一致性哈希算法
在了解一致性哈希算法之前,最好先了解一下缓存中的一个应用场景,了解了这个应用场景之后,再来理解一致性哈希算法,就容易多了,也更能体现出一致性哈希算法的优点,那么,我们先来描述一下这个经典的分布式缓存的应用场景
1、场景描述
假设,我们有三台缓存服务器,用于缓存图片,我们为这三台缓存服务器编号为0号、1号、2号,现在,有3万张图片需要缓存,我们希望这些图片被均匀的缓存到这3台服务器上,以便它们能够分摊缓存的压力。也就是说,我们希望每台服务器能够缓存1万张左右的图片,那么,我们应该怎样做呢?如果我们没有任何规律的将3万张图片平均的缓存在3台服务器上,可以满足我们的要求吗?可以!但是如果这样做,当我们需要访问某个缓存项时,则需要遍历3台缓存服务器,从3万个缓存项中找到我们需要访问的缓存,遍历的过程效率太低,时间太长,当我们找到需要访问的缓存项时,时长可能是不能被接收的,也就失去了缓存的意义,缓存的目的就是提高速度,改善用户体验,减轻后端服务器压力,如果每次访问一个缓存项都需要遍历所有缓存服务器的所有缓存项,想想就觉得很累,那么,我们该怎么办呢?原始的做法是对缓存项的键进行哈希,将hash后的结果对缓存服务器的数量进行取模操作,通过取模后的结果,决定缓存项将会缓存在哪一台服务器上,这样说可能不太容易理解,我们举例说明,仍然以刚才描述的场景为例,假设我们使用图片名称作为访问图片的key,假设图片名称是不重复的,那么,我们可以使用如下公式,计算出图片应该存放在哪台服务器上。
hash(图片名称)% N
因为图片的名称是不重复的,所以,当我们对同一个图片名称做相同的哈希计算时,得出的结果应该是不变的,如果我们有3台服务器,使用哈希后的结果对3求余,那么余数一定是0、1或者2,没错,正好与我们之前的服务器编号相同,如果求余的结果为0, 我们就把当前图片名称对应的图片缓存在0号服务器上,如果余数为1,就把当前图片名对应的图片缓存在1号服务器上,如果余数为2,同理,那么,当我们访问任意一个图片的时候,只要再次对图片名称进行上述运算,即可得出对应的图片应该存放在哪一台缓存服务器上,我们只要在这一台服务器上查找图片即可,如果图片在对应的服务器上不存在,则证明对应的图片没有被缓存,也不用再去遍历其他缓存服务器了,通过这样的方法,即可将3万张图片随机的分布到3台缓存服务器上了,而且下次访问某张图片时,直接能够判断出该图片应该存在于哪台缓存服务器上,这样就能满足我们的需求了,我们暂时称上述算法为HASH算法或者取模算法,取模算法的过程可以用下图表示
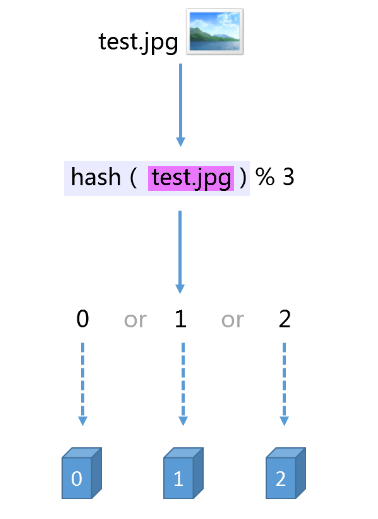
但是,使用上述HASH算法进行缓存时,会出现一些缺陷,试想一下,如果3台缓存服务器已经不能满足我们的缓存需求,那么我们应该怎么做呢?没错,很简单,多增加两台缓存服务器不就行了,假设,我们增加了一台缓存服务器,那么缓存服务器的数量就由3台变成了4台,此时,如果仍然使用上述方法对同一张图片进行缓存,那么这张图片所在的服务器编号必定与原来3台服务器时所在的服务器编号不同,因为除数由3变为了4,被除数不变的情况下,余数肯定不同,这种情况带来的结果就是当服务器数量变动时,所有缓存的位置都要发生改变,换句话说,当服务器数量发生改变时,所有缓存在一定时间内是失效的,当应用无法从缓存中获取数据时,则会向后端服务器请求数据,同理,假设3台缓存中突然有一台缓存服务器出现了故障,无法进行缓存,那么我们则需要将故障机器移除,但是如果移除了一台缓存服务器,那么缓存服务器数量从3台变为2台,如果想要访问一张图片,这张图片的缓存位置必定会发生改变,以前缓存的图片也会失去缓存的作用与意义,由于大量缓存在同一时间失效,造成了 缓存雪崩,此时前端缓存已经无法起到承担部分压力的作用,后端服务器将会承受巨大的压力,整个系统很有可能被压垮,所以,我们应该想办法不让这种情况发生,但是由于上述HASH算法本身的缘故,使用取模法进行缓存时,这种情况是无法避免的,为了解决这些问题,一致性哈希算法诞生了。
我们来回顾一下使用上述算法会出现的问题:
问题1:当缓存服务器数量发生变化时,会引起缓存的雪崩,可能会引起整体系统压力过大而崩溃(大量缓存同一时间失效)。
问题2:当缓存服务器数量发生变化时,几乎所有缓存的位置都会发生改变,怎样才能尽量减少受影响的缓存呢?
其实,上面两个问题是一个问题,那么,一致性哈希算法能够解决上述问题吗?我们现在就来了解一下一致性哈希算法
2. 一致性哈希算法的基本概念
其实,一致性哈希算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性哈希算法是对 2^32 取模,什么意思呢?
我们慢慢聊。首先,我们把二的三十二次方想象成一个圆,就像钟表一样,钟表的圆可以理解成由60个点组成的圆,而此处我们把这个圆想象成由2^32个点组成的圆
示意图如下:
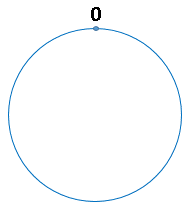
圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到2^32-1, 也就是说0点左侧的第一个点代表2^32-1
我们把这个由2的32次方个点组成的圆环称为 hash环。
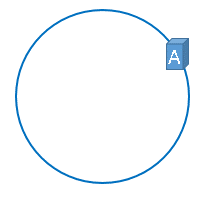
那么,一致性哈希算法与上图中的圆环有什么关系呢?我们继续聊,仍然以之前描述的场景为例,假设我们有3台缓存服务器,服务器A、服务器B、服务器C,那么,在生产环境中,这三台服务器肯定有自己的IP地址,我们使用它们各自的IP地址进行哈希计算,使用哈希后的结果对2^32取模,可以使用如下公式示意。
hash(服务器A的IP地址) % 2^32
通过上述公式算出的结果一定是一个0到2^32-1之间的一个整数,我们就用算出的这个整数,代表服务器A,既然这个整数肯定处于0到2^32-1之间,那么,上图中的hash环上必定有一个点与这个整数对应,而我们刚才已经说明,使用这个整数代表服务器A,那么,服务器A就可以映射到这个环上,用下图示意:
同理,服务器B与服务器C也可以通过相同的方法映射到上图中的hash环中:
hash(服务器B的IP地址) % 2^32
hash(服务器C的IP地址) % 2^32
通过上述方法,可以将服务器B与服务器C映射到上图中的hash环上,示意图如下:
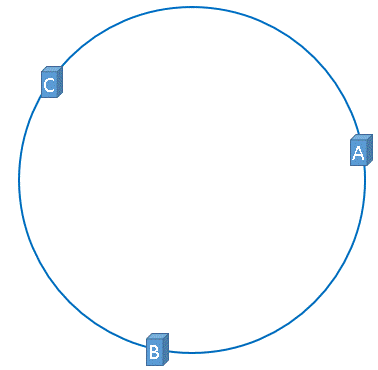
假设3台服务器映射到hash环上以后如上图所示(当然,这是理想的情况)。
好了,到目前为止,我们已经把缓存服务器与hash环联系在了一起,通过上述方法,把缓存服务器映射到了hash环上,
那么使用同样方法,我们也可以将需要缓存的对象,比如说图片映射到hash环上。
假设,我们需要使用缓存服务器缓存图片,而且我们仍然使用图片的名称作为找到图片的key,那么我们使用如下公式可以将图片映射到上图中的hash环上。
hash(图片名称) % 2^32
映射后的示意图如下,下图中的橘黄色圆形表示图片:
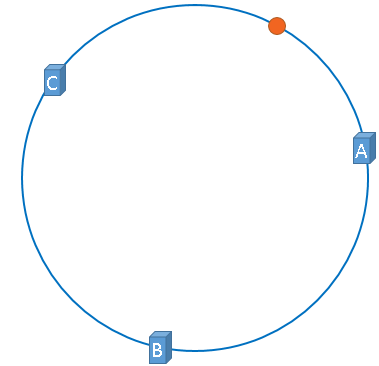
好了,现在服务器与图片都被映射到了hash环上,那么上图中的这个图片到底应该被缓存到哪一台服务器上呢?
上图中的图片将会被缓存到服务器A上,为什么呢?因为从图片的位置开始,沿顺时针方向遇到的第一个服务器 就是A服务器,所以,上图中的图片将会被缓存到服务器A上
如下图所示:
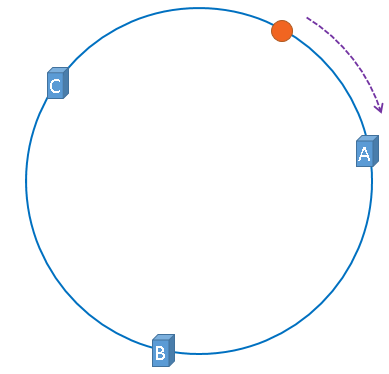
没错,一致性哈希算法就是通过这种方法,判断一个对象应该被缓存到哪台服务器上的,
将缓存服务器与被缓存对象都映射到hash环上以后,从被缓存对象的位置出发,沿顺时针方向遇到的第一个服务器,就是当前对象将要缓存于的服务器,
由于被缓存对象与服务器hash后的值是固定的,所以,在服务器不变的情况下,一张图片必定会被缓存到固定的服务器上,
那么,当下次想要访问这张图片时,只要再次使用相同的算法进行计算,即可算出这个图片被缓存在哪个服务器上,直接去对应的服务器查找对应的图片即可。
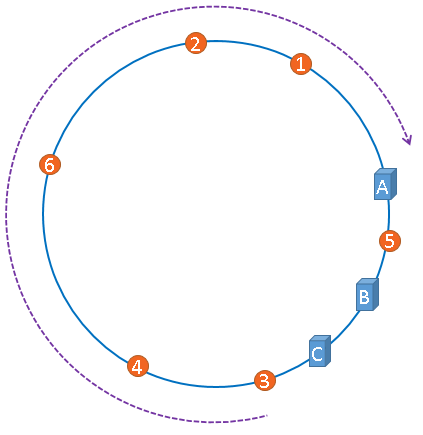
刚才的示例只使用了一张图片进行演示,假设有四张图片需要缓存,示意图如下:
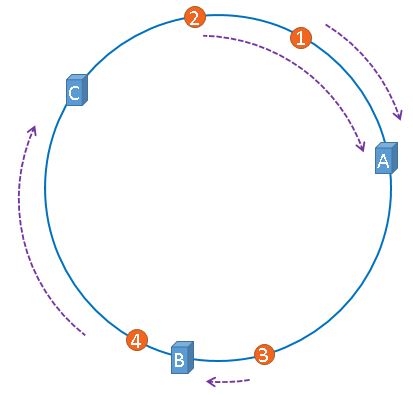
1号、2号图片将会被缓存到服务器A上,3号图片将会被缓存到服务器B上,4号图片将会被缓存到服务器C上。
3. 一致性哈希算法的优点
经过上述描述,你应该已经明白了一致性哈希算法的原理了,但是话说回来,一致性哈希算法能够解决之前出现的问题吗,
我们说过,如果简单的对服务器数量进行取模,那么当服务器数量发生变化时,会产生缓存雪崩,从而很有可能导致系统崩溃,那么使用一致性哈希算法,能够避免该问题吗?
我们来模拟一遍,即可得到答案。
假设,服务器B出现了故障,我们现在需要将服务器B移除,那么,我们将上图中的服务器B从hash环上移除即可,移除服务器B以后示意图如下。
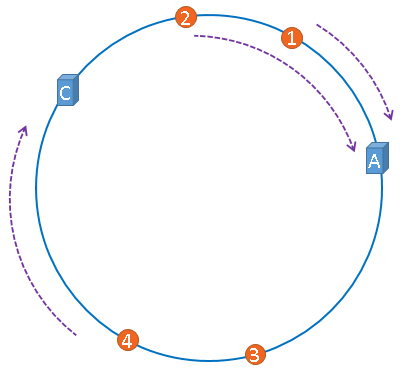
在服务器B未移除时,图片3应该被缓存到服务器B中,可是当服务器B移除以后,按照之前描述的一致性哈希算法的规则,图片3应该被缓存到服务器C中,
因为从图片3的位置出发,沿顺时针方向遇到的第一个缓存服务器节点就是服务器C,也就是说,如果服务器B出现故障被移除时,图片3的缓存位置会发生改变。
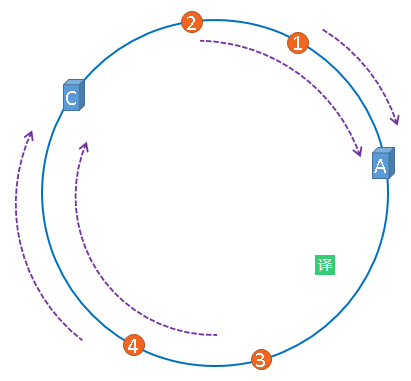
但是,图片4仍然会被缓存到服务器C中,图片1与图片2仍然会被缓存到服务器A中,这与服务器B移除之前并没有任何区别,这就是一致性哈希算法的优点
如果使用之前的普通hash算法,服务器数量发生改变时,所有服务器的所有缓存在同一时间失效了,
而使用一致性哈希算法时,服务器的数量如果发生改变,并不是所有缓存都会失效,而是只有部分缓存会失效,
前端的缓存仍然能分担整个系统的压力,而不至于所有压力都在同一时间集中到后端服务器上。
这就是一致性哈希算法所体现出的优点
4. hash环的偏斜
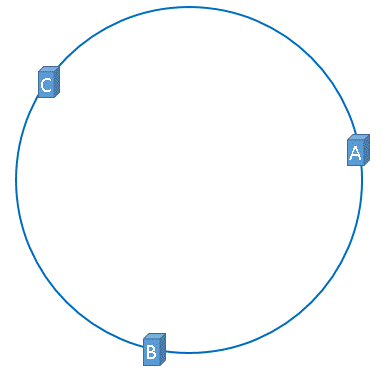
在介绍一致性哈希的概念时,我们理想化的将3台服务器均匀的映射到了hash环上,如下图所示:
但是,理想很丰满,现实很骨感,我们想象的与实际情况往往不一样, 在实际的映射中,服务器可能会被映射成如下模样。
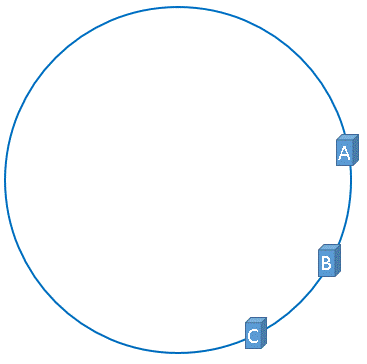
聪明如你一定想到了,如果服务器被映射成上图中的模样,那么被缓存的对象很有可能大部分集中缓存在某一台服务器上,如下图所示。
上图中,1号、2号、3号、4号、6号图片均被缓存在了服务器A上,只有5号图片被缓存在了服务器B上,服务器C上甚至没有缓存任何图片,如果出现上图中的情况,A、B、C三台服务器并没有被合理的平均的充分利用,缓存分布的极度不均匀,而且,如果此时服务器A出现故障,那么失效缓存的数量也将达到最大值,在极端情况下,仍然有可能引起系统的崩溃,上图中的情况则被称之为hash环的偏斜,那么,我们应该怎样防止hash环的偏斜呢?一致性hash算法中使用 “虚拟节点” 解决了这个问题,我们继续聊。
5.虚拟节点
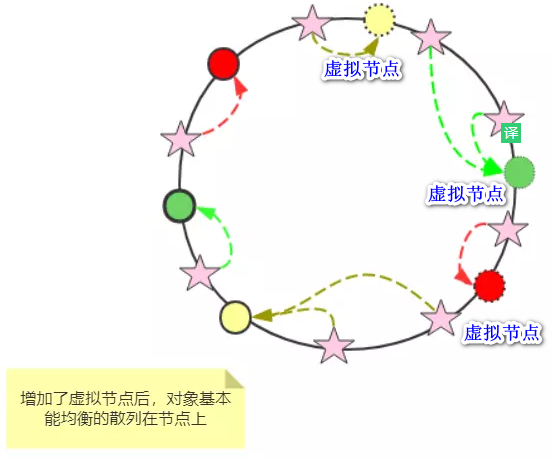
话接上文,由于我们只有3台服务器,当我们把服务器映射到hash环上的时候,很有可能出现hash环偏斜的情况,当hash环偏斜以后,缓存往往会极度不均衡的分布在各服务器上,聪明如你一定已经想到了,如果想要均衡的将缓存分布到3台服务器上,最好能让这3台服务器尽量多的、均匀的出现在hash环上,但是,真实的服务器资源只有3台,我们怎样凭空的让它们多起来呢,没错,就是凭空的让服务器节点多起来,既然没有多余的真正的物理服务器节点,我们就只能将现有的物理节点通过虚拟的方法复制出来,这些由实际节点虚拟复制而来的节点被称为”虚拟节点”。加入虚拟节点以后的hash环如下。
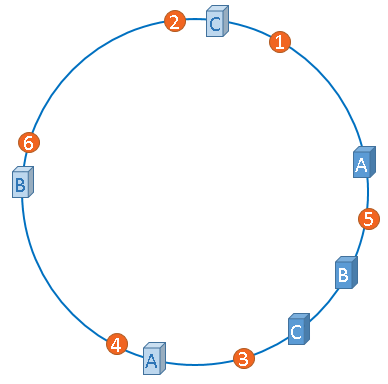
虚拟节点”是”实际节点”(实际的物理服务器)在hash环上的复制品,一个实际节点可以对应多个虚拟节点。
从上图可以看出,A、B、C三台服务器分别虚拟出了一个虚拟节点,当然,如果你需要,也可以虚拟出更多的虚拟节点。引入虚拟节点的概念后,缓存的分布就均衡多了,上图中,1号、3号图片被缓存在服务器A中,5号、4号图片被缓存在服务器B中,6号、2号图片被缓存在服务器C中,如果你还不放心,可以虚拟出更多的虚拟节点,以便减小hash环偏斜所带来的影响,虚拟节点越多,hash环上的节点就越多,缓存被均匀分布的概率就越大。
6、实例总结:
6.1 为什么普通的Hash算法不行?
普通的 hash 算法通常都是对机器数量进行取余,比如集群环境中有 3 台 redis,当我们放入对象的时,通常是对 3 进行取余。这种做法在大部分情况下是没有问题的。
但是,注意:如果缓存机器需要增减,问题就来了
假设原本是 3 个 redis,这时候,加了一台 redis,那么取余算法就变成了取余 4
这样有什么问题呢?
答:当使用负载均衡时,负载均衡器根据对象的 key 对机器数进行取余,这时,原有的 key 取余是针对机器数3的值,现有的机器数 4 就找不到那台机器了!
笨一点的办法,就是在增加机器的时候,清除所有缓存,但这会导致缓存击穿甚至缓存雪崩,严重情况下引发 DB 宕机。
6.2. 一致性 hash 怎么解决这个问题?
很简单,既然问题出在对机器取余上,那么就不对机器取余
具体怎么做呢?
答:我们假设有一个 2 的 32 次方的环形,节点主机以及需要缓存的对象都通过 hash 落在hash环上。但很大的几率是对象 hash 不到缓存节点的。怎么办呢?
找离他最近的那个节点。 比如顺时针找前面那个节点。
能解决问题吗?
想象一下:当增减机器时,环形节点变化只会影响一个节点,就是新节点的顺时针方向前面的节点。这时,我们只需清除那一个节点的数据就足够了,不用像取余 hash 那样,清除所有节点的数据。
具体类似于下图:
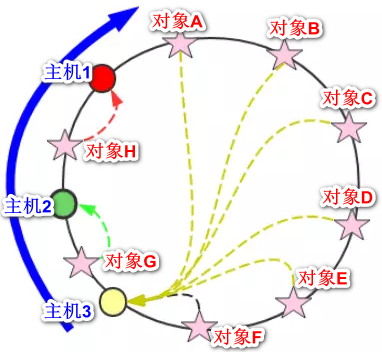
上图中,节点中的五角星代表对象,红绿黄代表节点,每个对象都会找他的上一个节点。如有增减,只影响一个节点。
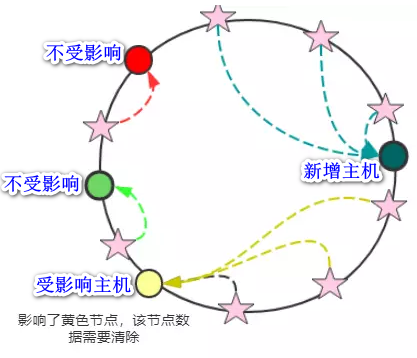
6.3. 一致性 hash 有什么问题呢?
是否这么做就完美了呢?
不是的。
如果认真看是上面的图的话,会发现,黄色节点的负载压力最大,这个集群环境负载不够均衡。
什么原因导致的呢? 原因是:如果缓存节点分布不均匀,就会出现这样的情况。但是,你不能奢望是均匀的。
怎么办呢?
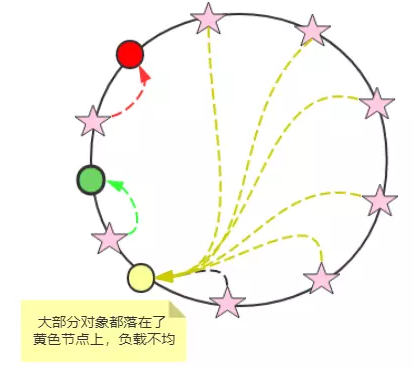
我们可以在不均的地方给他弄均匀。在空闲的地方加入 虚拟节点,这些节点的数据映射到真实节点上,就可以了,如下图所示:
图中,我们给每个节点都做了虚拟节点(虚线),从而让整个集群在 hash 环比较均匀,从图中也可看出,这样现对比之前均匀多了,黄色节点的负载和绿色节点额的负载相同。
7、实例解说
7.1普通 hash 的结果
1、实际存储对象,很简单的一个类,只需要获取他的 hash 值就好:
static class Obj { String key;
Obj(String key) { this.key = key; }
@Override public int hashCode() { return key.hashCode(); }
@Override public String toString() { return "Obj{" +"key='" + key + '\'' + '}'; } }
2、缓存对象到节点上,用于存储实际对象:
static class Node { Map<Integer, Obj> node = new HashMap<>(); //节点上缓存的对象 String name; //节点名 Node(String name) { this.name = name; } public void putObj(Obj obj) { node.put(obj.hashCode(), obj); } Obj getObj(Obj obj) { return node.get(obj.hashCode()); } @Override public int hashCode() { return name.hashCode(); } }
3、缓存节点集合,用于保存有效的缓存节点
static class NodeArray { Node[] nodes = new Node[1024]; int size = 0; public void addNode(Node node) { nodes[size++] = node; } Obj get(Obj obj) { int index = obj.hashCode() % size; return nodes[index].getObj(obj); } void put(Obj obj) { int index = obj.hashCode() % size; nodes[index].putObj(obj); } }
内部一个数组,取数据时,通过取余机器数量获取缓存节点,再从节点中取出数据
4、测试:当增减节点时,还能不能找到原有数据:
/** * 验证普通 hash 对于增减节点,原有会不会出现移动。 */ public static void main(String[] args) { NodeArray nodeArray = new NodeArray(); Node[] nodes = { new Node("Node--> 1"), new Node("Node--> 2"), new Node("Node--> 3") }; for (Node node : nodes) { nodeArray.addNode(node); } Obj[] objs = { new Obj("1"), new Obj("2"), new Obj("3"), new Obj("4"), new Obj("5") }; for (Obj obj : objs) { nodeArray.put(obj); } validate(nodeArray, objs); } private static void validate(NodeArray nodeArray, Obj[] objs) { for (Obj obj : objs) { System.out.println(nodeArray.get(obj)); } nodeArray.addNode(new Node("anything1")); nodeArray.addNode(new Node("anything2")); System.out.println("========== after ============="); for (Obj obj : objs) { System.out.println(nodeArray.get(obj)); } }
测试步骤如下:
- 向集合中添加 3 个节点。
- 向
集群中添加 5 个对象,这 5 个对象会根据 hash 值散列到不同的节点中。 - 打印
未增减前的数据。 - 打印
增加 2 个节点后数据,看看还能不能访问到数据。
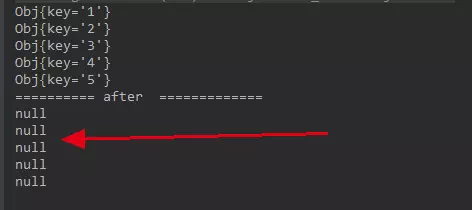
一个都访问不到了。这就是普通的取余的缺点,在增减机器的情况下,这种结果无法接收。
7.2一致性 Hash 的结果
缓存节点对象和实际保存对象不用更改,改的是什么?
改的是保存对象的方式和取出对象的方式,也就是不使用对机器进行取余的算法
新的 NodeArray 对象如下:
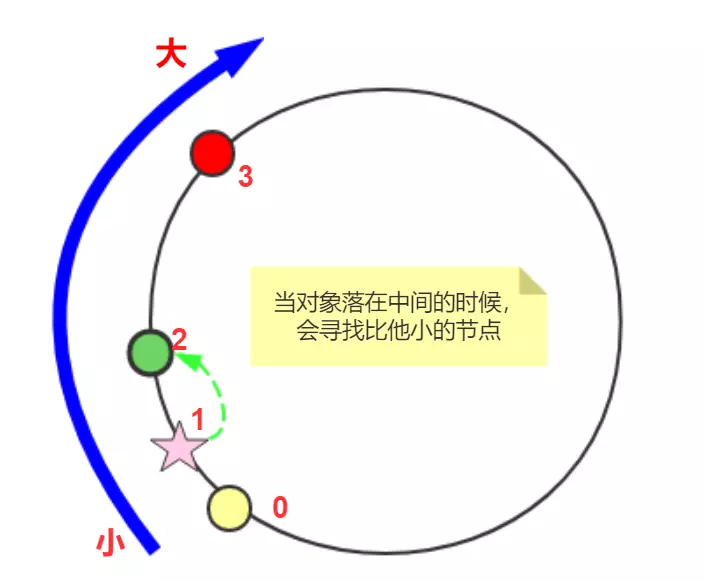
static class NodeArray { /** 按照 键 排序*/ TreeMap<Integer, Node> nodes = new TreeMap<>(); void addNode(Node node) { nodes.put(node.hashCode(), node); } void put(Obj obj) { int objHashcode = obj.hashCode(); Node node = nodes.get(objHashcode); if (node != null) { node.putObj(obj); return; } // 找到比给定 key 大的集合 SortedMap<Integer, Node> tailMap = nodes.tailMap(objHashcode); // 找到最小的节点 int nodeHashcode = tailMap.isEmpty() ? nodes.firstKey() : tailMap.firstKey(); nodes.get(nodeHashcode).putObj(obj); } Obj get(Obj obj) { Node node = nodes.get(obj.hashCode()); if (node != null) { return node.getObj(obj); } // 找到比给定 key 大的集合 SortedMap<Integer, Node> tailMap = nodes.tailMap(obj.hashCode()); // 找到最小的节点 int nodeHashcode = tailMap.isEmpty() ? nodes.firstKey() : tailMap.firstKey(); return nodes.get(nodeHashcode).getObj(obj); } }
该类和之前的类的不同之处在于:
- 内部没有使用数组,而是使用了有序 Map。
- put 方法中,对象如果没有落到缓存节点上,就找比他小的节点且离他最近的。这里我们使用了 TreeMap 的 tailMap 方法,具体 API 可以看文档。
- get 方法中,和 put 步骤相同,否则是取不到对象的。
具体寻找节点的方式如图:
相同的测试用例,执行结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号