
Shuffle过程是MapReduce整个工作流程的核心环节。
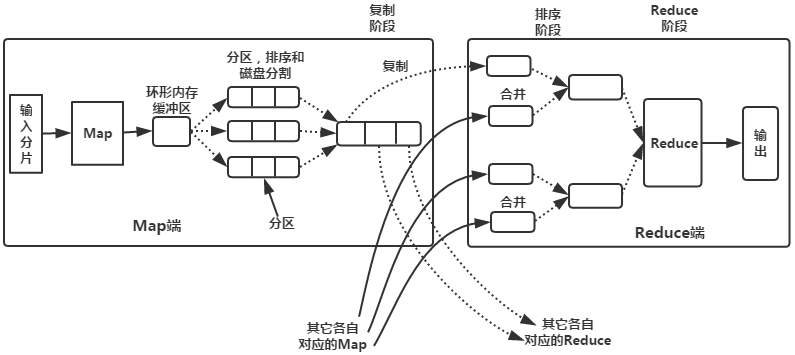
Shuffle过程是指对Map输出结果进行分区、排序、合并、归并处理后输入Reduce的过程。分为Map端和Reduce端两个部分。
Map端Shuffle过程的理解:
数据经过Map的逻辑处理后,Map将他们输出,由Shuffle进行排序、合并、归并,最终将数据转化为大磁盘文件,数据被划分为R个分区,R为Reduce任务的数量。
所谓合并:将具有相同key值value加起来,即<key1,1> <key1,1> =====> <key1,2>
所谓归并:将具有相同key值的键值对被归并为新的键值对,即<k1,v1> , <k1,v2> , <k1,v3> , <k1,v4> =====> <k1,<v1,v2,v3,v4>>
Reduce端Shuffle过程理解:
Reduce端的Shuffle过程是从大磁盘文件领取不同Map端的属于自己的数据文件,然后归并,在交给Reduce逻辑进行处理。
如图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号