MySQL入门笔记(一)
一、数据类型
1. 整型

2. 浮点型

3. 字符型
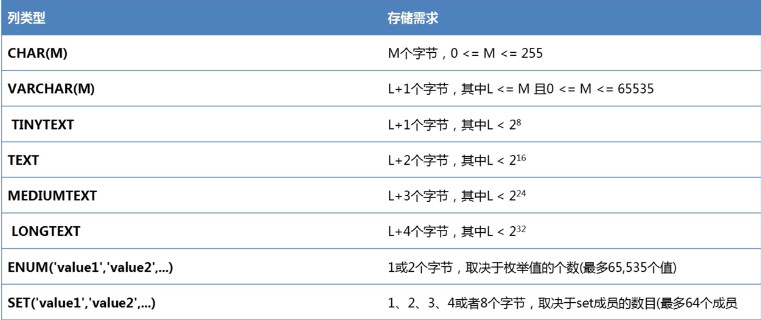
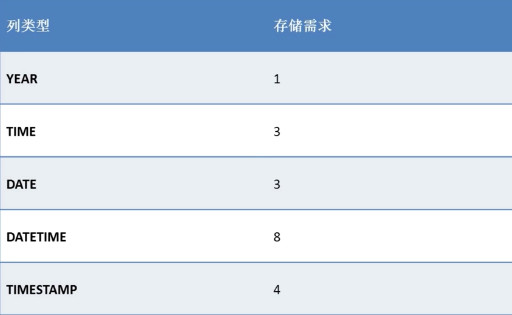
4. 日期时间型
二、数据库操作
1. 创建库
CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_name [DEFAULT] CHARACTER SET [=] charset_name;
上述代码中DATABASE和SCHEMA完全相同,可任选一个(花括号内的参数为任选其一);
添加IF NOT EXISTS的作用则是,若新建数据库的名称与已有数据库名称冲突,则产生一个警告,若无该关键字,则会产生错误(中括号内的参数为可省略参数);
db_name为数据库名称;
[DEFAULT] CHARACTER SET [=] 为指定数据库的字符编码,可不指定而使用默认的字符编码。
例1:创建一个名为test的数据库
CREATE DATABASE test;
例2:创建一个名为test2的数据库并指定字符编码为GBK
CREATE DATABASE test2 CHARACTER SET gbk;
有一点需要注意的是,这一步骤仅仅是创建了数据库,在后面需要创建数据表时,需要打开指定数据库:
USE db_name;
2. 删除库
DROP {DATABASE | SCHEMA} [IF EXISTS] db_name;
参数与创建数据库基本一致。
3. 修改库
ALTER {DATABASE | SCHEMA} [db_name] [DEFAULT] CHARACTER SET [=] charset_name;
可修改的仅为字符编码方式。若不指定数据库名称,则修改当前选中的数据库。例:将名为test的数据库的字符编码方式改为utf-8
ALTER DATABASE test CHARACTER SET utf8;
4. 查看库
4.1 查看当前所有库
SHOW DATABASES;
4.2 查看指定数据库的创建信息
SHOW CREATE DATABASE db_name;
4.3 查看当前打开的数据库
SELECT DATABASE();
三、数据表操作
1. 创建表(各种约束)
1.1 定义
CREATE TABLE [IF NOT EXISTS] table_name(
column_name data_type [constraint],
···
);
constraint为约束,可选参数。(详情见1.2 约束)例:创建一个名称为t1,包含id、username以及age三个字段的数据表
CREATE TABLE t1(
id SMALLINT UNSIGNED,
username VARCHAR(20),
age TINYINT UNSIGNED
);
1.2 约束
约束,顾名思义,即对某些列或整个表产生约束、限制,增加输入规则,例如某些列不允许为空、某些列不允许重复等。按照功能划分,有以下几种:
(1)主键约束
PRIMARY KEY
主键约束用于唯一地标识表中的每一条记录,通俗地说,就是加了主键约束的列或者表,不允许存在重复的记录。添加了主键约束的列自动为NOT NULL。
例:某表中存在一列用于存储用户名,用主键约束限制其不能存在重复的用户名
username VARCHAR(20) PRIMARY KEY
自动编号:
AUTO_INCREMENT
顾名思义,即自动编号,序号从1开始。需要注意,AUTO_INCREMENT必须与主键约束配套使用。
例:
id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT
(2)唯一约束
UNIQUE KEY
唯一约束与主键约束作用相同,也用于标识记录的唯一性,不同之处在于,同一个数据表中可存在多个唯一约束,但主键约束只能存在一个。此外,主键约束不允许为空,唯一约束则允许存在唯一的NULL值。
(3)非空约束
NOT NULL
非空约束的用于禁止用户在非空约束的列中输入NULL。
(4)默认约束
DEFAULT value
用于设置字段的默认值,当用户未输入当前字段时,将自动填入默认值。
例:定义一个sex字段,默认情况下为3
sex ENUM('1', '2', '3') DEFAULT 3
(5)外键约束
FOREIGN KEY(column_name1) REFERENCES table_name(column_name2)
外键约束一般用于两个存在某种关系的字段,实现一对一或一对多的关系。
例1:创建一个父表location和一个子表users,通过外键约束关联location中的id与users中的lid
CREATE TABLE location(
id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20) NOT NULL
);
CREATE TABLE users(
id SMALLINT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(20) NOT NULL,
lid SMALLINT UNSIGNED,
FOREIGN KEY(lid) REFERENCES location(id)
);
使用外键约束需要注意一些问题,第一,父表和子表禁止使用临时表;第二,父表和子表必须使用相同的存储引擎,且必须为InnoDB;第三,外键列与参照列必须具有相似的数据类型,其中若为数字(INT、FLOAT等),则其类型长度和是否有符号位都必须完全相同,若为字符,则可为不同长度;第四,向子表插入记录时,需保证父表不为空。
外键约束的参照操作:
指定当删除或更新父表中的记录时,对子表进行的操作。使用方式为在外键约束末尾加上ON DELETE,然后加上相应操作的关键字。操作分别有以下几种:
1)CASCADE:当删除或更新父表中的记录时,自动更新或删除子表中相应的记录。
2)SET NULL:当删除或更新父表中的记录时,将子表中相应的记录的外键列设置为NULL。注意,需保证改外键列没有指定为NOT NULL。
3)RESTRICT:当父表中的记录被子表中的记录所参照时,这些被参照的记录不允许进行删除或更新操作,而未被参照的记录则可自由删除或更新。
例:
父表:
| id(参照列) | name |
|---|---|
| 1 | A |
| 2 | B |
| 3 | C |
子表:
| name | aid(外键列) |
|---|---|
| a | 1 |
| b | 1 |
| c | 2 |
在上面这种情况中,若子表的外键约束加了RESTRICT关键字,则由于父表中id为1和2的两条记录被参照,不能被删除或更新;而id为3的记录未被参照,因此可以删除或更新。
4)NO ACTION:标准SQL中的关键字,在MySQL中等同于RESTRICT。
2. 删除表
DROP TABLE tbl_name;
3. 更改表名称
3.1 更改单个数据表名称
ALTER TABLE tbl_name RENAME [TO | AS] new_tbl_name;
3.2 更改多个数据表名称
RENAME TABLE tbl_name TO new_tbl_name [, tbl_name2 TO new_tbl_name2] ……
4. 查看表
4.1 查看数据库内存在的表
SHOW TABLES [FROM db_name];
4.2 查看表的创建信息(存储引擎、编码方式等)
SHOW CREATE TABLE table_name;
4.3 查看表结构
SHOW COLUMNS FROM table_name;
5. 列操作
5.1 添加列
(1)添加单列
ALTER TABLE tbl_name ADD [COLUMN] col_name column_definition [FIRST | AFTER col_name2];
关键字COLUMN可不加;FIRST的作用是将增加列置于指定表的最前面,AFTER col_name2则是将增加列置于col_name2的下一列。
例:存在一表test,含有id字段,现在id字段的下一列增加一个name字段
ALTER TABLE test ADD name VARCHAR(20) NOT NULL AFTER id;
(2)添加多列
ALTER TABLE tbl_name ADD [COLUMN] (col_name column_definition, ……)
添加多列时多个字段写进小括号内,以逗号相隔,添加多列与添加单列的不同之处在于添加多列不可以指定添加位置,而是默认添加到数据表的最后。
5.2 删除列
ALTER TABLE tbl_name DROP [COLUMN] col_name;
如需同时删除多列,则调用多次DROP。
例:存在表test,含有password、sex字段,现同时删除这两个字段
ALTER TABLE test DROP password, DROP sex;
5.3 修改列定义
(1)MODIFY
ALTER TABLE tbl_name MODIFY [COLUMN] col_name column_definition [FIRST | AFTER col_name];
MODIFY可用于修改列定义以及列位置。例:存在以下数据表t2,
+-------+----------------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+----------------------+------+-----+---------+-------+
| id | smallint(5) unsigned | NO | | NULL | |
| name | varchar(20) | YES | MUL | NULL | |
| age | tinyint(4) | YES | UNI | NULL | |
| sex | enum('1','2','3') | YES | | NULL | |
| aid | smallint(5) unsigned | YES | MUL | NULL | |
+-------+----------------------+------+-----+---------+-------+
现将id字段移至name字段下一列,操作为:
ALTER TABLE t2 MODIFY id SMALLINT UNSIGNED NOT NULL AFTER name;
再将id字段的数据类型改为INT,操作为:
ALTER TABLE t2 MODIFY id INT UNSIGNED NOT NULL;
也可以将两步操作同时进行:
ALTER TABLE t2 MODIFY id INT UNSIGNED NOT NULL AFTER name;
(2)CHANGE
ALTER TABLE tbl_name CHANE [COLUMN] old_col_name new_col_name column_definition [FIRST | AFTER col_name];
CHANGE与MODIFY基本一致,不同之处在于CHANGE可修改列名称而MODIFY不可以。
5.4 添加约束
考虑到入门级别的读者大多未学习索引,因此对约束的操作中涉及到索引的部分全部去除,仅介绍最基本的用法,需要研究完整功能的读者可自行查找相关资料。
(1)主键约束
ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] PRIMARY KEY (col_name)
symbol为约束的标记或别名,自行定义。例:为表test中的id字段添加主键约束并起名为PK_test_id
ALTER TABLE test ADD CONSTRAINT PK_test_id PRIMARY KEY (id);
(2)唯一约束
ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] UNIQUE (col_name, ……);
添加唯一约束的方法与主键约束基本一致,不同之处在于唯一约束可同时添加多个,而主键约束只能有一个。
(3)默认约束
ALTER TABLE tbl_name ALTER [COLUMN] col_name SET DEFAULT literal;
literal为默认值。例:为表test中的age字段设置默认值为18
ALTER TABLE test ALTER age SET DEFAULT 15;
(4)外键约束
ALTER TABLE tbl_name ADD [CONSTRAINT [symbol]] FOREIGN KEY (col_name) reference_definition;
例:为表test中的aid字段添加外键约束,参照列为表test2中的id字段
ALTER TABLE test ADD FOREIGN KEY(aid) REFERENCES test2(id);
5.5 删除约束
(1)主键约束
ALTER TABLE tbl_name DROP PRIMARY KEY;
(2)唯一约束
ALTER TABLE tbl_name DROP {INDEX | KEY} index_name;
花括号内的INDEX和KEY任选其一。注意,在这里必须使用要删除的约束所在字段的索引而不是字段名称,查看索引可使用命令SHOW INDEXES FROM tbl_name\G(\G是指定结果以网格形式输出,可不加),输出结果中的Key_name即为索引名称。
*************************** 1. row ***************************
Table: t2
Non_unique: 0
Key_name: name
Seq_in_index: 1
Column_name: name
Collation: A
Cardinality: 0
Sub_part: NULL
Packed: NULL
Null: YES
Index_type: BTREE
Comment:
Index_comment:
例如上面这一字段的索引名称即为name。
(3)默认约束
ALTER TABLE tbl_name ALTER [COLUMN] col_name DROP DEFAULT;
(4)外键约束
ALTER TABLE tbl_name DROP FOREIGN KEY fk_symbol;
删除外键约束不需要指定列,但必须输入外键的标记fk_symbol,查看外键标记可使用命令SHOW CREATE TABLE tbl_name,即查看数据表的创建信息。
| t2 | CREATE TABLE `t2` (
`id` smallint(5) unsigned NOT NULL,
`name` varchar(20) DEFAULT NULL,
`age` tinyint(4) DEFAULT NULL,
`sex` enum('1','2','3'),
`aid` smallint(5) unsigned DEFAULT NULL,
UNIQUE KEY `name` (`name`,`age`),
UNIQUE KEY `age` (`age`),
UNIQUE KEY `age_2` (`age`),
KEY `aid` (`aid`),
CONSTRAINT `t2_ibfk_1` FOREIGN KEY (`aid`) REFERENCES `t1` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
例如,上面这一数据表t2中,aid为外键列,因而找到相应的外键标记,为t2_ibfk_1,所以删除这一外键约束的操作为:
ALTER TABLE t2 DROP FOREIGN KEY t2_ibfk_1;
四、记录操作
1. 添加记录
1.1 INSERT
INSERT [INTO] tbl_name [(col_name,···)] {VALUES | VALUE} ({expr | DEFAULT}, ...), (...), ...;
添加记录可不指定列,这种情况下必须依次输入当前记录所有字段的数据;若需要仅输入其中某些字段的值,则在表名后指定相应的列名称;{expr | DEFAULT}的意思为,可以直接输入相应的值,也可以输入表达式;此外,使用INSERT语句插入记录可同时插入多条记录。
例:向一个名为test,含有id、username、age三个字段的表中插入一条记录:
INSERT test VALUES(DEFAULT, 'Kity', 16+2);
若仅输入username、age:
INSERT test(username, age) VALUES('Kity', 18);
若同时插入两条记录:
INSERT test(username, age) VALUES('Kity', 18), ('Smith', 26);
1.2 INSERT-SET
INSERT [INTO] tbl_name SET col_name = {expr | DEFAULT}, ...;
这种方式与第一种方式的区别在于,这种方法能用于子查询,同时这种方法每次只能输入一条记录。
1.3 INSERT-SELECT
INSERT [INTO] tbl_name [(col_name, ...)] SELECT ...
这种方式的作用是将SELECT(若对SELECT的语法不明白,可先看后面的4.查询记录)的查询结果插入到指定数据表中(实际上运用了子查询,不明白的读者可查看MySQL入门笔记(二)),需要注意,查询的字段数量必须与插入的字段数量相匹配,否则就会出现错误。
例:将表t1中age大于30的记录的name、age字段插入到表t2中:
INSERT t2(username, age) SELECT name, age FROM t1 WHERE age > 30;
2. 删除记录
DELETE FROM tbl_name [WHERE where_condition]
WHERE关键字为对更新记录的条件(相当于Java中的if),若不加,则删除全部记录。
例:删除表test中id为偶数的记录:
DELETE FROM test WHERE id % 2 = 0;
3. 更新记录(单表更新)
UPDATE [LOW_PRIORITY] [IGNORE] tbl_references SET col_name1 = {expr1 | DEFAULT} [, col_name2 = {expr2 | DEFAULT}] ... [WHERE where_condition];
tbl_reference为表格名称。例1:更新表t1中的age字段,使其全部增加5:
UPDATE t1 SET age = age + 5;
例2:使表t2中的age字段全部为0,sex字段(非枚举类型)全部取相反数:
UPDATE t2 SET age = 0, sex = -sex;
例3:使表t3中id为2的一项name为John:
UPDATE t3 SET name = 'John' WHERE id = 2;
4. 查询记录
SELECT select_expr [, select_expr2 ...]
[
FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | position} [ASC | DESC]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position} [ASC | DESC], ...]
[LIMIT {[offset,] row_count | row_count OFFSET offset}]
];
4.1 SELECT select_expr [, select_expr2 ...](最简单也非常常用的形式)
例:查看数据库版本:
SELECT VERSION();
4.2 FROM table_references
查询数据表中的指定列的记录。例:查询表test中的全部字段的记录:
SELECT * FROM test;
或仅查询其中的id、name字段(顺序可根据需要自由调整):
SELECT id, name FROM test;
4.3 AS
在查询表时,有时(例如单表模拟多表操作)会需要为字段赋予别名,这时就用到AS。
例:查询表test中的id、username字段,并给username赋予别名name:
SELECT id, username AS name FROM test;
4.4 GROUP BY {col_name | position} [ASC | DESC]
GROUP BY用于对查询结果进行排序。可以指定进行分组的列名称,也可以指定位置position,位置即SELECT语句查询的查询顺序,例如SELECT id, username FROM test;,在这里若输入位置为2,则对username字段进行分组;此外,还可以指定分组是的排列顺序,ASC为升序,DESC为降序。
例:查询表test中的name、age字段,并根据age字段分组从大到小排列:
SELECT name, age FROM test GROUP BY age DESC;
4.5 [HAVING where_condition]
HAVING用于设置分组条件,即限制进行分组的记录范围。需要注意的是,若条件中用到表中的某些字段进行判断,那么所使用的字段必须是在查询列表中的。
例:查询表test中的name、age字段,并将age>30的记录进行分组:
SELECT name, age FROM test GROUP BY age HAVING age > 30;
4.6 ORDER BY {col_name | expr | position} [ASC | DESC], ...
ORDER BY用于对查询结果进行排序。若添加个条件,则在第一条件相同的情况下,比较第二条件,以此类推。
例:查询表test中的所有字段,并按照age升序排列,若age相同,则按照id降序排列:
SELECT * FROM test ORDER BY age, id DESC;
4.7 LIMIT
LIMIT用于限制返回的查询结果的数量。offset为查询的起点,要注意,同大部分语言一样,MySQL中第一条记录为0;row_count则为查询结果的数量。此外使用LIMIT语句进行限制时,其遵循的顺序是查询结果的顺序,而不是数据表存储的顺序。
例:查询表test中的所有字段,显示第3到第5条记录:
SELECT * FROM test LIMIT 2, 3;
本文作学习交流用,如有错误,欢迎指正!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号