Hadoop伪分布式模式安装
操作系统: CentOS7
jdk: jdk-8u221
hadoop: 2.7.3
一. 卸载系统自带jdk并安装准备好的jdk
1. 查看: rpm -qa | grep jdk

2.卸载: yum -y remove xxxx
3.安装jdk1.8
解压jdk包
tar zxvf jdkxxxx.tar.gz

重命名: mv jdk1.8.0_221/ jdk1.8

或者给jdk目录创建软连接 ln -s jdk1.8 jdk ( 用jdk 代替jdk1.8)
配置jdk环境变量(我装在全局下,所以修改的配置文件是/etc/profile,如果是普通用户则修改 ~/.bashrc)

使配置生效: source /etc/profile (普通用户 source ~./bashrc)
使用java -version 可以查看安装的jdk版本

4. 解压hadoop压缩包
tar zxvf hadoopxxxx.tar.gz
修改名字为hadoop2.7: mv hadoop-2.7.3 hadoop2.7

5. 配置环境变量
vi profile

source /etc/profile
测试一下

成功了, 系统找到了hdfs命令在的目录
6.伪分布式模式

安装前的准备
1. 修改一个好记的主机名 vi /etc/hostname 修改完重启 sudo reboot
2. 设置ssh免密登录
生成密钥: ssh-keygen -t rsa
本地验证: ssh-copy-id -i id_rsa id_rsa.pub jkl1
验证一下

配置伪分布式的五个文件: 在 HADOOP_HOME/etc/hadoop/下
1.vi hadoop-env.sh

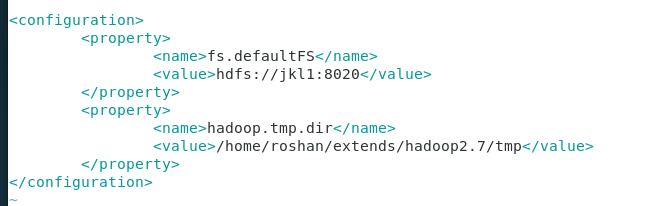
2.vi core-site.xml
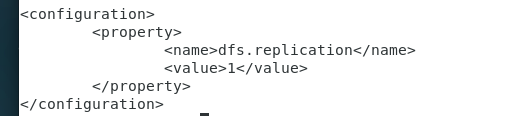
3.vi hdfs-site.xml
4. cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml

5. vi yarn-site.xml

7.格式化HDFS
hdfs namenode -format
注意: 格式化hdfs只需要一次, 下次启动不要再格式化,否则会确实DataNode进程.
8.启动Hadoop
start-dfs.sh
查看进程jps
 成功启动了hadoop
成功启动了hadoop
9. 启动yarn
strat-yarn.sh
查看进程多出两个
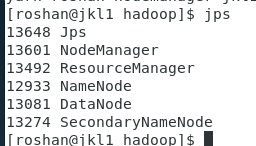 成功启动了yarn
成功启动了yarn
缺少哪个进程, 在hadoop目录下的logs里面查看错误信息
start-all.sh= start-dfs.sh+start-yarn.sh
10 . 查看web端界面 输入localhost:50070可查看NameNode和DataNode的信息
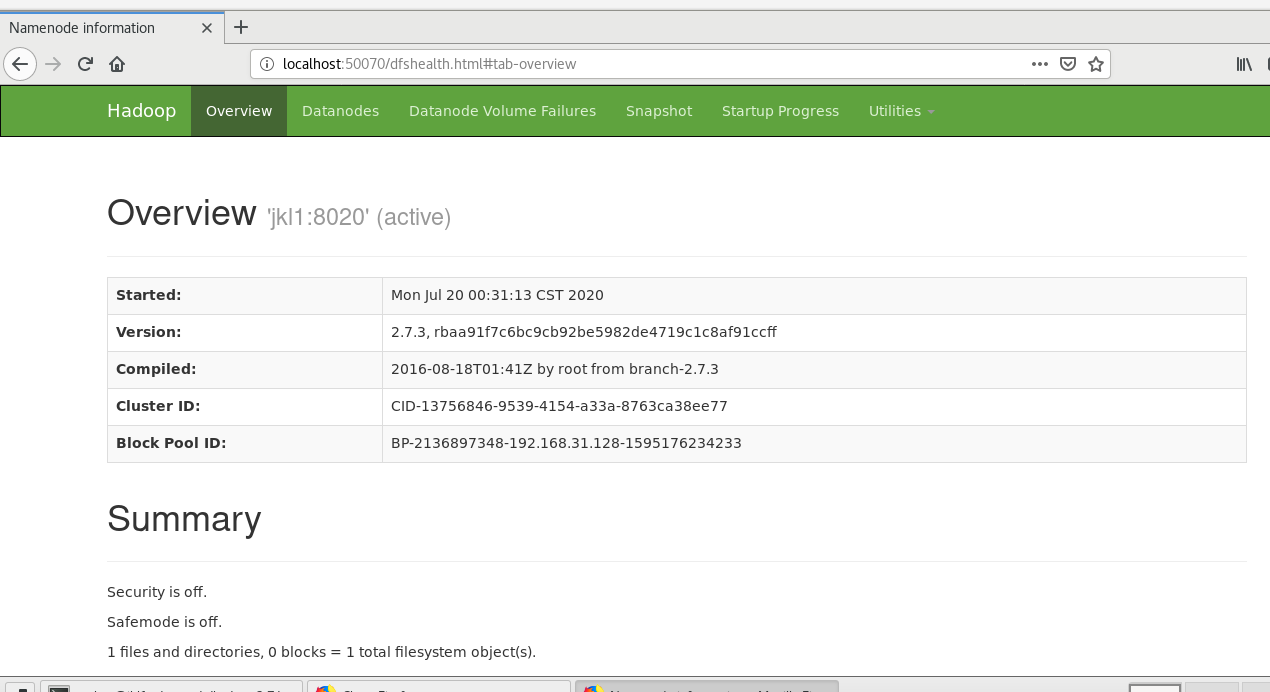
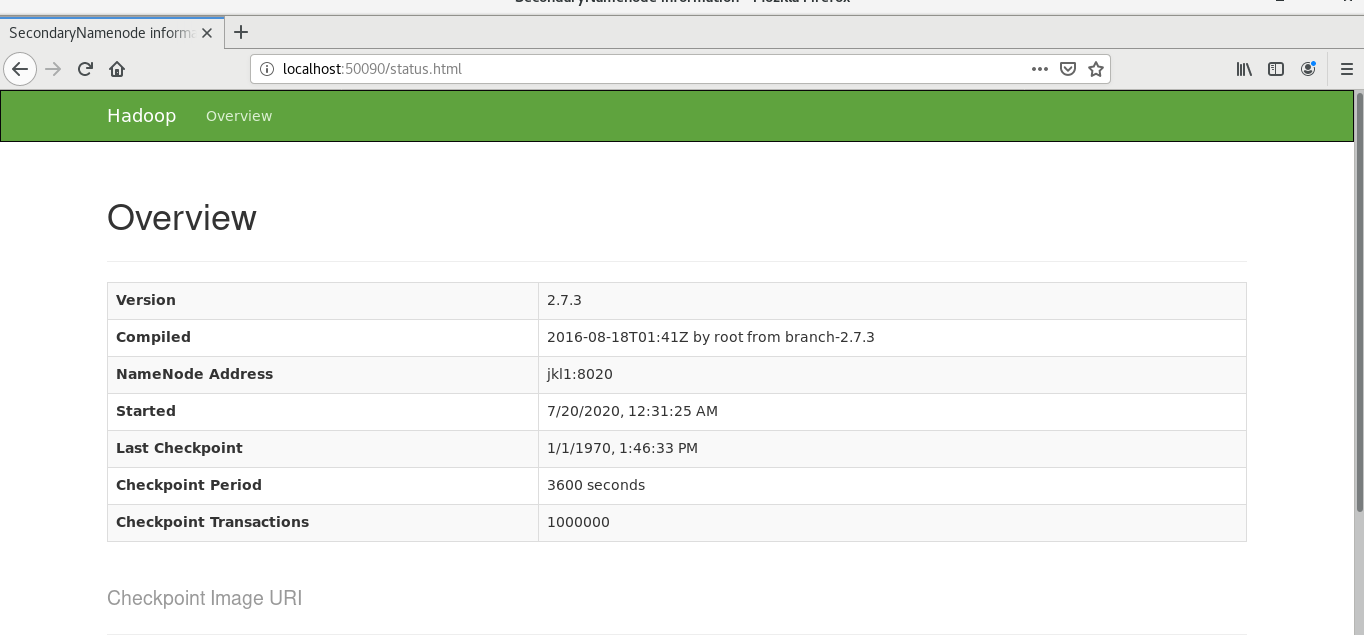
输入localhost:50090可查看SecondNameNode的信息
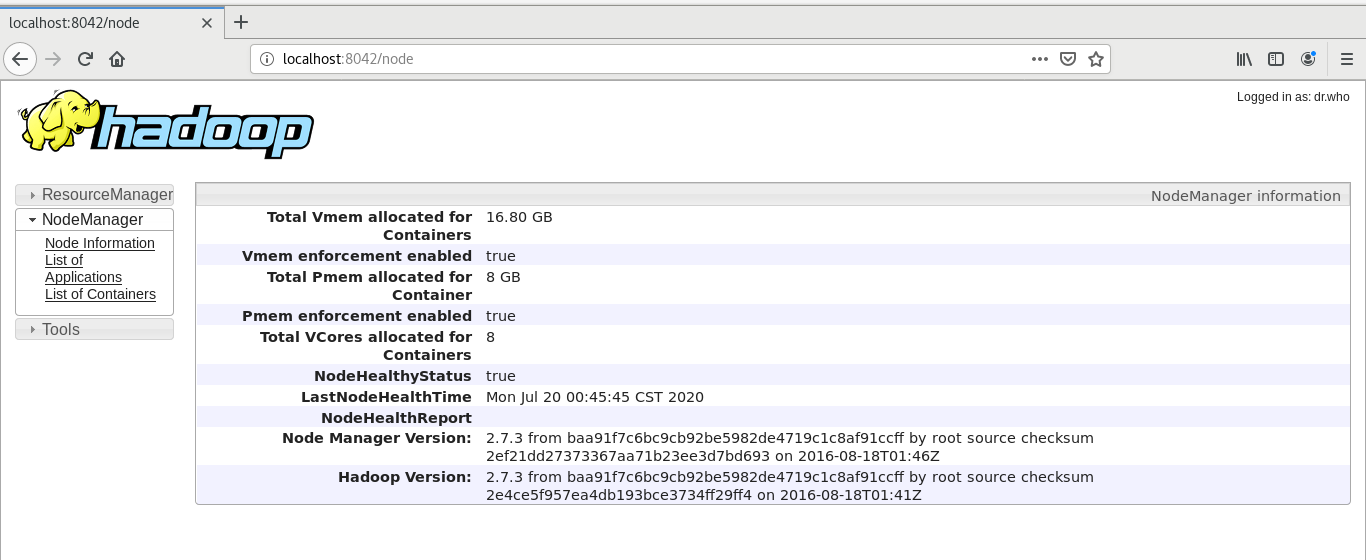
输入localhost:8042 可查看yarn下所有的应用程序(端口号不一定 ,看日记是启动的哪个端口)
11 .测试mapreduce程序
使用mapreduce 对txt文件进行词频分析
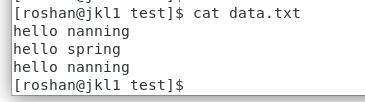
1.在linux中创建文件data.txt. 里面随意输入内容
2.在hdfs创建input文件夹, 并把data.txt上传至hdfs
在hdfs上创建input文件夹: hdfs dfs -mkdir /input
上传data.txt到input : hdfs dfs -put data.txt /input
查看是否上传成功: hdfs dfs -ls -R / (-R 以树状的形式查看目录结构)

3. 运行mapreduce实例, 这类用内置的wordcount程序来测试一下hadoop是否能正常运行
jar包位置: $HADOOP_HOME/share/hadoop/mapreduce
运行命令: hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount /input/data.txt /output (输出文件夹不能已存在)
4. 查看结果

符合预期结果. Hadoop伪分布式模式搭建成功!
关闭Hadoop : stop-all.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号