

Intel HDSLB 高性能四层负载均衡器 — 快速入门和应用场景
2024-05-14 23:52 云物互联 阅读(799) 评论(0) 收藏 举报目录
前言与背景
在云计算、SDN、NFV 高速发展并普遍落地的今天,随着上云业务的用户数量越来越多、数据中心的规模越来越大,云计算规模成本效应越来越重要。因此,云计算的集约式系统架构逻辑就决定了网络的性能是一个永恒的话题。在云网络的技术体系中,对性能追求不仅是方方面面的,而且是极致严苛的。性能每提升一点,成本就降低一分,收益就提高一些,产品的竞争力就更上一层楼。
大致上,我们可以将云网络的性能追求划分为物理网络的带宽性能、虚拟网络的隧道转发性能、四层网络的负载均衡性能、应用层网络的 I/O 处理性能等几个方面。尤其是当下,随着数据中心和边缘设备的网络带宽需求越来越高,作为用户业务服务网络入口的负载均衡器的性能表现至关重要。而这正是本系列文章研究的主题 —— Intel HDSLB 一种基于软硬件融合加速技术实现的高性能四层负载均衡器。
在该系列文章中为了能够把 HDSLB 介绍清楚,笔者希望能够从 “感性认识、理性认识、深入剖析” 这 3 个层级逐步展开,计划逐一分享下列文章,敬请期待。:)
- 《Intel HDSLB 高性能四层负载均衡器 — 快速入门和应用场景》
- 《Intel HDSLB 高性能四层负载均衡器 — 基本原理和部署配置》
- 《Intel HDSLB 高性能四层负载均衡器 — 高级特性和代码剖析》
传统 LB 技术的局限性
在深入了解 HDSLB 之前,我们有必要先回顾一下传统 LB(负载均衡)的基础概念、类型、作用和原理。在一个现代化的 IT 系统中,LB 的作用是为了构建一个满足高可用、高并发、且具有高度可扩展性的后端服务器集群,本质是一种流量分发网络单元。
在长久以来的技术演进中,LB 技术始终关注以下几个方面的发展:
- LB 算法:如何让流量可以根据各种不同的应用场景 “智能按需” 的分配到后端服务器集群中?
- LB 高可用:LB 网元作为流量路径的中间节点,如何保证其自身的高可用性?主备机制还是多主机制?
- LB 反向代理:如何为 TCP、UDP、SSL、HTTP、FTP、ALG 等 L4-7 层多种类型的网络协议提供反向代理和协议处理能力?
- LB 高性能:如何支持更大的带宽、更低的延时、更高的 CPS、更多的后端服务器规模?
- LB 集群化:如何为自身提供更好的横向扩展能力?
- 等等。
NOTE:CPS(Connections-per-second)是负载均衡器的关键性能指标,它描述了负载均衡器每秒钟稳定处理 TCP 连接建立的能力。
在以往,我们常见的 LB 方案有以下几种,包括:
- 《LVS & Keepalived 实现 L4 高可用负载均衡器》
- 《HAProxy & Keepalived 实现 L4-7 高可用负载均衡器》
- 《Nginx & Keepalived 实现 L4-7 高可用反向代理服务器》
- 等等。
诚然,这些 LB 方案现如今依旧在用户业务层 LB 场景中被大量的应用。但相对的,它们在云基础设施层 LB 场景中则正在面临着性能瓶颈、可扩展性差、云化适应性低等等问题。
随着先进的异构计算和软硬件融合加速等技术的蓬勃发展,现在越来越多的新型网络项目正在围绕着 DPDK、DPVS、VPP、SmartNIC/DPU 等高性能数据面技术展开,开发出更适应于云计算等大规模系统平台的新一代负载均衡产品,本系列文章讨论的 Intel HDSLB 正是其中之一。
HDSLB 的特点和优势
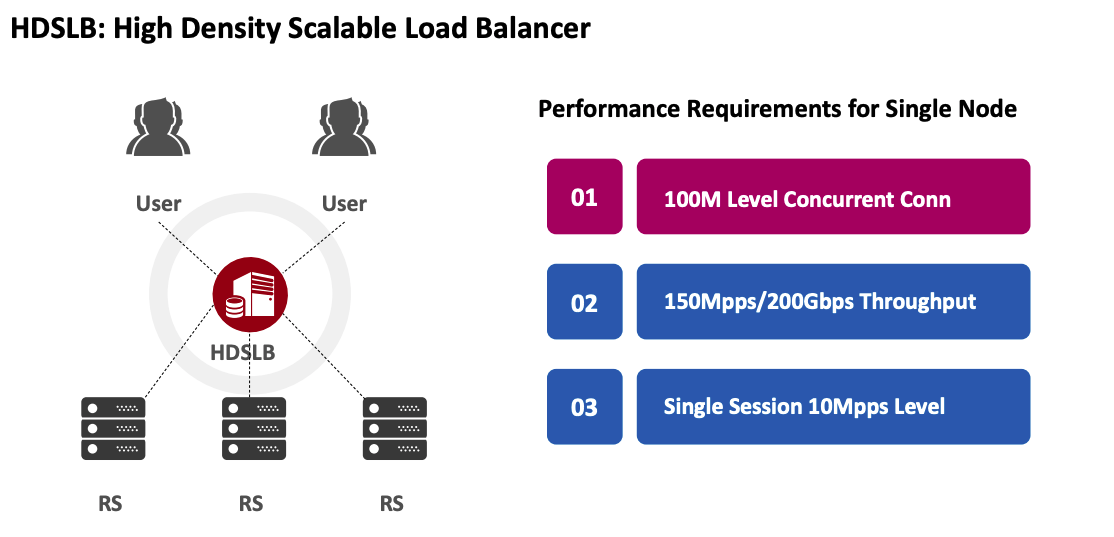
HDSLB(High Density Scalable Load Balancer,高密度可扩展的负载均衡器) 项目最初由 Intel 发起,旨在构建一个业界性能领先的四层(TCP/UDP)负载均衡器。其中:
- 高密度:指的是单个 HDSLB 节点的 TCP 并发连接数量和吞吐量特别高。
- 可拓展:指的是其性能可以随着 CPU Core 的数量或者资源总量的增加而线性拓展。
值得注意的是,在一套完整的 LB 系统中,HDSLB 定位于四层负载均衡器,而七层负载均衡器(e.g. Nginx etc..)则作为 HDSLB 的一种特殊 RS,需要挂载到 HDSLB 的后端来提供更上一层的负载均衡能力。
目前,Intel HDSLB 已经补发了 v23.04 版,并且面向开发者提供了在 Github 上托管的开源 HDSLB-DPVS 版本,以及向商业合作伙伴开放的具有更多高级特性的 HDSLB-VPP 商业化版本。
- HDSLB-DPVS:https://github.com/intel/high-density-scalable-load-balancer
- HDSLB-VPP:遵守 IPL License(Intel Prosperity License),对商业化落地友好。
作为新一代负载均衡器的典型,HDSLB 具有以下功能特性:
- 更高的性能表现:实现了单节点 150Mpps 级别的吞吐量、100M 级别的 TCP 并发连接数、10M 级别的 TCP 新建连接数、10Mpps 级别的大象流数量,性能表现处于业务领先地位。
- 优秀的硬件加速能力:基于 Intel 硬件生态系统,充分利用了 Intel Xeon 系列 CPU 的指令集,例如:AVX2、AVX512。同时也充分利用了 Intel E810 100GbE 网卡的硬件特性,例如:SRIOV、FDIR、RSS、DLB、DSA、DDP(动态设备个性化)、ADQ(应用程序设备队列)等智能网卡技术。基于 Intel Fully optimized 技术生态,使得用户可根据自身业务场景的需求进行软硬件融合加速方案的深度优化。
- 优秀的多核扩展能力:单机吞吐量很大程度上可随着 CPU Core 数量线性增长。
- 灵活的横向扩展能力:天然支持 NFV,支持灵活的横向扩缩容。
- 支持多种 LB 算法:包括 RR、WLC、Consistent Hash 等。
- 支持多种 LB 模式:包括 FULL-NAT、SNAT、DNAT、DR、IP Tunneling(IPIP)等。
- 支持 HA 集群:基于 Keepalived 实现了主备高可用,并支持 Session sync 能力。
NOTE:在下文中,我们主要讨论 HDSLB-VPP 版本。
HDSLB 的性能参数
基准性能数据
针对最重要的性能因素,我们可以从火山引擎 HDSLB 测试案例中找到了 Intel 官方认可的基准性能数据。
-
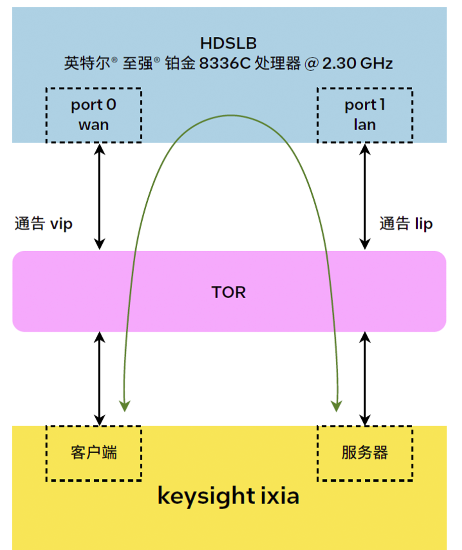
测试环境参数:
![]()
-
测试拓扑:
![]()
-
在 1~16 Core 场景中,64Bytes 转发吞吐量(单位 Mpps)测试结果如下图所示,结果越高越好。
![]()
-
在 1~4 Core 场景中,TCP CPS(单位 K)测试结果如下图所示,结果越高越好。
![]()

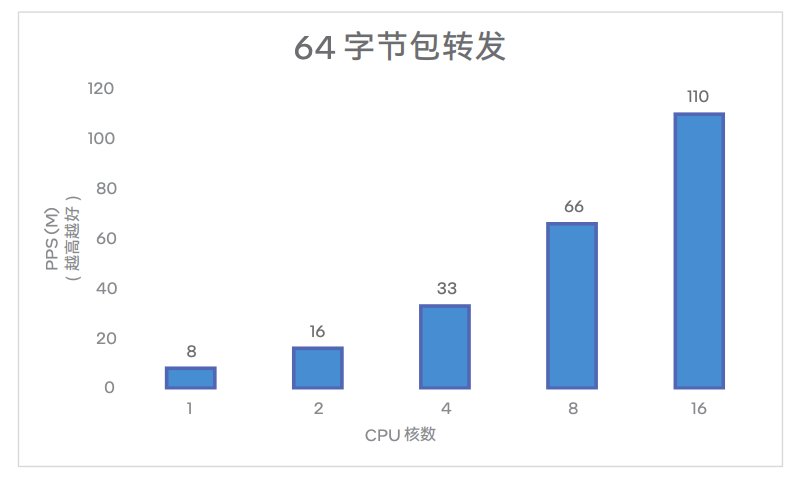

从上述结果可知,HDSLB-VPP 的单 Core 吞吐量性能达到了 8Mpps,且具有多核线性拓展特性。同时,HDSLB-VPP 的单核 TCP CPS 性能达到了 880K,且同样具有多核线性拓展特性。
对标竞品
而 HDSLB 在与某开源 L4 LB 方案最新公布的性能数据的横向对比中,我们也找到了官方的性能测试数据。
测试环境参数:
- 开源 L4 LB 测试环境参数:CPU E5-2650,每 Core 为 2K~10K 的并发 TCP 会话量,64Byte 长度的 UDP 流量。
- HDSLB-VPP 测试环境参数:CPU 第三代 Xeon-SP,每 Core 为 10M 的并发 TCP 会话量,64Byte 长度的 UDP 流量。
从下述第一张图可见,HDSLB-VPP 在 FNAT IPv4 吞吐量测试用例中,在每 Core 的并发 TCP 会话量增加了 10 倍的情况下,依旧能够取得了 3 倍以上的单 Core 吞吐量性能优势,且具有更好的多核线性扩展能力。
同时,在 FNAT 吞吐量场景中,从 MAX(尽力转发)、PDR(十万分之一丢包率)、NDR(零丢包率)这 3 种丢包模式的结果趋于一致上,也反应出了 HDSLB-VPP 具有优秀的转发稳定性。并且 NAT、DR、IPIP 等 LB 模式下的结果和 FNAT 模式趋势一致。
而第二张图则显示出,HDSLB-VPP 的 CPS(TCP 每秒新建连接数)性能相较而言有 5 倍的提升。
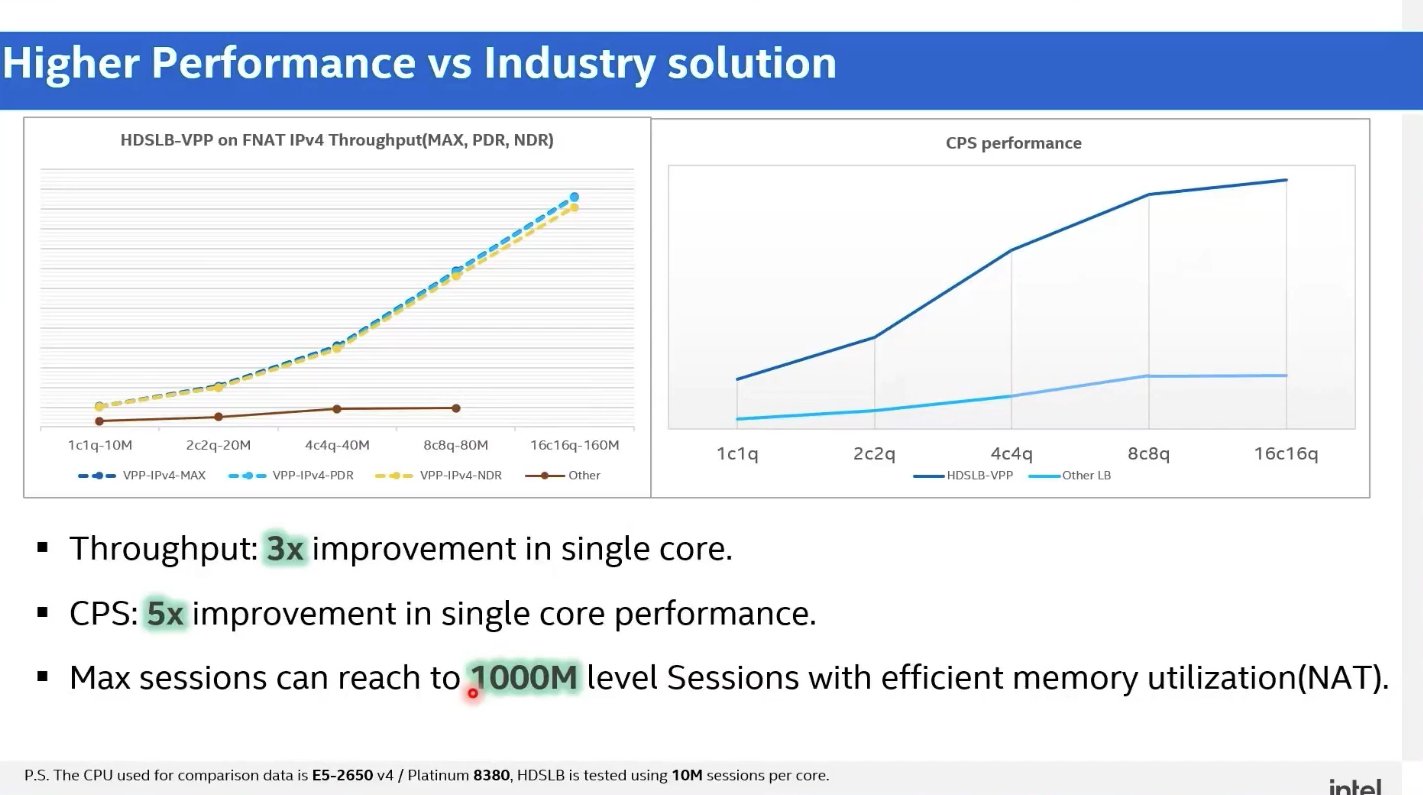
此外,HDSLB-VPP 基于 VPP 框架对数据结构内存进行了深度优化,使得在同等内存消耗的前提下,最大的并发 TCP 会话量突破预设的100M(1亿)级别,在 FNAT 模式下可扩大到 500M(5亿)级别,而在 NAT 模式下,甚至可以达到 1000M(10亿)级别。

HDSLB-VPP 对于内存方面做的优化以及并发 TCP 会话量的优势,使得 HDSLB-VPP 在 IPv6 的场景下会有更大的实用价值。在具备高性能优势的同时,还能够节省更多的系统资源用于其他业务的部署。
HDSLB 的应用场景
基于以上特性,HDSLB 目前的主要应用场景是在云计算和边缘计算中作为 L4 LB 网络单元。
针对资源集约式的云计算场景,需要面对以下 2 个关键的场景特点:
- 基础流量特别巨大:云计算租户多、流量大,而且用户业务量变化快,这就要求了 L4 LB 必须具有很好的可扩展性,能够快速响应用户业务量的增长变化,同时还要能够降低服务器采购成本为最佳。对此,HDSLB 所具有横向扩展和多核水平扩展能力能够更好的满足这一需求。
- 大象数据流时常有:云计算是一个自服务化平台,基础网络层面无法预测、也不可控制什么时候会出现大象流或老鼠流。所以,基础网元要尽可能的提升单颗 CPU Core 的数据包处理性能,才能够在一定程度上缓解 “单 Core 单 Traffic 处理模型” 中的大象流丢包或毛刺突发流量丢包问题,如下图所示。
![]()
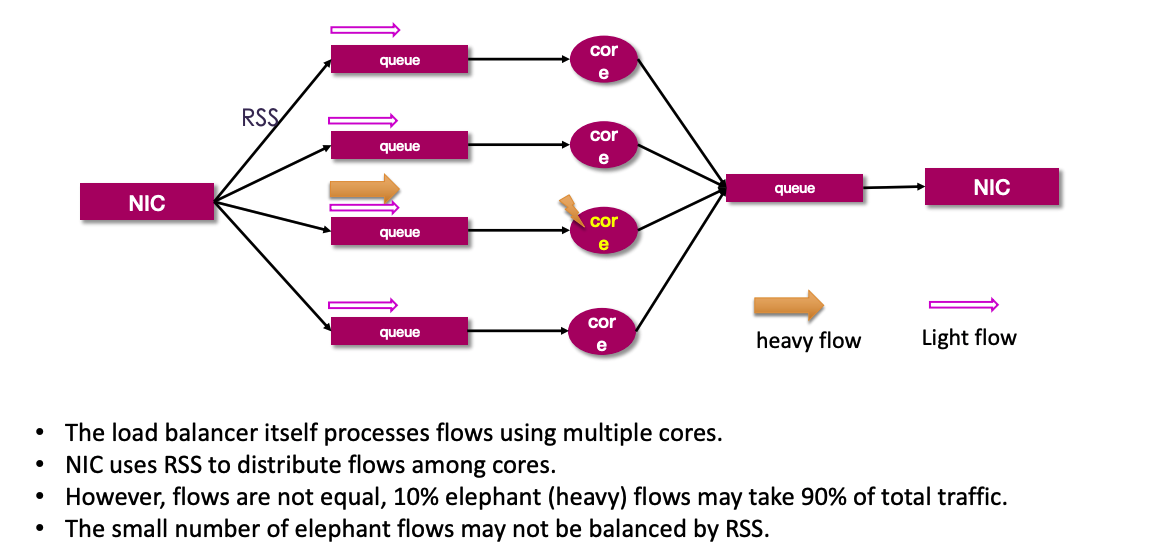
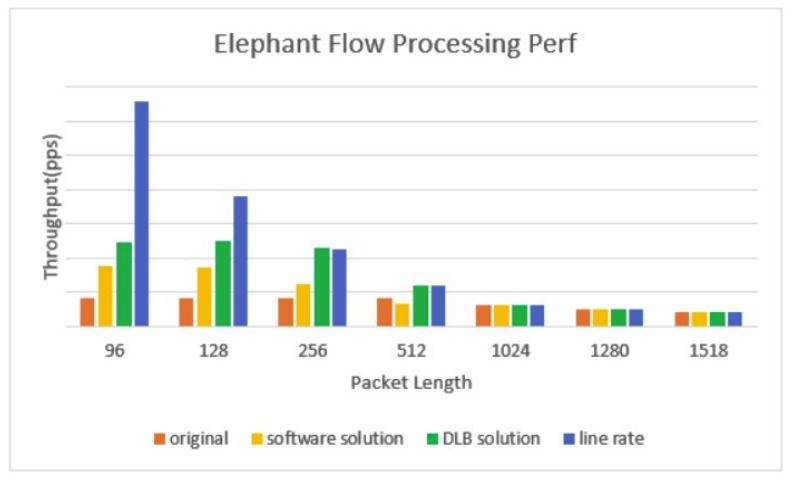
针对大象流的问题,HDSLB-VPP 基于 Intel DLB 硬件加速技术,可以在 96B、128B、256B、512B 包长的大象流场景中,相较于纯软方案具有更切近线速的提升。可以说,HDSLB 在 Intel CPU 指令集加速上的调教几乎可以说是做得最好的。
而针对面向垂直行业的、资源受限的边缘计算场景,则需要面对以下 2 个关键特点:
- 低延时业务要求高:边缘计算更多面向 OT、CT 领域的 toB 垂直行业用户,在这些领域中,其业务系统和专有网络协议对网络的延迟和抖动的要求都非常严格。对此,HDSLB 结合 Intel E810 或 IPU 系列网卡优化,可以在硬件层面上保证了数据传输的低延迟和抗抖动。
- 边缘单机能力强悍:边缘机房物理空间有限,无法塞入很多服务器数量,所以对单机性能要求是越高越好。对此,HDSLB 通过综合调优 CPU、SmartNIC/IPU 等多种硬件加速技术,能够更加全面的提升单机性能。
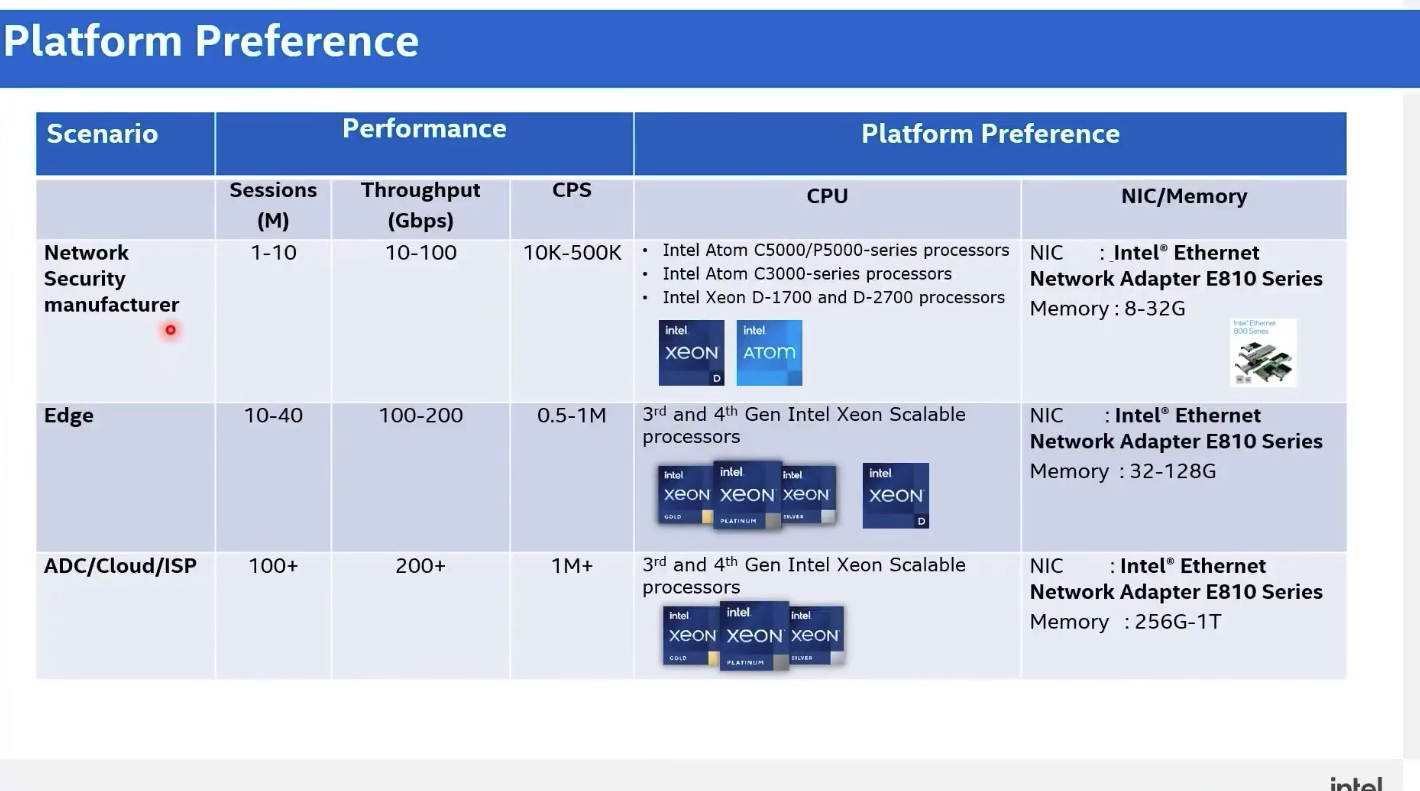
针对云计算、边缘计算、电信云、网络安全等多种不同应用场景下的性能调教组合,Intel 官方也提供了以下配置参考。
HDSLB 的发展前景
未来,HDSLB 的 Roadmap 中包括以下清单:
- 支持亿级的最大 TCP 并发连接数;
- 单 CPU Core 的吞吐量达到 8Mpps 以上,且能够随 CPU Core 的数量线性增长;
- 新建 TCP 连接的速率单 CPU Core 达到 80 万 CPS 以上,且能够随 CPU Core 的数量线性增长。
- 支持基于第四代 Xeon-SP 加速器的大象流处理能力;
- 支持 QoS 流量限速能力
- 支持 Anti-DDoS 安全能力。
- 等等。
随着业务整体趋同的 “业务网关 NFV 化,边界网关硬件化” 的技术演进趋势,HDSLB 一方面背靠 Intel 的异构计算硬件生态,另一方面背靠 DPDK、VPP 等开源社区的创新能力。双管齐下,相信 HDSLB 有望在更多的应用场景中得到应用和推广。
其中我个人主要关注在 2 个方面,包括:
- 异构加速器方案的落地,更好的解决云计算和边缘计算场景中的实际痛点,例如:大象流和老鼠流的智能感知以及调度、工业级的超低延时传输等。
- 引入先进硬件技术及其应用场景,例如:新一代 CPU 指令集、内存池化、下一代网络通信加速技术等。
参考文档
- https://blog.csdn.net/weixin_37097605/article/details/131098713
- https://www.intel.cn/content/www/cn/zh/customer-spotlight/cases/volcano-engine-edge-cloud-balance-hdslb.html
- https://www.intel.cn/content/dam/www/central-libraries/cn/zh/documents/2022-11/22-cmf233-vivo-works-with-to-optimize-hdslb-significantly-improving-load-balancing-systems-soution-briefs.pdf
- https://blog.csdn.net/Jmilk/article/details/129939424
- https://www.intel.cn/content/www/cn/zh/customer-spotlight/cases/volcano-engine-edge-cloud-balance-hdslb.html
- https://www.intel.cn/content/dam/www/central-libraries/cn/zh/documents/2023-01/23-22cmf255-volcano-engine-edge-cloud-sees-great-optimazation-in-four-tier-load-balancing-performance-with-hdslb-built-on-intel-hardware-and-software-case-study.pdf
- https://networkbuilders.intel.com/solutionslibrary/intel-dynamic-load-balancer-intel-dlb-accelerating-elephant-flow-technology-guide

 浙公网安备 33010602011771号
浙公网安备 33010602011771号