Spark Standalone集群安装
前提条件,以下使用的机器都可以互相ssh免密登录
1. 下载spark, https://archive.apache.org/dist/spark,本文下载3.0.1(spark-3.0.1-bin-without-hadoop.tgz)
2. 解压文件到/usr/local/spark
3. 复制文件/usr/local/spark/conf/spark-env.sh.template,重命名为/usr/local/spark/conf/spark-env.sh,然后添加以下内容
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera export SPARK_MASTER_HOST=master1 export SPARK_MASTER_PORT=7070 export SPARK_WORKER_CORES=1 export SPARK_WORKER_MEMORY=1g #export SCALA_HOME=/usr/local/scala export HADOOP_HOME=/usr/local/hadoop #export SPARK_HOME=/usr/local/spark export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop #(required when spark job run on yarn) export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/:$LD_LIBRARY_PATH export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
4. 复制/usr/local/spark/conf/slaves.template, 重命名为/usr/local/spark/conf/slaves, 并添加如下内容
slave1
slave2
slave3
5. 将spark安装到其他3台机器(slave1,slave2,slave3)/usr/local/spark, 并将spark-env.sh,slaves重master1复制到3台机器
scp /usr/local/spark/conf/spark-env.sh root@slave1:/usr/local/spark/conf/ scp /usr/local/spark/conf/spark-env.sh root@slave2:/usr/local/spark/conf/ scp /usr/local/spark/conf/spark-env.sh root@slave3:/usr/local/spark/conf/ scp /usr/local/spark/conf/slaves root@slave1:/usr/local/spark/conf/ scp /usr/local/spark/conf/slaves root@slave2:/usr/local/spark/conf/ scp /usr/local/spark/conf/slaves root@slave3:/usr/local/spark/conf/
6. 执行命令启动集群/usr/local/spark/sbin/start-all.sh,在master1上执行jps将会看到Master进程,其他3台机器上看到Worker进程
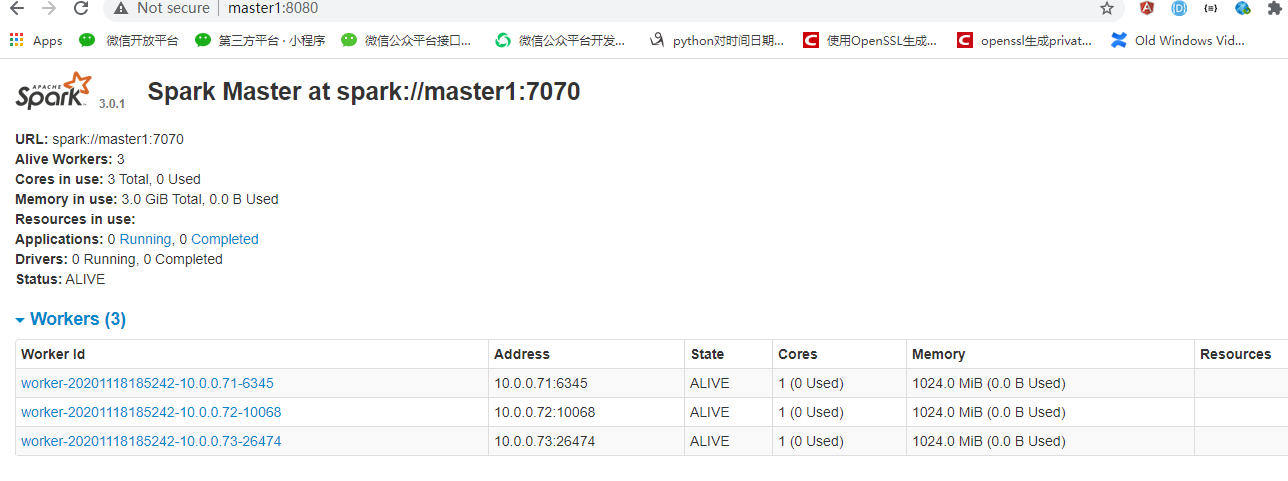
7. 访问https://master1:8080可以查看到spark集群信息
测试Spark
参考官方https://spark.apache.org/docs/latest/
1. 执行spark案例 /usr/local/spark/bin/run-example SparkPi 10
2. 终端交互式启动spark-shell,(--master local[2]表示本地以2线程执行 /usr/local/spark/bin/spark-shell --master local[2]
3. 提交job到spark集群
/usr/local/spark/bin/spark-submit --master spark://master1:7070 --class org.apache.spark.examples.SparkPi /usr/local/spark/examples/jars/spark-examples_2.12-3.0.1.jar 100


 浙公网安备 33010602011771号
浙公网安备 33010602011771号