
UCSC-WP&复现reverse
UCSC-WP&复现reverse
easy_re-ucsc
main函数
v7 = 10;
strcpy(Str, "n=<;:h2<'?8:?'9hl9'h:l>'2>>2>hk=>;:?");
for ( i = 0; i < strlen(Str); ++i )
Str1[i] = xor(v7, Str[i]);
Str1[strlen(Str)] = 0;
printf(Format);
scanf("%s", Str2);
if ( !strcmp(Str1, Str2) )
puts("win,TQLLLLLLL!!!");
else
puts("sorry,this is not flag");
return 0;
脚本
Str = "n=<;:h2<'?8:?'9hl9'h:l>'2>>2>hk=>;:?"
v7 = 10
Str1 = ''.join([chr(ord(c) ^ v7) for c in Str])
print(Str1)
EZ_debug-ucsc
mian函数:
strcpy(Str, "UCSC");//key
v5[0] = 0x89B83EC0E7A3CF8i64;
v5[1] = 0x3F0EA83858C85F6Ai64;
v5[2] = 0xAB8A1E39811B5F22ui64;
v5[3] = 0x649F307A6475E9B1i64;
v6 = 0xAB7BBD90;//v5和v6是密文
v8 = 36;
v3 = strlen(Str);
rc4_init(Str, v3);
rc4_crypt(v5, v8);
return 0;
脚本
import struct
def rc4_decrypt(ciphertext_hex, key):
ciphertext = bytes.fromhex(ciphertext_hex)
s = list(range(256))
j = 0
key_bytes = key.encode('ascii')
# KSA
for i in range(256):
j = (j + s[i] + key_bytes[i % len(key_bytes)]) % 256
s[i], s[j] = s[j], s[i]
# PRGA
i = j = 0
plaintext = []
for byte in ciphertext:
i = (i + 1) % 256
j = (j + s[i]) % 256
s[i], s[j] = s[j], s[i]
k = s[(s[i] + s[j]) % 256]
plaintext.append(byte ^ k)
return bytes(plaintext)
# 构造密文
cipher_qwords = [
0x089B83EC0E7A3CF8,
0x3F0EA83858C85F6A,
0xAB8A1E39811B5F22,
0x649F307A6475E9B1,
0xAB7BBD90
]
cipher_bytes = b''.join(struct.pack("<Q", q) for q in cipher_qwords[:-1])
cipher_bytes += struct.pack("<I", cipher_qwords[-1])
rc4_key = "UCSC"
decrypted = rc4_decrypt(cipher_bytes.hex(), rc4_key)
try:
print("Decrypted FLAG:", decrypted.decode())
也可以下断点调试一步到位。
simplere-ucsc
upx没法直接脱,手脱了,其实也可以稍微改一下文件头再用upx直接脱,即
flag经过变表base58加密和简单异或得到buf2
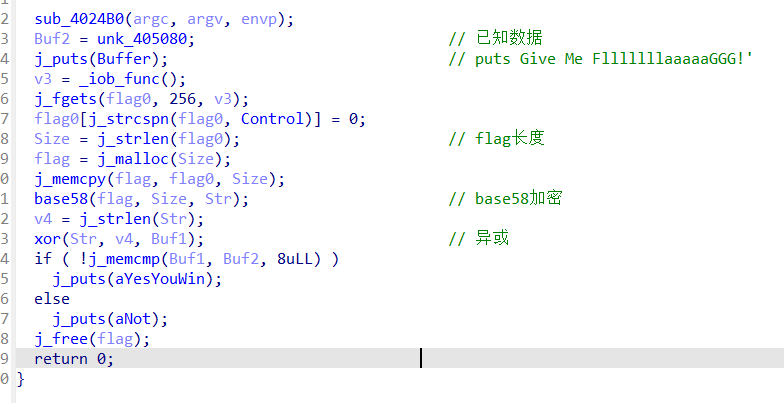
比赛的时候没做出来因为buf2数据copy少了。。。醉了,对着加密和异或代码调试了好半天
buf1 = [
0x72, 0x7A, 0x32, 0x48, 0x34, 0x4E, 0x3F, 0x3A, 0x42, 0x33,
0x47, 0x69, 0x75, 0x63, 0x7C, 0x7D, 0x77, 0x62, 0x65, 0x64,
0x7B, 0x6F, 0x62, 0x50, 0x73, 0x2B, 0x68, 0x6C, 0x67, 0x47,
0x69, 0x15, 0x42, 0x75, 0x65, 0x40, 0x76, 0x61, 0x56, 0x41,
0x11, 0x44, 0x7F, 0x19, 0x65, 0x4C, 0x40, 0x48, 0x65, 0x60,
0x01, 0x40, 0x50, 0x01, 0x61, 0x6F, 0x69, 0x57
]
str_len = 58
rev = [0] * str_len
#xor
for i in range(str_len):
rev[str_len - 1 - i] = buf1[i] ^ (i + 1)
original_bytes = bytes(rev)
print("Recovered str:", original_bytes.decode(errors="replace"))
#base58
BASE58_ALPHABET = "wmGbyFp7WeLh2XixZUYsS5cVv1ABRrujdzQ4Kfa6gP8HJN3nTCktqEDo9M"
def base58_decode(s):
num = 0
for char in s:
num *= 58
num += BASE58_ALPHABET.index(char)
return num.to_bytes((num.bit_length() + 7) // 8, 'big')
s = "mPWV7et2RTxobH5Tn8iqGSdFWc5vYzps1jHuynpvpfmsmxeL9K28H1L1xs"
decoded = base58_decode(s)
print(decoded)
#flag{0ba878d9-8bb5-11ef-b419-a4b1c1c5a2d2}
re_ez-ucsc
rust一点也不会,对着其他师傅的WP复现了一下。动调找到输入函数和退出点下断点,分析中间的函数。
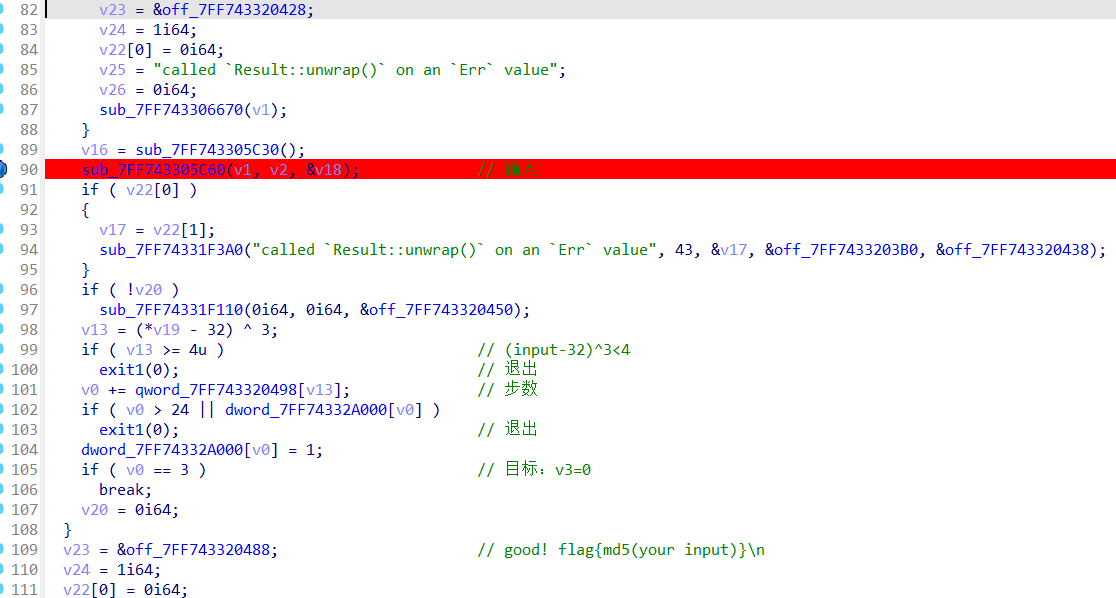
v13 = (*v19 - 32) ^ 3;
if ( v13 >= 4u )
exit1(0);
v19是输入,这里说明(input-32)^3<4,即input范围[32,35],
| v19 | v13 | ASCII |
|---|---|---|
| # | 0 | 35 |
| " | 1 | 34 |
| ! | 2 | 33 |
| 空格 | 3 | 32 |
v0 += qword_7FF743320498[v13];这里可以分析出qword_7FF743320498[v13]里代表步数,

也就是
| v19 | 步数 | 操作 |
|---|---|---|
| # | -5 | 上 |
| " | +5 | 下 |
| ! | -1 | 左 |
| 空格 | +1 | 右 |
同时可以得出迷宫应该是5列
if ( v0 > 24 || dword_7FF74332A000[v0] )//不能超出迷宫范围&&不能走到值为1的位置
exit1(0);

这里数组可以推断出是迷宫,提取出来dword_7FF74332A000[v0]={1,0,1,0,1,1,0,1,0,1,1,0,1,0,1,1,0,0,0,1,1,1,1,1,1}

这里的if判断说明只允许走到迷宫里值为0的部分,所以应该向下x3,向右x2,向上x3,即""" ###
flag{c4eb11b0e0a3cbeed7df057deaec18aa}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号