Mysql深入
linux上的软件相当于java中的.class文件,比如我下载的mysql,就可以通过不同的配置文件(至少是两个不同的端口)来开启两个mysql服务(相当于两个实例对象)
企业Mysql一般几百万条数据,但是mysql一般到上千万的数据就快顶不住了,查询数据可能几十秒,oracle可能好一点
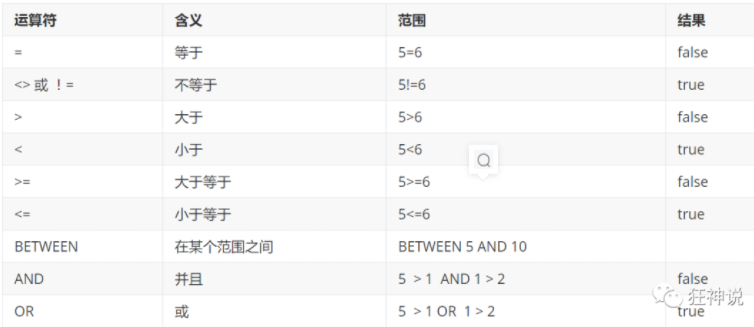
SQL(structed query language结构化查询语言)
2 操作数据库
sql语言不区分大小写,包括表名和字段名
2.6 修改表ALERT

2.7 删除表 DROP

注意点:
- 所有的字段名用 ``包裹
- 注释用 -- 、**/
- sql关键字大小写不敏感,建议大家写小写
- 所有符号用英文
3 Mysql数据管理
3.1 物理外键(了解,开发不怎么用)
FK_是通用约束名
什么是外键:
如果一张表中有一个非主键的字段指向了另一张表中的主键,就将该字段叫做外键。一张表中外键可以有多个,也就是不同字段指向了不同表中的主键。需要注意数据表的存储引擎必须为InnoDB,因为InnoDB提供事务支持以及外部键等高级数据库功能,相反的MyISAM不支持。外键的作用是保持数据一致性、完整性,主要体现在下面两个方面:
阻止执行(含有外键的表是从表,被作为外键的表是主表)
从表插入新行,其外键值不是主表的主键值便阻止插入;
从表修改外键值,新值不是主表的主键值便阻止修改;
主表删除行,其主键值在从表里存在便阻止删除(要想删除,必须先删除从表的相关行);
主表修改主键值,旧值在从表里存在便阻止修改(要想修改,必须先删除从表的相关行)。
级联执行
主表删除行,连带从表的相关行一起删除;
主表修改主键值,连带从表相关行的外键值一起修改。
比如在下面的student表中
方式一 在创建表的时候,增加约束(比较复杂)


并且由于存在外键的引用,就不能直接删除掉这张表,删除有外键关系的表的时候,必须要先删除引用别人的表,再删除被引用的表
也就是说必须删除从表(student)后才能删除主表(grade)
方式二 在创建表时不添加外键,创建后才添加外键

以上操作都是物理外键,是真实的表间存在关系,但是操作和删除都麻烦(避免数据库过多造成困扰)
最佳实践
为什么在开发的时候不使用物理外键
其实这个话题是老生常谈,很多人在工作中确实也不会使用外键。包括在阿里的JAVA规范中也有下面这一条
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
- 数据库就是单纯的表,只用来存数据,只有行(数据)和列(字段)
- 我们想使用多张表的数据,想使用外键只能用逻辑外键(需要程序去实现)
3.2 DML语言 数据操作语言(记住 )
- Insert
- Update
- Delete
Insert
【语法】:
insert into表名([字段名1,字段2,字段3])va1ues('值1','值2','值3'),('值4','值5','值6')
【注意事项】:
1.字段和字段之间使用英文逗号隔开
2.字段是可以省略的,但是后面的值必须要要——对应,不能少
3.可以同时插入多条数据,VALUES后面的值,需要使用,隔开即可VALUES (),()...

上面的value后面每一个()都代表一个对象,也就是说括号里的值必须和字段对应
第一条语句中没有插入gradeid也可以,是因为gradeid是自增的,不需要插入
插入的时候如果有些字段没有赋值会自动使用默认值

注意这里会报错,因为 gradeid设置的非空但是没有默认值,老师这里面可能有问题了
Update
正常逻辑:update 修改谁(条件) set原来的值=新值
语法:
UPDATE表名 set colnum_name1 = value,[colnum_name2 = value...] where[条件]
注意 :
- column_name 为要更改的数据列
- value 为修改后的数据 , 可以为变量 , 具体指 , 表达式或者嵌套的SELECT结果
- condition 为筛选条件 , 如不指定则修改该表的所有列数据
- 多个设置的属性之间,使用逗号隔开

条件:where 子句、运算符、id等于某个值,大于某个值,在某个区间内修改....
where会返回布尔值,如果返回为false就不会执行where前面的sql,如果为true就会执行
where 语句
Delete
语法: delete from表名[where条件]
注意:where为筛选条件 , 如不指定则删除该表的所有列数据

TRUNCATE命令
作用:用于完全清空表数据 , 但表结构 , 索引 , 约束等不变 ;
语法:
TRUNCATE [TABLE] table_name;
-- 清空年级表
TRUNCATE grade
注意:区别于DELETE命令
- 相同 : 都能删除数据 , 不删除表结构 , 但TRUNCATE速度更快
- 不同 :
-
- 使用TRUNCATE TABLE 重新设置AUTO_INCREMENT计数器即自增量归零,delete不会改变自增量,也就是或是就算删了数据下一次插入的时候还是会从之前的那个自增开始,如不指定Where则删除该表的所有列数据,自增当前值依然从原来基础上进行,会记录日志. truncate删除数据,自增当前值会恢复到初始值重新开始;不会记录日志.
- 使用TRUNCATE TABLE不会对事务有影响 (事务后面会说)
-- 同样使用DELETE清空不同引擎的数据库表数据.重启数据库服务后
-- InnoDB : 自增列从初始值重新开始 (因为是存储在内存中,断电即失)
-- MyISAM : 自增列依然从上一个自增数据基础上开始 (存在文件中,不会丢失)
3.3 DQL语言 数据查询语言(最重要)
DQL(data query language)
- 查询数据库数据 , 如SELECT语句
- 简单的单表查询或多表的复杂查询和嵌套查询
- 是数据库语言中最核心,最重要的语句
- 使用频率最高的语句
【语法】:具有严格的要求,也就是说关键字的顺序不能颠倒,GROUP BY不能写到 WHERE前面
select 字段 from 表名
注意select查询的东西是经过后面处理之后最后在进行处理的
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias]
[left | right | inner join table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条
注意 : [ ] 括号代表可选的 , { }括号代表必选得
注意所有查询的字段必须是明确的,对于某字段出现在多个表中查询时必须指定是那个表中的字段,例如studentno出现在student和result表中,查询时需要写student.studentno或者result.studentno
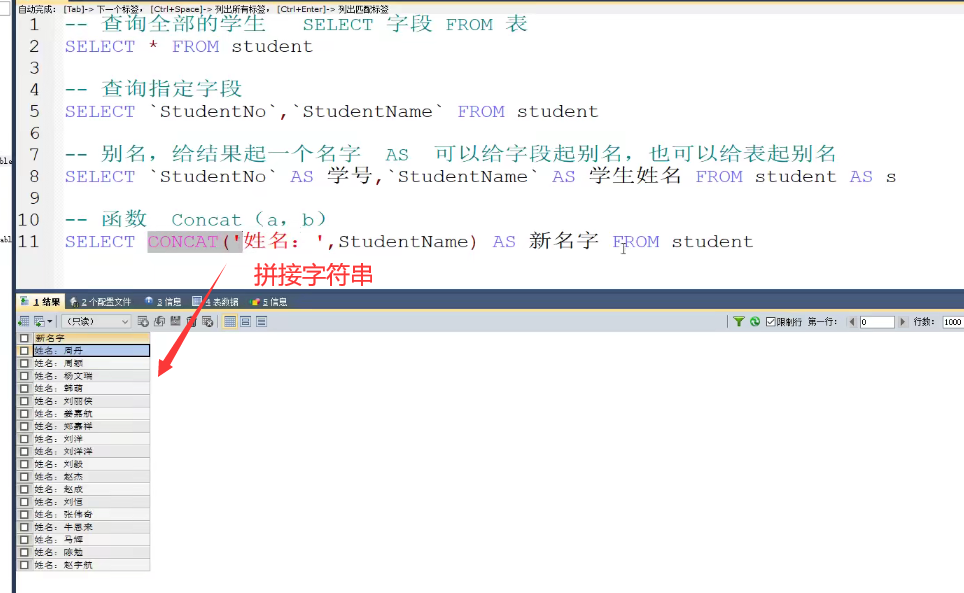
1 *、AS、CONCAT
concat是拼接查询到的字符串,
-- 查询表中所有的数据列结果 , 采用 **" \* "** 符号; 但是效率低,不推荐 .
-- 查询所有学生信息
SELECT * FROM student;
-- 查询指定列(学号 , 姓名),并且顺序输出
SELECT studentno,studentname FROM student;
-- 使用as,为查询结果取一个新名字
-- CONCAT()函数拼接字符串
SELECT CONCAT('姓名:',studentname) AS 新姓名 FROM student;
AS子句作为别名
作用:
- 可给数据列取一个新别名
- 可给表取一个新别名
- 可把经计算或总结的结果用另一个新名称来代替
-- 这里是为列取别名(当然as关键词可以省略)
SELECT studentno AS 学号,studentname AS 姓名 FROM student;
-- 使用as也可以为表取别名
SELECT studentno AS 学号,studentname AS 姓名 FROM student AS s;
2 distinct、表达式
去重DISTINCT
作用 : 去掉SELECT查询返回的记录结果中重复的记录 ( 返回所有列的值都相同 ) , 只返回一条
-- # 查看哪些同学参加了考试(学号) 去除重复项
SELECT * FROM result; -- 查看考试成绩
SELECT studentno FROM result; -- 查看哪些同学参加了考试
SELECT DISTINCT studentno FROM result; -- 了解:DISTINCT 去除重复项 , (默认是ALL,即不加distinct是会含有重复的)
使用表达式的列
数据库中的表达式 : 一般由文本值 , 列值 , NULL , 函数和操作符等组成
应用场景 :
- SELECT语句返回结果列中使用
- SELECT语句中的ORDER BY , HAVING等子句中使用
- DML语句中的 where 条件语句中使用表达式
-- selcet查询中可以使用表达式
SELECT @@auto_increment_increment; -- 查询自增步长
SELECT VERSION(); -- 查询sql版本号
SELECT 100*3-1 AS 计算结果; -- 表达式
-- 学员考试成绩集体提分一分查看
SELECT studentno,StudentResult+1 AS '提分后' FROM result;
- 避免SQL返回结果中包含 ’ . ’ , ’ * ’ 和括号等干扰开发语言程序.
3 where条件子句
作用:用于检索数据表中 符合条件 的记录
搜索条件可由一个或多个逻辑表达式组成 , 结果一般为真或假.
逻辑运算符
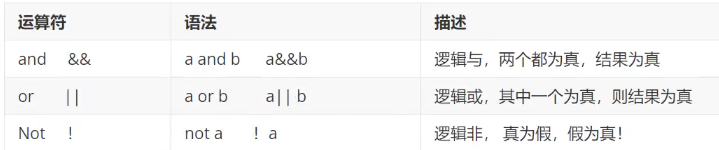
尽量使用英文
测试
-- 满足条件的查询(where)
SELECT Studentno,StudentResult FROM result;
-- 查询考试成绩在95-100之间的
SELECT Studentno,StudentResult
FROM result
WHERE StudentResult>=95 AND StudentResult<=100;
-- AND也可以写成 &&
SELECT Studentno,StudentResult
FROM result
WHERE StudentResult>=95 && StudentResult<=100;
-- 模糊查询(对应的词:精确查询)
SELECT Studentno,StudentResult
FROM result
WHERE StudentResult BETWEEN 95 AND 100;
-- 除了1000号同学,要其他同学的成绩
SELECT studentno,studentresult
FROM result
WHERE studentno!=1000;
-- 使用NOT
SELECT studentno,studentresult
FROM result
WHERE NOT studentno=1000;
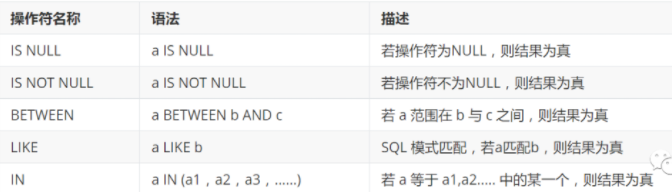
模糊查询
注意:
- 数值数据类型的记录之间才能进行算术运算 ;
- 相同数据类型的数据之间才能进行比较 ;
-- 模糊查询 between and \ like \ in \ null
-- =============================================
-- LIKE
-- =============================================
-- 查询姓刘的同学的学号及姓名
-- like结合使用的通配符 : % (代表0到任意个字符) _ (一个字符)
-- 注意%只能在like里面使用,不能在后面的IN里面用,因为IN必须跟具体的值
SELECT studentno,studentname FROM student
WHERE studentname LIKE '刘%';
-- 查询姓刘的同学,后面只有一个字的
SELECT studentno,studentname FROM student
WHERE studentname LIKE '刘_';
-- 查询姓刘的同学,后面只有两个字的,用两个_
SELECT studentno,studentname FROM student
WHERE studentname LIKE '刘__';
-- 查询姓名中含有 嘉 字的
SELECT studentno,studentname FROM student
WHERE studentname LIKE '%嘉%';
-- 查询姓名中含有特殊字符的需要使用转义符号 '\'
-- 自定义转义符关键字: ESCAPE ':'
-- =============================================
-- IN 具体的一个或者多个值
-- =============================================
-- 查询学号为1000,1001,1002的学生姓名
SELECT studentno,studentname FROM student
WHERE studentno IN (1000,1001,1002);
-- 查询地址在北京,南京,河南洛阳的学生
SELECT studentno,studentname,address FROM student
WHERE address IN ('北京','南京','河南洛阳');
-- =============================================
-- NULL 空
-- =============================================
-- 查询出生日期没有填写的同学
-- 不能直接写=NULL , 这是代表错误的 , 用 is null
SELECT studentname FROM student
WHERE BornDate IS NULL;
-- 查询出生日期填写的同学
SELECT studentname FROM student
WHERE BornDate IS NOT NULL;
-- 查询没有写家庭住址的同学(空字符串不等于null)
SELECT studentname FROM student
WHERE Address='' OR Address IS NULL;
4 连接查询 inner、left、right join
【注意】子查询的效率一遍比连接低,能用左连接就不用子查询
笛卡尔积
多个表的组合,scores n条数据,student m条数据,那么最终组成的表就有 n*m条数据,也就是n的每一条与m的每一条拼接
首先查表的时候
select * from scores,student
这样查出来就是一个完整的笛卡尔积,也就是
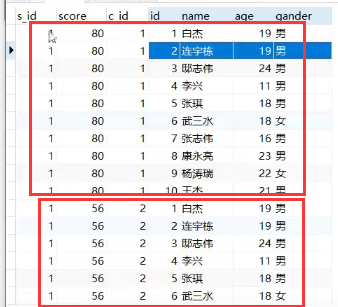
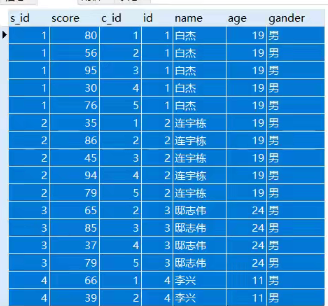
然后你可以用
select * from scores s,student r where s.s_id=r.id
这样就找到了id一一对应的
JOIN 对比
主要的内容一定放在左边,也就是需要你显示的东西就用左联其他的表

七种join:
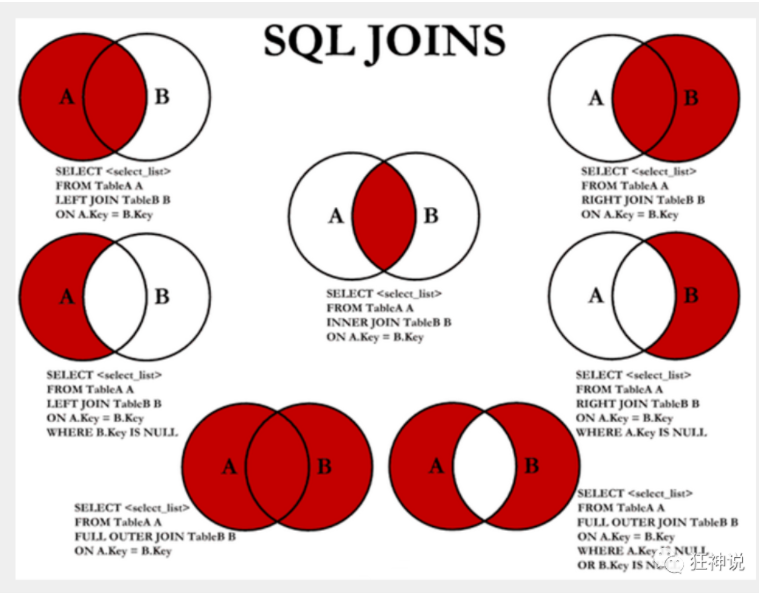
/*
连接查询
如需要多张数据表的数据进行查询,则可通过连接运算符实现多个查询
内连接 inner join ...on....(on是连接条件)where(是用来筛选连接完之后的等值查询)
查询两个表中的结果集中的交集
外连接 outer join
左外连接 left join
a left b 以a为基准
(以左表作为基准,右边表来一一匹配,匹配不上的,返回左表的记录,右表以NULL填充)
右外连接 right join
a right b 以b为基准
(以右表作为基准,左边表来一一匹配,匹配不上的,返回右表的记录,左表以NULL填充)
等值连接和非等值连接
自连接
*/
-- 查询参加了考试的同学信息(学号,学生姓名,科目编号,分数)
SELECT * FROM student;
SELECT * FROM result;
/*思路:
(1):分析需求,确定查询的列来源于两个类,student result,连接查询
(2):确定使用哪种连接查询?(内连接)
确定交叉点,即两个表中那个数据是相同的
*/
-- 注意对于某个表中特有的字段可以不加表名,例如studentname只有Student表中有
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
-- 右连接(也可实现)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
RIGHT JOIN result r
ON r.studentno = s.studentno
-- 等值连接
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s , result r
WHERE r.studentno = s.studentno
-- 左连接 (查询了所有同学,不考试的也会查出来)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
LEFT JOIN result r
ON r.studentno = s.studentno
-- 查一下缺考的同学(左连接应用场景)
SELECT s.studentno,studentname,subjectno,StudentResult
FROM student s
LEFT JOIN result r
ON r.studentno = s.studentno
WHERE StudentResult IS NULL
-- 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数)
-- 多表查询需要一张一张的联系起来
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
RIGHT JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON sub.subjectno = r.subjectno
三者区别
一、sql的left join 、right join 、inner join之间的区别
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
inner join(等值连接) 只返回两个表中联结字段相等的行
举例如下:
--------------------------------------------
表A记录如下:
aID aNum
1 a20050111
2 a20050112
3 a20050113
4 a20050114
5 a20050115
表B记录如下:
bID bName
1 2006032401
2 2006032402
3 2006032403
4 2006032404
8 2006032408
--------------------------------------------
1.left join
sql语句如下:
select * from A
left join B
on A.aID = B.bID
结果如下:
aID aNum bID bName
1 a20050111 1 2006032401
2 a20050112 2 2006032402
3 a20050113 3 2006032403
4 a20050114 4 2006032404
5 a20050115 NULL NULL
(所影响的行数为 5 行)
结果说明:
left join是以A表的记录为基础的,A可以看成左表,B可以看成右表,left join是以左表为准的.
换句话说,左表(A)的记录将会全部表示出来,而右表(B)只会显示符合搜索条件的记录(例子中为: A.aID = B.bID).
B表记录不足的地方均为NULL.
2.right join
sql语句如下:
select * from A
right join B
on A.aID = B.bID
结果如下:
aID aNum bID bName
1 a20050111 1 2006032401
2 a20050112 2 2006032402
3 a20050113 3 2006032403
4 a20050114 4 2006032404
NULL NULL 8 2006032408
(所影响的行数为 5 行)
结果说明:
仔细观察一下,就会发现,和left join的结果刚好相反,这次是以右表(B)为基础的,A表不足的地方用NULL填充.
--------------------------------------------
3.inner join
sql语句如下:
select * from A
innerjoin B
on A.aID = B.bID
结果如下:
aID aNum bID bName
1 a20050111 1 2006032401
2 a20050112 2 2006032402
3 a20050113 3 2006032403
4 a20050114 4 2006032404
结果说明:
很明显,这里只显示出了 A.aID = B.bID的记录.这说明inner join并不以谁为基础,它只显示符合条件的记录.
--------------------------------------------
5 自连接(了解)
自己的表和自己的表连接 ,核心:一张表看为两张一样的表
/*
自连接
数据表与自身进行连接
需求:从一个包含栏目ID , 栏目名称和父栏目ID的表中
查询父栏目名称和其他子栏目名称
*/
-- 创建一个表
CREATE TABLE `category` (
`categoryid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主题id',
`pid` INT(10) NOT NULL COMMENT '父id',
`categoryName` VARCHAR(50) NOT NULL COMMENT '主题名字',
PRIMARY KEY (`categoryid`)
) ENGINE=INNODB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
-- 插入数据
INSERT INTO `category` (`categoryid`, `pid`, `categoryName`)
VALUES('2','1','信息技术'),
('3','1','软件开发'),
('4','3','数据库'),
('5','1','美术设计'),
('6','3','web开发'),
('7','5','ps技术'),
('8','2','办公信息');
-- 编写SQL语句,将栏目的父子关系呈现出来 (父栏目名称,子栏目名称)
-- 核心思想:把一张表看成两张一模一样的表,然后将这两张表连接查询(自连接)
SELECT a.categoryName AS '父栏目',b.categoryName AS '子栏目'
FROM category AS a,category AS b
WHERE a.`categoryid`=b.`pid`
-- 思考题:查询参加了考试的同学信息(学号,学生姓名,科目名,分数)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON sub.subjectno = r.subjectno
-- 查询学员及所属的年级(学号,学生姓名,年级名)
SELECT studentno AS 学号,studentname AS 学生姓名,gradename AS 年级名称
FROM student s
INNER JOIN grade g
ON s.`GradeId` = g.`GradeID`
-- 查询科目及所属的年级(科目名称,年级名称)
SELECT subjectname AS 科目名称,gradename AS 年级名称
FROM SUBJECT sub
INNER JOIN grade g
ON sub.gradeid = g.gradeid
-- 查询 数据库结构-1 的所有考试结果(学号 学生姓名 科目名称 成绩)
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'
最终需要这样:
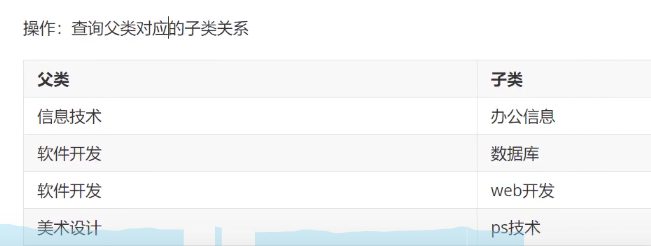
6 union和union all
union和union all用来求两个表的并集,注意union的时候查询字段一定要一致,不然查出来就没有意义,如下,也会放在一起
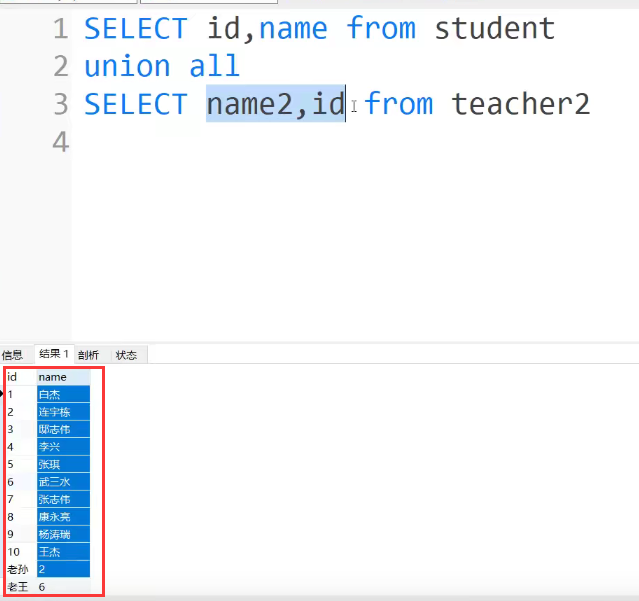
把两个语句查询到的数据并在一起
union:能去除重复的
union all:不去重,保留所有的
3.4 分页和排序
在网页查询中经常会遇到结果是有很多页的情况,前端展示的时候前端只负责渲染数据,真正的数据分页一般由数据库操作
排序 ORDER BY
意义:通过哪个字段排序
语法:ORDER BY 字段 ASC/DESC(升序/降序) 即ascend 和 descend
排序也可以用前端来实现
【注意】有多个排序条件以逗号隔开,先以第一个进行排序,然后如果有第一个属性相等的情况以第二个排序
分页 LIMIT
【语法】LIMIT 起始数据序号 一个页面大小

后端只需要LIMIT,前端需要进行计算,首先前端会拿到数据总数,需要根据前端设置的每页数据量计算总共页数,然后拿着页数去请求后端,比如前端传送数据0,5给后端,后端就会把这个值赋值给LIMIT去查询
-- 每页显示5条数据
SELECT s.studentno,studentname,subjectname,StudentResult
FROM student s
INNER JOIN result r
ON r.studentno = s.studentno
INNER JOIN `subject` sub
ON r.subjectno = sub.subjectno
WHERE subjectname='数据库结构-1'
ORDER BY StudentResult DESC , studentno
LIMIT 0,5
为什么要做分页:比如小明百度查询苹果的数据有100w条,那么不可能一次性返回给前端100w条数据让前端来展示,数据量太大,要传输得太久了,所以小明每次只能获取到一页的数据(很小的数据量),点击下一页之后就会获得下一页的数据
缓解数据库压力、增加人体验
【最新的方式】不采用分页,图片视频一般采用瀑布流的方式(通过判断浏览器的进度条来计算需要传输哪些数据),就是没有页数牡丹石但是每次只加载一个页面里面的数据,你往下拉就会有新的数据
分组和过滤 GROUP BY与having

分组,每组数据分别进行查询和过滤
使用了GROUP BY后只能用having(筛选条件)来对组的信息进行筛选,并且只能用聚合函数对组操作而不能查询到单个数据了
例如
SELECT
( SELECT d.dept_name FROM departments d WHERE de.dept_no = d.dept_no ) AS 部门,
count( de.emp_no ) AS 人数
FROM
dept_emp de
WHERE
de.to_date = '9999-01-01' ##表示在职人数
GROUP BY
de.dept_no
HAVING
count( de.emp_no ) > 30000
先用where筛选出所有用户中在职的,然后用部分分类,然后筛选出部门人数>30000人的部门
having会过滤
【注意】
使用分组,select后边的列必须是分组的条件,可以少不能多,和聚合函数
select provice,city from user GROUP BY provice,city
也就是说你查询条件是provice,city ,那么你必须至少以 provice,city 分组,因为你分组后就只剩下组的信息了,组的信息只会包含你分组的列,其他列查不到
总结:你的 GROUP BY后面的列一定要多于select后面的列(或者select后面的字段必须全部来自于GROUP BY后面的子段),不然会报错,当然你select后面可以跟多个聚合函数(这里不算做列)
注意你聚合函数里面的字段可以不是分类字段
例子一:
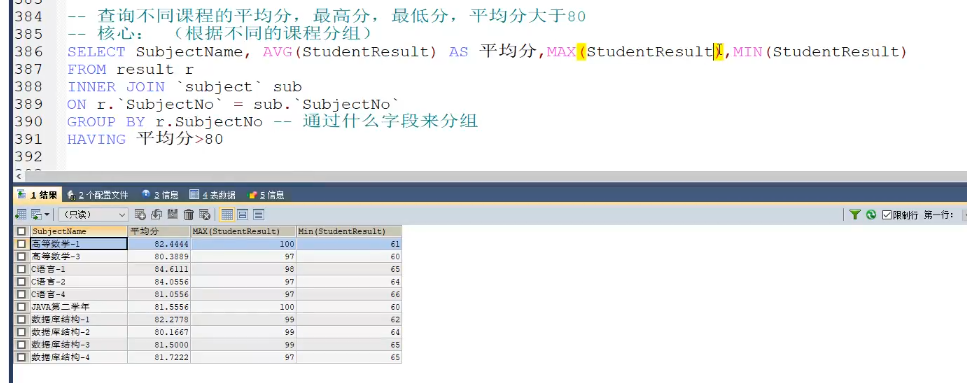
例子二:

练习

3.5 子查询
【注意】子查询的效率一遍比连接低,能用左连接就不用子查询
什么是子查询?
在查询语句中的WHERE条件子句中,又嵌套了另一个查询语句
嵌套查询可由多个子查询组成,求解的方式是由里及外;
子查询返回的结果一般都是集合,故而建议使用IN关键字;
where(这个值计算出来的)
本质:在where语句中嵌套一个子查询语句
where(select* from xxx)
-- 查询 数据库结构-1 的所有考试结果(学号,科目编号,成绩),并且成绩降序排列
-- 方法一:使用连接查询
SELECT studentno,r.subjectno,StudentResult
FROM result r
INNER JOIN `subject` sub
ON r.`SubjectNo`=sub.`SubjectNo`
WHERE subjectname = '数据库结构-1'
ORDER BY studentresult DESC;
-- 方法二:使用子查询(执行顺序:由里及外)
SELECT studentno,subjectno,StudentResult
FROM result
WHERE subjectno in (
SELECT subjectno FROM `subject`
WHERE subjectname = '数据库结构-1'
)
ORDER BY studentresult DESC;
-- 查询课程为 高等数学-2 且分数不小于80分的学生的学号和姓名
-- 方法一:使用连接查询
SELECT s.studentno,studentname
FROM student s
INNER JOIN result r
ON s.`StudentNo` = r.`StudentNo`
INNER JOIN `subject` sub
ON sub.`SubjectNo` = r.`SubjectNo`
WHERE subjectname = '高等数学-2' AND StudentResult>=80
-- 方法二:使用连接查询+子查询
-- 分数不小于80分的学生的学号和姓名
SELECT r.studentno,studentname FROM student s
INNER JOIN result r ON s.`StudentNo`=r.`StudentNo`
WHERE StudentResult>=80
-- 在上面SQL基础上,添加需求:课程为 高等数学-2
SELECT r.studentno,studentname FROM student s
INNER JOIN result r ON s.`StudentNo`=r.`StudentNo`
WHERE StudentResult>=80 AND subjectno=(
SELECT subjectno FROM `subject`
WHERE subjectname = '高等数学-2'
)
-- 方法三:使用子查询
-- 分步写简单sql语句,然后将其嵌套起来
SELECT studentno,studentname FROM student WHERE studentno IN(
SELECT studentno FROM result WHERE StudentResult>=80 AND subjectno=(
SELECT subjectno FROM `subject` WHERE subjectname = '高等数学-2'
)
)
/*
练习题目:
查 C语言-1 的前5名学生的成绩信息(学号,姓名,分数),首先必须要连接构成一张表同时包含三个参数
使用子查询,查询郭靖同学所在的年级名称
*/
SELECT studentno,studentname StudentResult FROM student s inner join result r on s.`StudentNo`=r.`StudentNo` INNER JOIN `subject` sub
ON sub.`SubjectNo` = r.`SubjectNo`
WHERE studentno IN(
SELECT subjectno FROM `subject` WHERE subjectname = '高等数学-2'
)
LIMIT 0,5
5 Mysql函数
5.1 常用函数
一般函数都可以用select进行直接计算
mysql之常用函数 - 随风行云 - 博客园 (cnblogs.com)
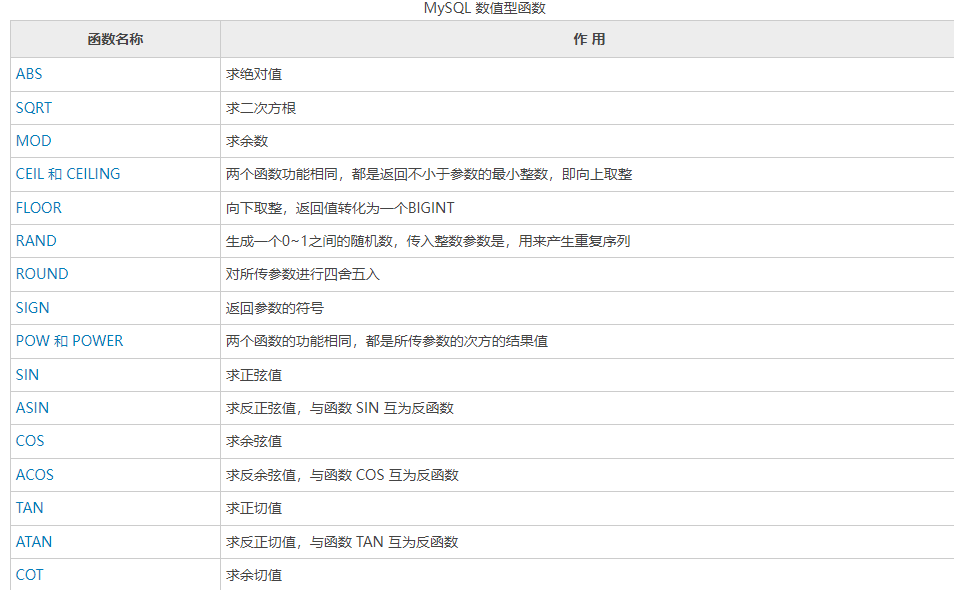


聚合函数(平均值,最大最小)
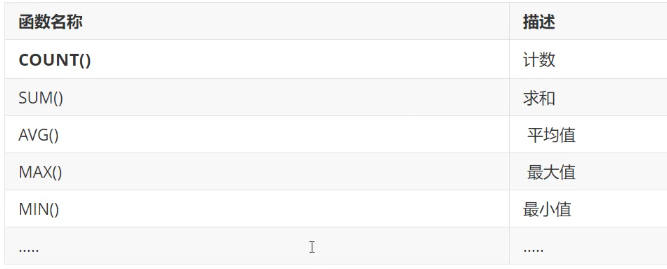
count 想查询一个表中有多少记录
百度上很多差别的文章

【综合应用】
6 视图
视图目前用的比较少了
视图一般在什么场景下使用:比如A公司和B公司合作,B需要A公司数据库中的数据,于是A不可能把数据库所有东西给B于是就创建视图,只让B看到想给他看到的东西,只把查看视图的权限给B
视图(view)是一种虚拟存在的表,是一个逻辑表,本身并不包含数据。本质作为一个select语句保存在数据字典中的。

创建视图
创建视图
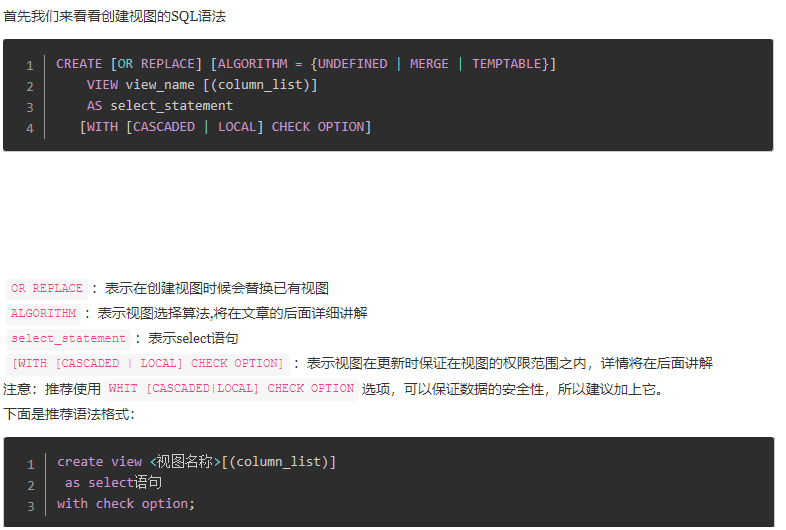
其中column list是给被查询出来的原始column重命名,例如下面的就是把查询出来的id、name命名为id、name
例子:
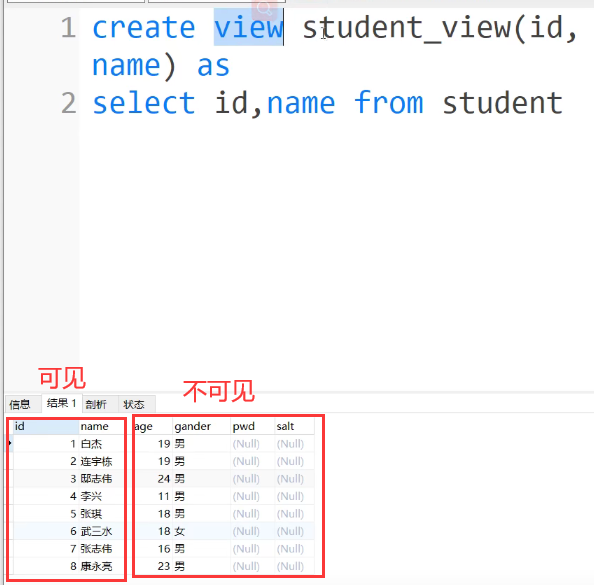
创建完视图之后,就可以把视图当做一张虚拟表进行查询操作了,但是如果view依赖的表被删除了,那么这个view就不可以用了
select * from student_view
显示视图
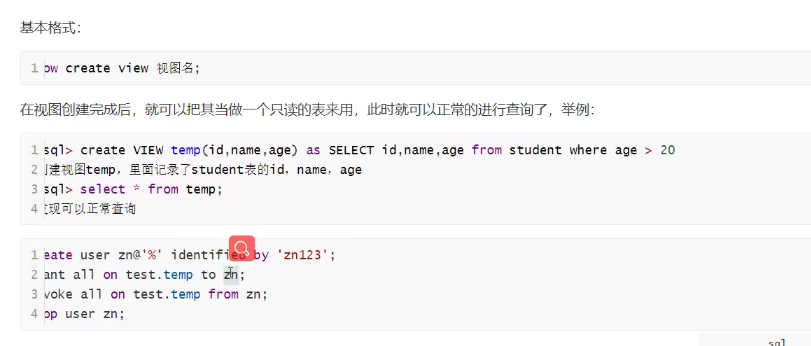
后面的语句是只赋予user zn@'%'(上面有点问题,赋权限的时候必须写全名字,不然出错)所有的权限操作test数据库中的temp视图(上面显示补全,分别是grant、revoke、drop)
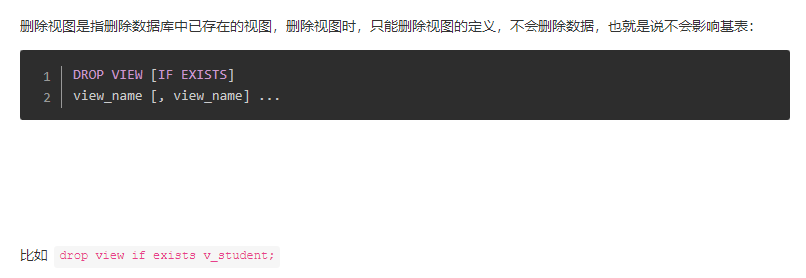
删除视图
删除视图
7 总结
sql(structed query language)
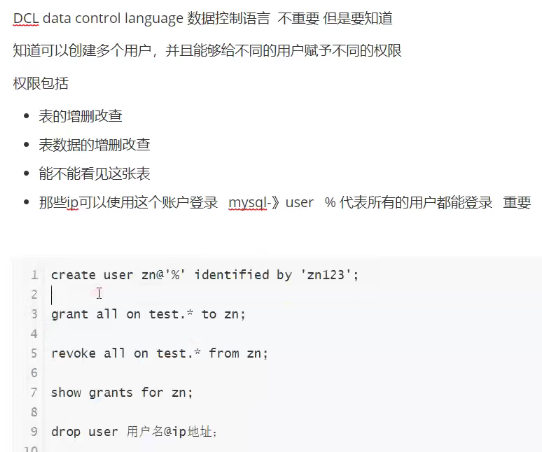
1.DCl
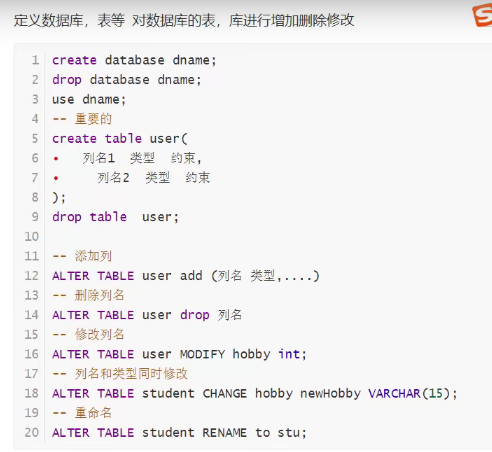
2.DDL
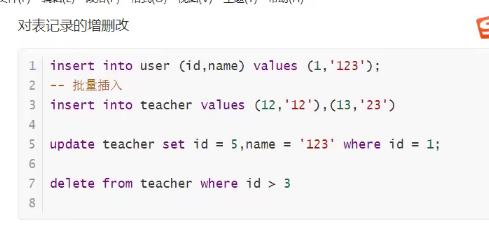
3.DML
4.DQL
数据库设计
(在楠老师mysql入门pdf中)
三范式
范式不是正确与否而是好与不好的问题
30 道sql题
最好是从整体上思考,先用连接join构建一张大表,然后再上面查询,这样比子查询快很多
我个人认为连表最简单
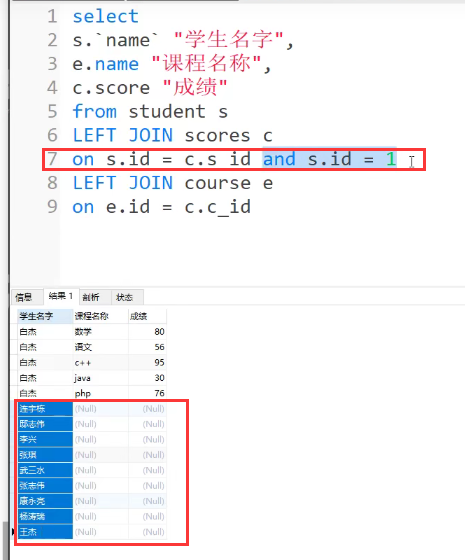
1.查询'01'号学生的姓名和各科成绩。

区分一下:on和where
如果这里用on,那么虽然只会连接s.id=1的部分(也是我们想要的数据),但是其余的会带出null,不会被筛选掉
where是连接之后把不符合的删除掉
2、查询各个学科的平均成绩,最高成绩。
方式一:join(速度更快,推荐)

方式二:子查询

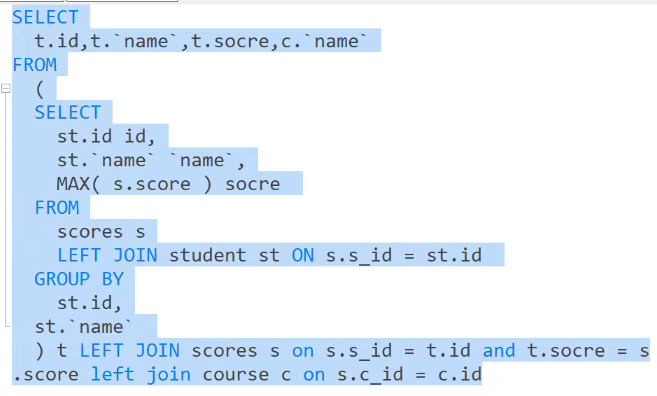
3、查询每个同学的最高成绩及科目名称。
注意这里如果我把三个表连接在一起再进行分类的话,你可能没办法得到内容,因为select的必须出现在group by中
按照题意我应该按照学号分类,这样虽然能找出最高的成绩,但是没办法显示科目名,因为你没有按照科目进行分类
【正确方法】:1.连接学生表和成绩表用id分类后找出最高成绩,2.在把1中作为一个表去左联成绩表找到科目的id3.再去用id左联科目表
4、查询所有姓张的同学的各科成绩。
select * from student s left join score sc on s.id = sc.id left join subject sb on sc.sub_id=sb.sub_id where s.name like (张%)
5、查询每个课程最高分的同学信息。
方法一:
1.成绩表按课程id分类,然后找到最高分
2.然后用上面的表,用最高分和课程左联成绩表 取出学生id、
- 学生id去左联学生表
方法二:
1.找出学生的所有成绩
2.成绩表按课程id分类,然后找到最高分
3.用表二去左联表三
6、查询名字中含有“张"和李字的学生信息和各科成绩
和4差不多
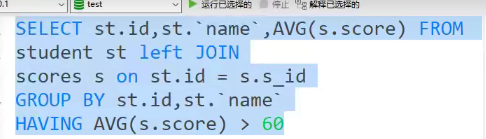
7、查询平均成绩及格的同学的信息。
1.学生和成绩左联后,成绩按学生id分类,然后用having
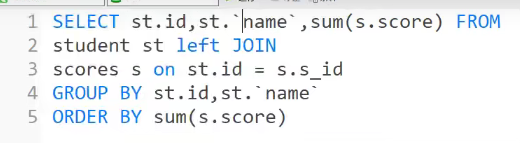
8、将学生按照总分数进行排名。
9、查询数学成绩的最高分、最低分、平均分。
太简单
10、将各科目按照平均分排序。
类似8
11、查询老师的信息和他所带科目的平均分。
老师表左联课程再左联成绩
按照老师和科目分类,求出平均分
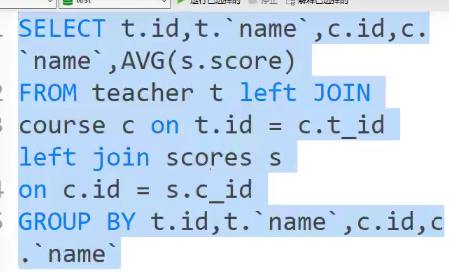
12、查询被“张楠"和“老孙教的课程的最高分和平均分。
用11的那个然后用where筛选
14、查询所有学生的课程及分数。
15、查询课程编号为01且课程成绩在80分以上的学生的学号和姓名。
成绩表和学生左联,where筛选编号为01 并且成绩>80
16、查询平均成绩大于等于85的所有学生的学号、姓名和平均成绩。
17、查询有不及格课程的同学信息。(使用最低分)
方法一:学生信息左联成绩表,然后按学生id分组,having 最低分小于60的
方法二:使用in
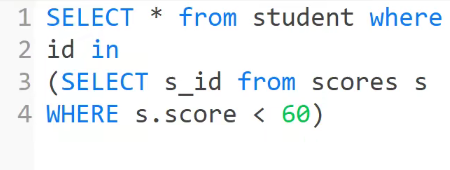
18、求每门课程的学生人数。

19、查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列
order by 平均成绩,课程
就能实现,
20、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩。
21、查询仅有一门课程成绩在90分以上的学生信息;
找出所有90分以上的成绩,然后学生id分组,然后having count等于1的,
22、查询出只有三门课程的全部学生的学号和姓名
count
23、查询有不及格课程的课程信息
min
24、检索至少选修四门课程的学生学号
count
25、查询没有学全所有课程的同学的信息
count
26、查询学全所有课程的同学的信息。
count
27、查询各学生都选了多少门课
count
28、查询课程名称为"java",且分数低于60的学生姓名和分数。
29、查询学过"张楠"老师授课的同学的信息。
老师 连课表 连 成绩表 连学生信息 where 老师为张楠
30、查间没学过"张楠"老师授课的同学的信息
三范式:
1.字段原子性,不可以再拆分
2.第二范式是建立在第一范式基础上的,另外要求所有非主键字段完全依赖主键,不能产生部分依赖
3.建立在第二范式基础上的,非主键字段不能传递依赖于主键字段(不要产生传递依赖)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号