1.2023数据采集与融合技术实践作业1
实验一
作业①:
要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。
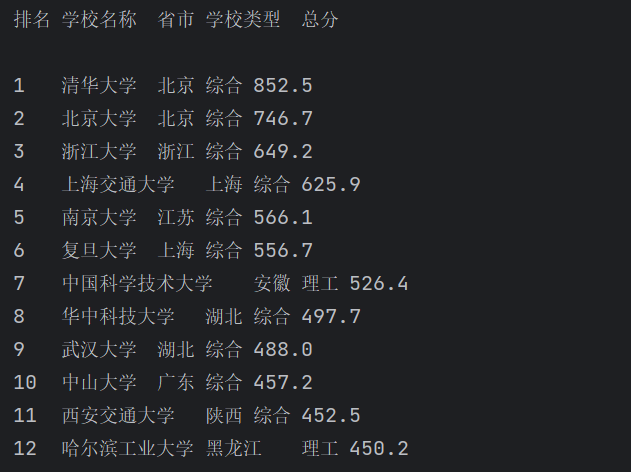
输出信息:
排名
学校名称 省市 学校类型 总分
1 清华大学 北京 综合 852.5
2......
点击查看代码
import re
import urllib.request
from bs4 import BeautifulSoup
import requests
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
resp=urllib.request.urlopen(url)
html = resp.read()
soup = BeautifulSoup(html,"html.parser")
items = soup.find('tbody').find_all("tr")
print("排名\t学校名称\t省市\t学校类型\t总分\t\n")
for item in items[0:12]:
columns = item.find_all("td")
rank = columns[0].text.strip()
name = columns[1].find("div",class_="link-container").text.strip()
province = columns[2].text.strip()
kind = columns[3].text.strip()
score = columns[4].text.strip()
print(rank+"\t"+name+"\t"+province+"\t"+kind+"\t"+score)
实验心得:学会了使用BeautifulSoup以及urllib的用法
实验二
实验:爬取商城商品的名称与价格
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
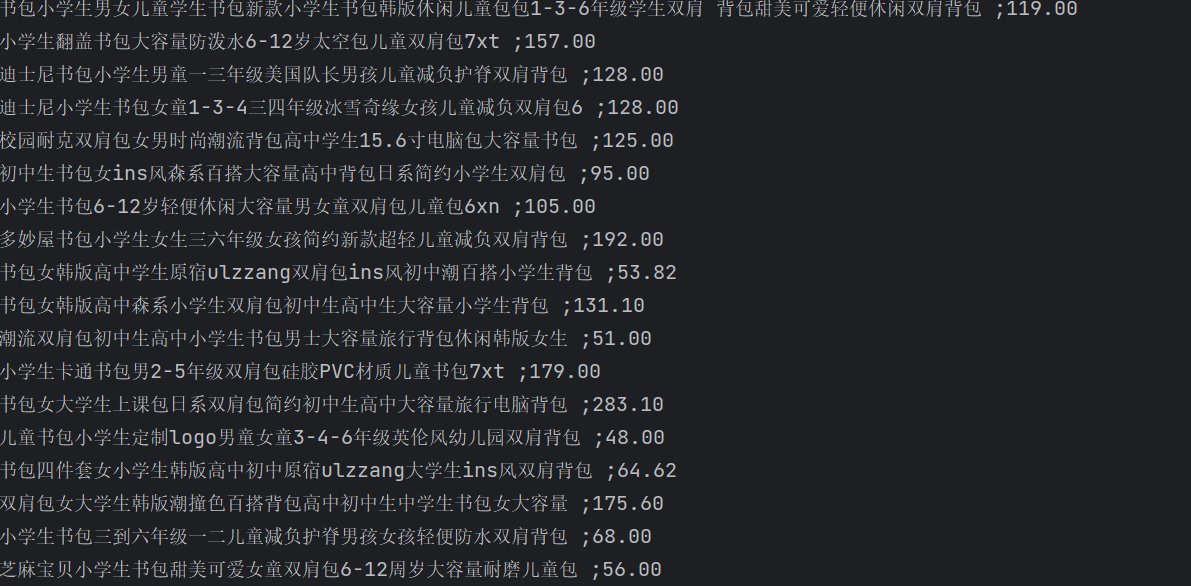
输出信息:
序号 价格 商品名
1 65.00 xxx
2......
点击查看代码
import re
import urllib.request
from bs4 import BeautifulSoup
import requests
url="http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input"
headers={
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:109.0) Gecko/20100101 Firefox/113.0"
}
response = requests.get(url=url, headers=headers)
response.encoding='GBK'
response=response.text
name = re.findall(".' alt=' (.*?)' /><p class=", response)
price = re.findall('<span class="price_n">¥(.*?)</span>', response)
print(name, price)
for i in range(0, len(name)):
print(name[i],price[i])
print("\n")
实验心得:本次实验通过requests以及re库来实现爬取当当网,然后其中也使用了正则表达式来帮助实现。
实验三
实验:爬取给定网页所有JPEG、JPG格式文件
要求:爬取一个给定网页( https://xcb.fzu.edu.cn/info/1071/4481.htm)或者自选网页的所有JPEG和JPG格式文件
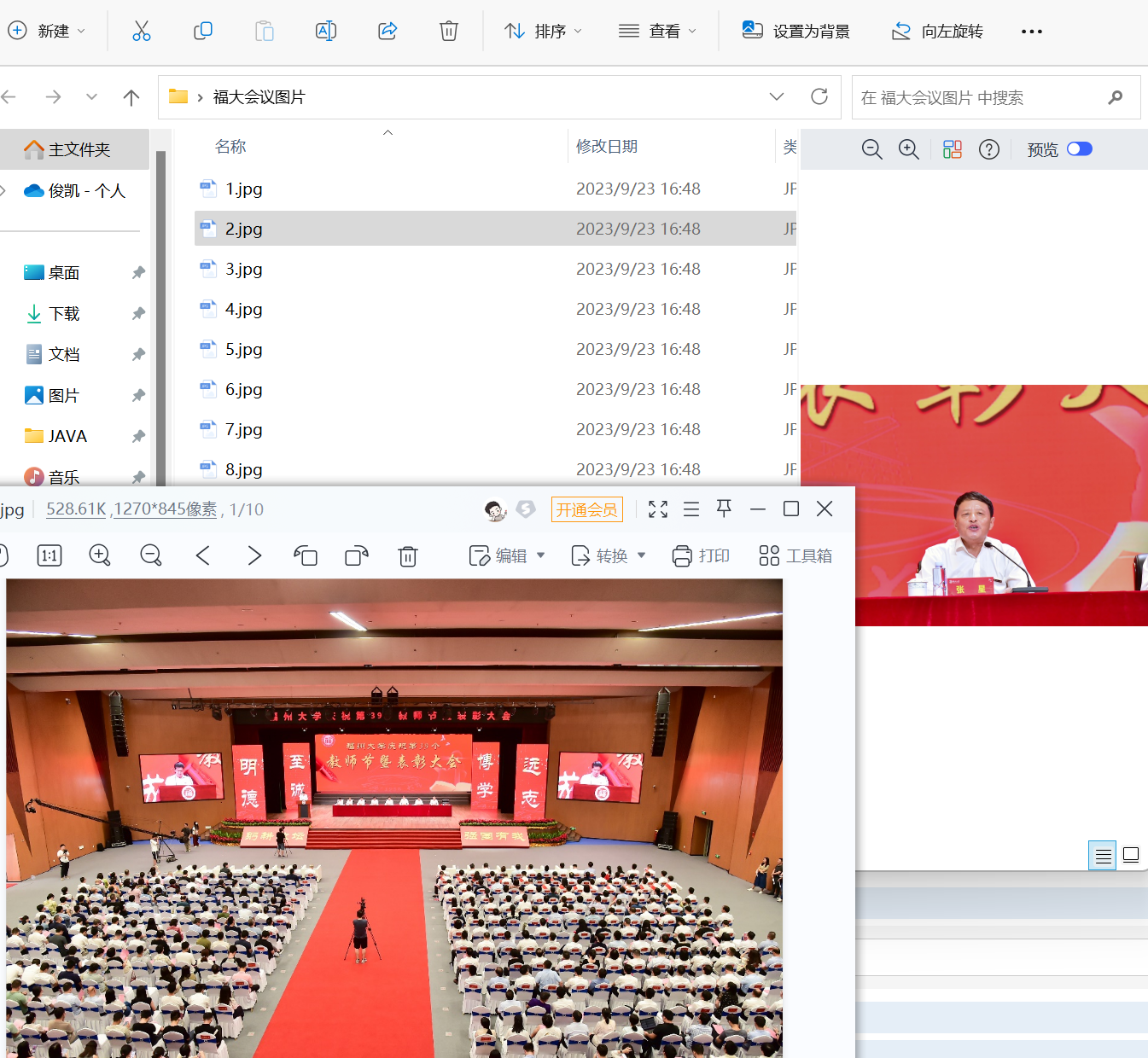
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
点击查看代码
import requests
import os
import urllib
from bs4 import BeautifulSoup
if __name__=="__main__":
if not os.path.exists('./福大会议图片'):
os.mkdir('./福大会议图片')
url="https://xcb.fzu.edu.cn/info/1071/4481.htm"
headers={
'user-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.36'
}
response=requests.post(url)
soup=BeautifulSoup(response.content,'html.parser')
# print(soup)
images = soup.find_all("img")
number=1
for image in images:
img_url = image.get("src")
newurl = "https://xcb.fzu.edu.cn" + img_url
imgpath = './福大会议图片/' + str(number) + '.jpg'
try:
urllib.request.urlretrieve(newurl,filename=imgpath)
print("下载成功")
except:
print("有问题")
img_response = requests.get(newurl)
# filename = os.path.join('./福大会议图片')
with open(imgpath,"wb") as f:
f.write(img_response.content)
number = number+1
实验心得:熟悉了re库的使用,以及加固了正则表达式,还学会了将图片下载到本地

 浙公网安备 33010602011771号
浙公网安备 33010602011771号