这个工厂(ObjectFactory)的getObject方法可以得到一个对象,而这个对象实际上就是通过getEarlyBeanReference这个方法创建的。那么,什么时候会去调用这个工厂的getObject方法呢?这个时候就要到创建B的流程了,目前只是把lambda表达式当做参数传递,并没有实际调用!
当A完成了实例化并添加进了三级缓存后,就要开始为A进行属性注入了,在注入时发现A依赖了B,那么这个时候Spring又会去getBean(b),然后反射调用setter方法完成属性注入

因为B需要注入A,所以在创建B的时候,又会去调用getBean(a),这个时候就又回到之前的流程了,但是不同的是,之前的getBean是为了创建Bean,而此时再调用getBean不是为了创建了,而是要从缓存中获取,因为之前A在实例化后已经将其放入了三级缓存singletonFactories中,所以此时getBean(a)的流程就是这样子了

从这里我们可以看出,注入到B中的A是通过getEarlyBeanReference方法提前暴露出去的一个对象,还不是一个完整的Bean,那么getEarlyBeanReference到底干了啥了,我们看下它的源码

它实际上就是调用了后置处理器的getEarlyBeanReference,而真正实现了这个方法的后置处理器只有一个,就是通过@EnableAspectJAutoProxy注解导入的AnnotationAwareAspectJAutoProxyCreator。也就是说如果在不考虑AOP的情况下,
的代码等价于:

也就是说这个工厂啥都没干,直接将实例化阶段创建的对象返回了!所以说在不考虑AOP的情况下三级缓存有用嘛?没什么用,我直接将这个对象放到二级缓存中不是一点问题都没有吗?在下文结合AOP分析循环依赖的时候你就能体会到三级缓存的作用!
这个时候我们需要将整个创建A这个Bean的流程走完,如下图:

从上图中我们可以看到,虽然在创建B时会提前给B注入了一个还未初始化的A对象,但是在创建A的流程中一直使用的是注入到B中的A对象的引用,之后会根据这个引用对A进行初始化,所以这是没有问题的。
【4】结合了AOP的循环依赖
之前我们已经说过了,在普通的循环依赖的情况下,三级缓存没有任何作用。三级缓存实际上跟Spring中的AOP相关,我们再来看一看getEarlyBeanReference的代码:

如果在开启AOP的情况下,那么就是调用到AnnotationAwareAspectJAutoProxyCreator的getEarlyBeanReference方法,对应的源码如下:

回到上面的例子,我们对A进行了AOP代理的话,那么此时getEarlyBeanReference将返回一个代理后的对象,而不是实例化阶段创建的对象,这样就意味着B中注入的A将是一个代理对象而不是A的实例化阶段创建后的对象。

10、Spring循环依赖产生的疑问
疑问一:在给B注入的时候为什么要注入一个代理对象?
答:当我们对A进行了AOP代理时,说明我们希望从容器中获取到的就是A代理后的对象而不是A本身,因此把A当作依赖进行注入时也要注入它的代理对象
疑问二:明明初始化的时候是A对象,那么Spring是在哪里将代理对象放入到容器中的呢?

在完成初始化后,Spring又调用了一次getSingleton方法,这一次传入的参数又不一样了,false可以理解为禁用三级缓存,前面图中已经提到过了,在为B中注入A时已经将三级缓存中的工厂取出,并从工厂中获取到了一个对象放入到了二级缓存中,所以这里的这个getSingleton方法做的事件就是从二级缓存中获取到这个代理后的A对象。exposedObject == bean可以认为是必定成立的
疑问三:初始化的时候是对A对象本身进行初始化,而容器中以及注入到B中的都是代理对象,这样不会有问题吗?
答:不会,这是因为不管是cglib代理还是jdk动态代理生成的代理类,内部都持有一个目标类的引用,当调用代理对象的方法时,实际会去调用目标对象的方法,A完成初始化相当于代理对象自身也完成了初始化
疑问四:三级缓存为什么要使用工厂而不是直接使用引用?换而言之,为什么需要这个三级缓存,直接通过二级缓存暴露一个引用不行吗?
答:这个工厂的目的在于延迟对实例化阶段生成的对象的代理,只有真正发生循环依赖的时候,才去提前生成代理对象,否则只会创建一个工厂并将其放入到三级缓存中,但是不会去通过这个工厂去真正创建
疑问我们思考一种简单的情况,就以单独创建A为例,假设AB之间现在没有依赖关系,但是A被代理了,这个时候当A完成实例化后还是会进入下面这段代码:

看到了吧,即使没有循环依赖,也会将其添加到三级缓存中,而且是不得不添加到三级缓存中,因为到目前为止Spring也不能确定这个Bean有没有跟别的Bean出现循环依赖。
假设我们在这里直接使用二级缓存的话,那么意味着所有的Bean在这一步都要完成AOP代理。这样做有必要吗?
不仅没有必要,而且违背了Spring在结合AOP跟Bean的生命周期的设计!Spring结合AOP跟Bean的生命周期本身就是通过AnnotationAwareAspectJAutoProxyCreator这个后置处理器来完成的,在这个后置处理的postProcessAfterInitialization方法中对初始化后的Bean完成AOP代理。如果出现了循环依赖,那没有办法,只有给Bean先创建代理,但是没有出现循环依赖的情况下,设计之初就是让Bean在生命周期的最后一步完成代理而不是在实例化后就立马完成代理。

11、三级缓存真的提高了效率了吗?
分为两点讨论:
(1)没有进行AOP的Bean间的循环依赖,从上文分析可以看出,这种情况下三级缓存根本没用!所以不会存在什么提高了效率的说法
(2)进行了AOP的Bean间的循环依赖
就以我们上的A、B为例,其中A被AOP代理,我们先分析下使用了三级缓存的情况下,A、B的创建流程

假设不使用三级缓存,直接在二级缓存中

上面两个流程的唯一区别在于为A对象创建代理的时机不同,在使用了三级缓存的情况下为A创建代理的时机是在B中需要注入A的时候,而不使用三级缓存的话在A实例化后就需要马上为A创建代理然后放入到二级缓存中去。对于整个A、B的创建过程而言,消耗的时间是一样的;综上,不管是哪种情况,三级缓存提高了效率这种说法都是错误的!
12、总结,问:”Spring是如何解决的循环依赖?“
答:Spring通过三级缓存解决了循环依赖,其中一级缓存为单例池(singletonObjects),二级缓存为早期曝光对象earlySingletonObjects,三级缓存为早期曝光对象工厂(singletonFactories)。当A、B两个类发生循环引用时,在A完成实例化后,就使用实例化后的对象去创建一个对象工厂,并添加到三级缓存中,如果A被AOP代理,那么通过这个工厂获取到的就是A代理后的对象,如果A没有被AOP代理,那么这个工厂获取到的就是A实例化的对象。当A进行属性注入时,会去创建B,同时B又依赖了A,所以创建B的同时又会去调用getBean(a)来获取需要的依赖,此时的getBean(a)会从缓存中获取,第一步,先获取到三级缓存中的工厂;第二步,调用对象工工厂的getObject方法来获取到对应的对象,得到这个对象后将其注入到B中。紧接着B会走完它的生命周期流程,包括初始化、后置处理器等。当B创建完后,会将B再注入到A中,此时A再完成它的整个生命周期。至此,循环依赖结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号