Apache Calcite 论文学习笔记
特别声明:本文来源于掘金,“预留”发表的[Apache Calcite 论文学习笔记](https://juejin.im/post/5d2ed6a96fb9a07eea32a6ff)
最近在关注大数据处理的技术和开源产品的实现,发现很多项目中都提到了一个叫 Apache Calcite 的东西。同样的东西一两次见不足为奇,可再三被数据处理领域的各个不同时期的产品提到就必须引起注意了。为此也搜了些资料,关于这个东西的介绍2018 年发表在 SIGMOD 的一篇论文我觉得是拿来入门最合适了,以下是我关于这篇论文的思考和总结。
是什么
解释 Calcite 是什么,用论文的标题是最合适了—— A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources(一个用于优化异构数据源的查询处理的基础框架)。Calcite 提供了标准的 SQL 语言、多种查询优化和连接各种数据源的能力。从功能上看它有很多数据库管理系统的典型功能,比如 SQL 解析、SQL 校验、SQL 查询优化、SQL 生成、数据连接查询等等,但却不包括数据处理、数据存储等 DBMS 的核心功能。从另一方面看,正因为 Calcite 这种与数据处理和存储的无关的设计,才使它成为在多个数据源和数据处理引擎之间进行协调的绝佳选择。
Calcite 之前叫做 optiq,optiq 起初用于 Apache Hive 项目中,为 Hive 提供基于成本模型的优化,即CBO(cost based optimizations)。2014 年 5 月 optiq 独立出来,成为 Apache 社区的孵化项目,2014 年 9 月正式更名为 Calcite。该项目的目标是 one size fits all(一种方案适应所有需求场景),希望能为不同计算平台和数据源提供统一的查询引擎。
Calcite 的主要功能是 SQL 语法解析(parse)和优化(optimazation)。首先它会把 SQL 语句解析成抽象语法树(AST Abstract Syntax Tree),并基于一定规则或成本对 AST 的算法与关系进行优化,最后推给各个数据处理引擎进行执行。
为什么
接下来的问题就是,我们为什么需要这么一个 SQL 语法解析和优化的库呢?
如果你准备自研一个分布式计算产品,肯定少不了类似 SQL 解析、执行的功能,而实现此类功能则存在一定技术门槛,需要设计者对关系代数等领域有比较深的理解。SQL 解析的结果也需要尽量和主流的 ANSI-SQL 一致,这样也能降低公司的推广成本、使用者的学习成本。此外,大数据处理时代的分布式计算场景下,往往一条 SQL 可以解析成多棵语义对等的语法树,但考虑到不同数据结构、底层数据处理的量级、内部的过滤连接等操作的逻辑,这些语法树之间的具体执行效率往往差别很大,SQL 语句不同,底层的执行环境不同,存在的优劣选择也各不相同。
因此,怎么优化这些语法树的执行路径就是一个非常重要的课题。在这两点上,大数据处理中的批量计算、流计算、交互查询等领域多多少少都会存在一些共性问题,当把查询语句背后的关系代数、查询处理和优化等问题封装抽象之后,则有产生一个通用框架的可能。
如果你是一个数据使用者,可能会面临多种异构数据源需要整合(有传统的关系数据库、搜索引擎如 ES、缓存产品如 MongoDB、分布式计算框架如 Spark 等等),此时同样可能面临跨平台的查询语句分发及执行优化等课题。
定位
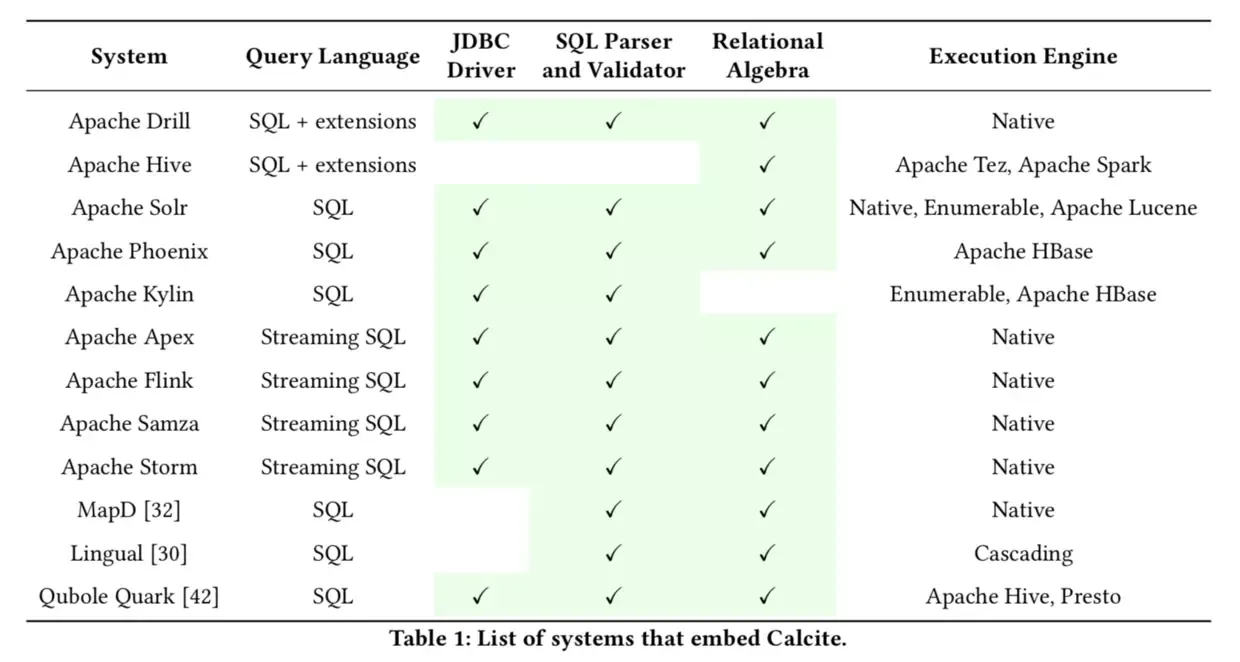
因此 Apache Calcite 应运而生,论文里把它定位为一个完整的查询处理系统,但 Calcite 的设计是非常灵活,实际项目中一般有两种使用方式:
-
把 Calcite 当作 lib 库,嵌入到自己的项目中。
![把 Calcite 的自己产品的系统列表]()
-
实现一个适配器(Adapter),项目通过读取数据源的适配器与 Calcite 集成。
![采用 Calcite 适配器的系统列表]()

功能聚集

一般来说,我们可以把一个数据库管理系统分为如上五部分, Calcite 在设计之初就确定了只关注和实现图中蓝色三部分,而把灰色的数据管理与数据存储开放给各外部计算、存储引擎来实现。这样做的目的是数据本身的特性导致通常数据管理和数据存储部分即多样(文件、关系数据库、列数据库、分布式存储等等)又复杂,Calcite 放弃了这两部分而专注于上层更通用的模块,使系统的复杂性得到有效控制,聚焦于自己能做、会做、可以做得更深更好的领域。
Calcite 也没有重复去造轮子,有现成东西可用时拿来即用,比如在 SQL 解析这一部分就直接使用了开源的 JavaCC 将 SQL 语句转化为 Java 代码,再转换成一颗抽象语法树供下一阶段使用。又比如为了实现灵活的元数据功能,Calcite 需要支持运行时编译 Java 代码,而默认的 JavaC 太重,需要一个更轻量级的编译器,这里就用了开源的 Janino 。
这种功能聚焦、不重复造轮子、足够简单的产品设计思路使 Calcite 的实现足够简单和稳定。
灵活可插拔架构
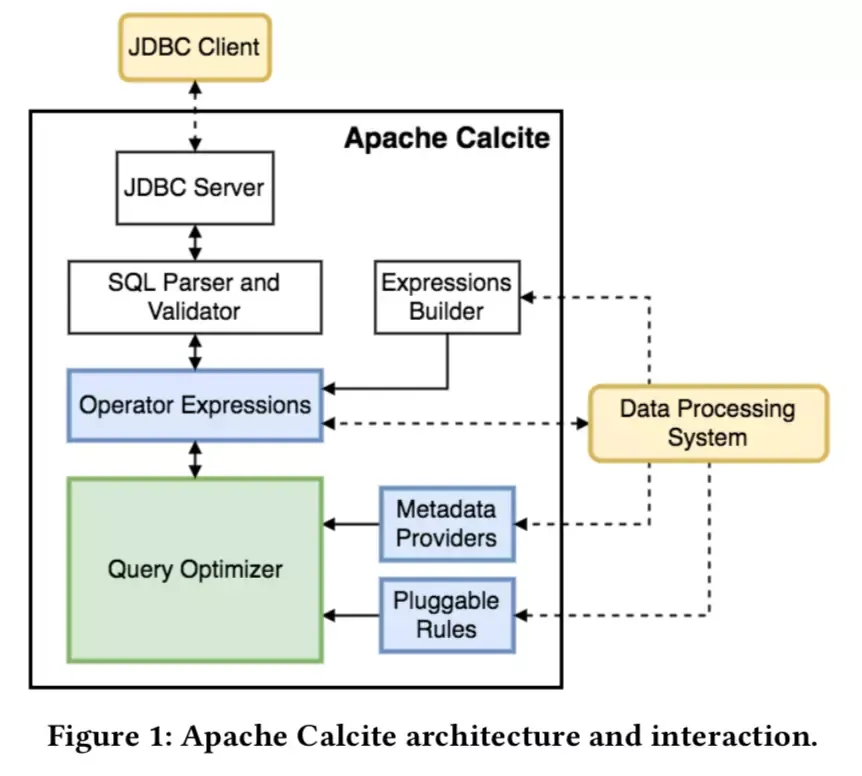
上图是论文中提到的 Calcite 的架构,Calcite 的优化器使用关系运算符树作为其内部表示,其内部优化引擎主要由三个组件组成:规则、元数据提供者和规划引擎。图中虚线表示 Calcite 与外部的相互作用,从图中可看出这种相互作用的方式有多种。
图中最上面的 JDBC client 表示外部的应用,访问时一般会以 SQL 语句的形式输入,通过 JDBC Client 访问 Calcite 内部的 JDBC Server 。接下来 JDBC Server 会把传入的 SQL 语句经过 SQL Parser and Validator 模块做 SQL 的解析和校验,而旁边的 Expressions Builder 用于支持 Calcite 做 SQL 解析和校验的框架对接。再接着是 Operator Expressions 模块来处理关系表达式,Metadata Providers 用来支持外部自定义元数据,Pluggable Rules 用来定义优化规则,最核心的 Query Optimizer 则专注查询优化。
Calcite 内部包含了一个查询解析器和验证器,它可将 SQL 查询转换为关系运算符树。由于 Calcite 不包含数据存储层,它提供了一种机制,通过适配器的方式在外部存储引擎中定义表和视图等,因此 Calcite 可以用在这些存储引擎的上层。Calcite 不仅可以为数据库语言支持的系统提供 SQL 优化,还为已经拥有自己语言解析和解释的系统提供优化支持。
由于功能模块划分比较独立、合理,Calcite 可以不用全部集成,它允许你只选择集成和使用其中的一部分功能。基本上每个模块也都支持自定义,这就让用户能实现更灵活的功能定制。
怎么做
一般来说 Calcite 解析 SQL 有下面几步: 1.解析(Parser),Calcite 通过Java CC 将 SQL 解析成未经校验的的 AST 2.验证(Validate),该步主要作用是校验上一步中的 AST 是否合法,比如如验证 SQL scheme、字段、函数等是否存在,SQL 语句是否合法等等,此步完成之后就生成了 RelNode 树 3.优化(Optimize),该步主要作用是优化 RelNode 树,把它转化成物理执行计划。涉及的 SQL 规则优化一般有两种:基于规则的优化(RBO)、基于成本的优化(CBO)这一步原则上说是可选的,经过 Validate 后的 RelNode 树实际就可以直接转化物理执行计划,但现代的 SQL 解析器基本上都有这一步,目的是优化 SQL 执行计划。该步骤得到的结果是物理执行计划。 4.执行(Execute),这一步主要做的是把物理执行计划转换成可在特定平台执行的程序。如 Hive 、Flink 都在此阶段将物理执行计划 CodeGen 生成相应的可执行代码。
下面是 Calcite 的一个查询 Demo 的例子,我们仿照 SQL 写一条查询语句,但内部数据存储并没有用任何 DB,而是用的 JVM 内存存放的数据。通过这个示例可以对 Calcite 的简单使用有一个直观感知。
maven 引入
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.study.calcite</groupId>
<artifactId>demo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<!--calcite 核心-->
<dependency>
<groupId>org.apache.calcite</groupId>
<artifactId>calcite-core</artifactId>
<version>1.19.0</version>
</dependency>
</dependencies>
</project>
定义 Schema 结构
定义一个 Schema 结构用于表示存放数据的结构是什么样子的,示例中定义了一个叫 JavaHrSchema 的 schema ,可以把它类比成数据库里面的一个 DB 实例。该 Schema 内有 Employee 和 Department 两张 table ,可以把它们理解成数据库里的表,示例最后在内存里给这两张表初始化了一些数据。
package org.study.calcite.demo.inmemory;
/**
* 定义 Schema 结构
*
* @author niwei
*/
public class JavaHrSchema {
public static class Employee {
public final int emp_id;
public final String name;
public final int dept_no;
public Employee(int emp_id, String name, int dept_no) {
this.emp_id = emp_id;
this.name = name;
this.dept_no = dept_no;
}
}
public static class Department {
public final String name;
public final int dept_no;
public Department(int dept_no, String name) {
this.dept_no = dept_no;
this.name = name;
}
}
public final Employee[] employee = {
new Employee(100, "joe", 1),
new Employee(200, "oliver", 2),
new Employee(300, "twist", 1),
new Employee(301, "king", 3),
new Employee(305, "kelly", 1)
};
public final Department[] department = {
new Department(1, "dev"),
new Department(2, "market"),
new Department(3, "test")
};
}
Java 代码示例
接下来就是写一条 SQL 语句并执行了,要做这些事情前提是告诉 Calcite 当前要操作的 Schema 、 Table 的定义,这就需要给 Calcite 添加数据源。从 Calcite 提供的 API 来看其实和 JDBC 里的数据库访问代码很类似,写过这种代码的同学肯定很熟,就不一一介绍了。
package org.study.calcite.demo.inmemory;
import org.apache.calcite.adapter.java.ReflectiveSchema;
import org.apache.calcite.jdbc.CalciteConnection;
import org.apache.calcite.schema.SchemaPlus;
import java.sql.*;
import java.util.Properties;
public class QueryDemo {
public static void main(String[] args) throws Exception {
Class.forName("org.apache.calcite.jdbc.Driver");
Properties info = new Properties();
info.setProperty("lex", "JAVA");
Connection connection = DriverManager.getConnection("jdbc:calcite:", info);
CalciteConnection calciteConnection = connection.unwrap(CalciteConnection.class);
SchemaPlus rootSchema = calciteConnection.getRootSchema();
/**
* 注册一个对象作为 schema ,通过反射读取 JavaHrSchema 对象内部结构,将其属性 employee 和 department 作为表
*/
rootSchema.add("hr", new ReflectiveSchema(new JavaHrSchema()));
Statement statement = calciteConnection.createStatement();
ResultSet resultSet = statement.executeQuery(
"select e.emp_id, e.name as emp_name, e.dept_no, d.name as dept_name "
+ "from hr.employee as e "
+ "left join hr.department as d on e.dept_no = d.dept_no");
/**
* 遍历 SQL 执行结果
*/
while (resultSet.next()) {
for (int i = 1; i <= resultSet.getMetaData().getColumnCount(); i++) {
System.out.print(resultSet.getMetaData().getColumnName(i) + ":" + resultSet.getObject(i));
System.out.print(" | ");
}
System.out.println();
}
resultSet.close();
statement.close();
connection.close();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号