tesseract ocr训练 pt验证码
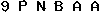

识别率有问题A大概率识别为n,因此需要训练,这里讲一下 如何训练
参考
java代码里边直接使用tess4j,是对tesseract的封装,但是如果要训练,还是需要在进行安装tesseract-ocr的
下载地址参考另一篇
然后还需要 下载jTessBoxEditorhttps://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
多搜集几张图片,进行二值化去噪点和裁切处理

双击运行

首先打开图片
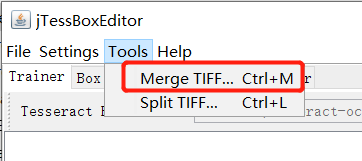
全选图片,应该可以自动拼接为一个大的tif,不过我测试发现,有问题,并不能拼
而且,最后一步,生成box的时候,几乎所有的字体都无法识别,还是需要手动添加box
所以还是手动处理一下
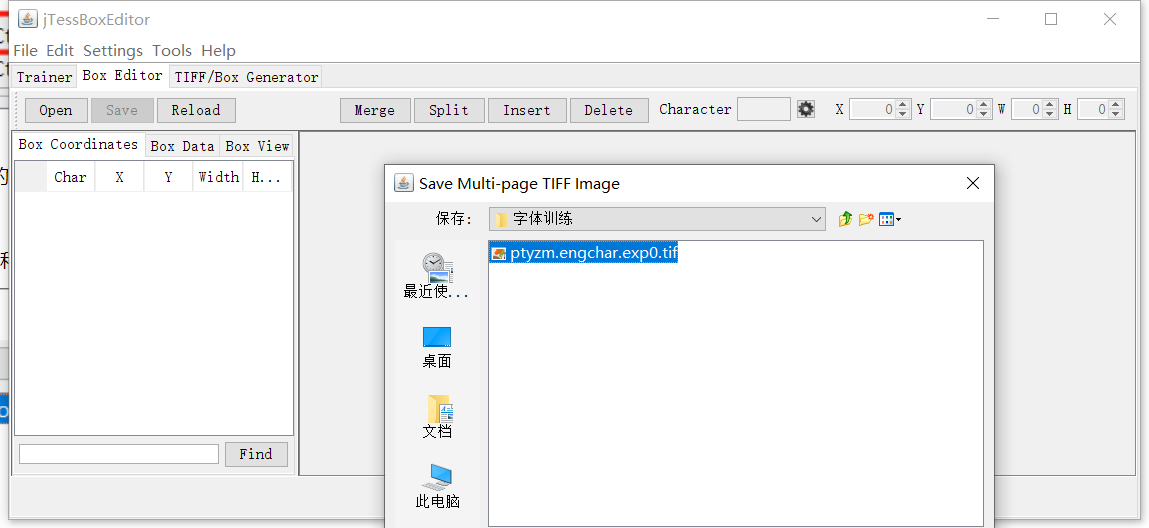
然后生成tif文件,命名格式包含语言类型和干吗用的字体就行了,比如我这个是英文字体,pt验证码
4、使用tesseract生成.box文件:
在当前文件夹运行cmd(定位到文件夹,然后在地址栏直接输入cmd,回车即可)
运行命令
tesseract ptyzm.engchar.exp0.tif ptyzm.engchar.exp0 -l eng -psm 7 batch.nochop makebox

行完之后会生成ptyzm.engchar.exp0.box文件。
可以看到生成了box文件

5、使用jTessBoxEditor矫正.box文件的错误:
会自动关联box文件
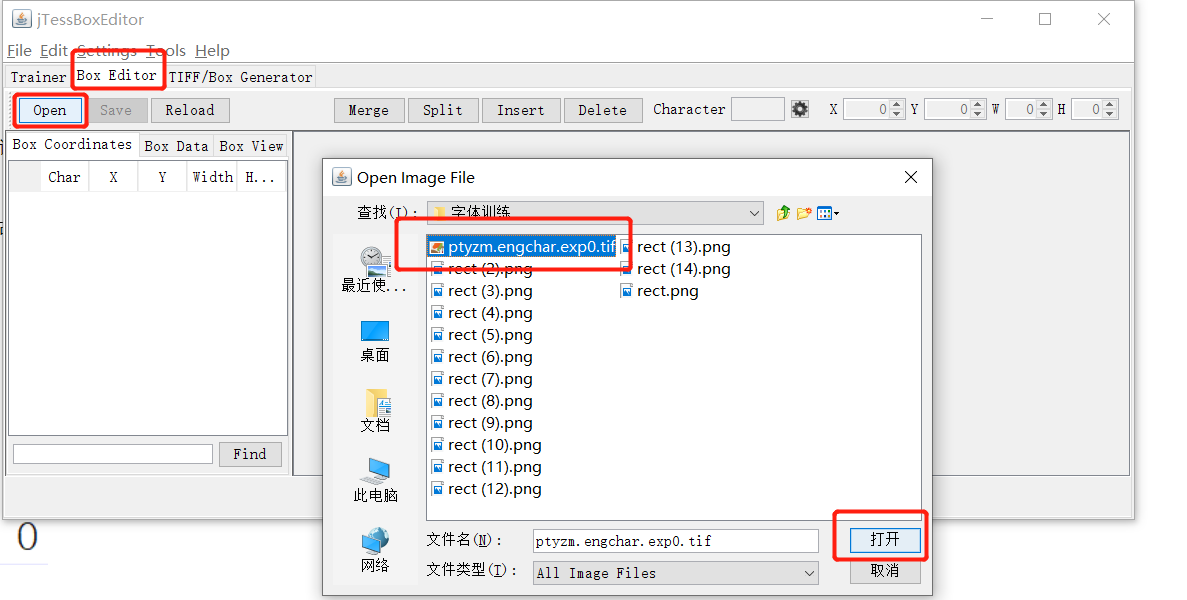
因为图像分辨率问题,识别效果不是很好
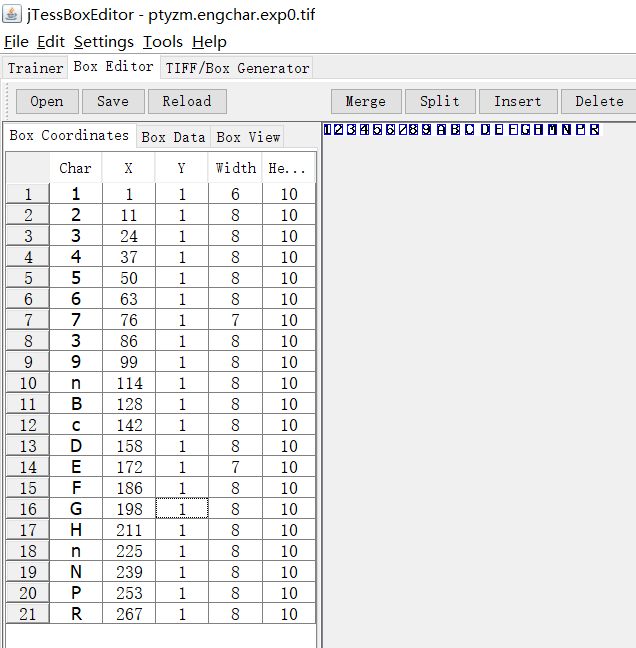
识别错误的,修改之后 点击save
6、生成font_properties文件:(该文件没有后缀名)
(1)执行命令,执行完之后,会在当前目录生成font_properties文件
然后执行命令,0表示字体test的粗体、倾斜等共计5个属性。也可以直接手动创建这个文件
echo engchar 0 0 0 0 0 >font_properties
执行完之后,会在当前目录生成font_properties文件
7、使用tesseract生成.tr训练文件:
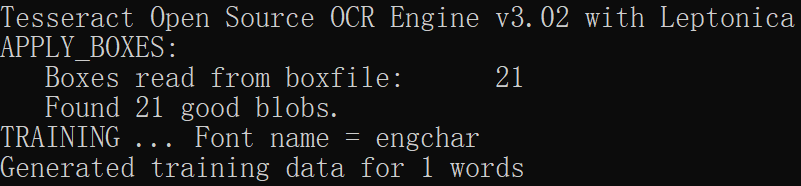
执行下面命令,执行完之后,会在当前目录生成ptyzm.engchart.exp0.tr文件。
tesseract ptyzm.engchar.exp0.tif ptyzm.engchar.exp0 nobatch box.train

8、生成字符集文件:
执行下面命令:执行完之后会在当前目录生成一个名为“unicharset”的文件。
unicharset_extractor ptyzm.engchar.exp0.box


9、生成shape文件:
执行下面命令,执行完之后,会生成 shapetable 和engchar.unicharset 两个文件。
shapeclustering -F font_properties -U unicharset -O engchar.unicharset ptyzm.engchar.exp0.tr

。
。
。

生成的文件


10、生成聚字符特征文件:
执行下面命令,会生成 inttemp、pffmtable、shapetable和zwp.unicharset四个文件。
mftraining -F font_properties -U unicharset -O ptyzm.engchar ptyzm.engchar.exp0.tr
11、生成字符正常化特征文件:
执行下面命令,会生成 normproto 文件。
cntraining ptyzm.engchar.exp0.tr


12、文件重命名:
重新命名inttemp、pffmtable、shapetable和normproto这四个文件的名字为[lang].xxx。
这里修改为zwp.inttemp、zwp.pffmtable、zwp.shapetable和zwp.normproto
执行下面命令:
rename normproto engchar.normproto
rename inttemp engchar.inttemp
rename pffmtable engchar.pffmtable
rename shapetable engchar.shapetable
13、合并训练文件:
执行下面命令,会生成zwp.traineddata文件。
combine_tessdata engchar.

生成了训练文件

改个名字,就可以用啦

还是刚才的图片


 浙公网安备 33010602011771号
浙公网安备 33010602011771号