计算机学科基础
HTTP 详细介绍
请求与回应
什么是URL?(统一资源定位器)
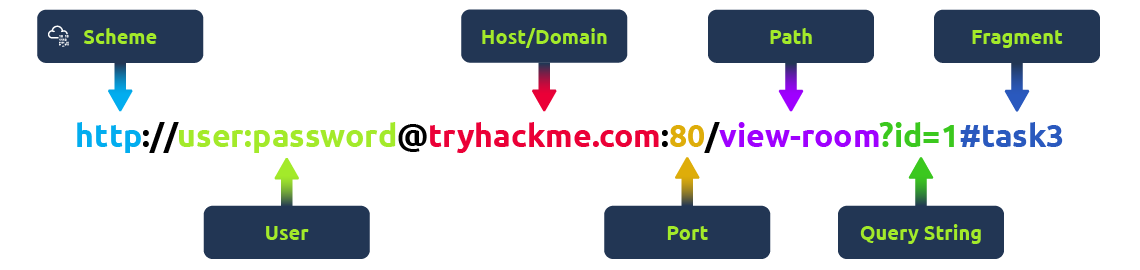
方案(scheme): 这会指导使用哪种协议访问资源,比如HTTP、HTTPS、FTP(文件传输协议)。
用户(user): 有些服务需要身份验证才能登录,你可以在URL里输入用户名和密码登录。
主持人(host/domain): 你想访问服务器的域名或IP地址。
端口(port): 你要连接的端口通常是 HTTP80,HTTPS为443,但它可以托管在1到65535之间的任意端口上。
路径(path): 你试图访问的资源的文件名或位置。
查询字符串(query string): 可以发送到请求路径的额外信息。比如,/blog?id=1 会告诉博客路径你希望接收 ID 为 1 的博客文章。
片段(fragment): 这是对实际页面上某个地点的引用。这通常用于内容较长的页面,并且可以直接链接页面的某个部分,这样用户一进入页面就能立即查看。
提出请求
完全可以用一行 GET / HTTP/1.1 向 Web 服务器发出请求(请求方法+HTTP版本)
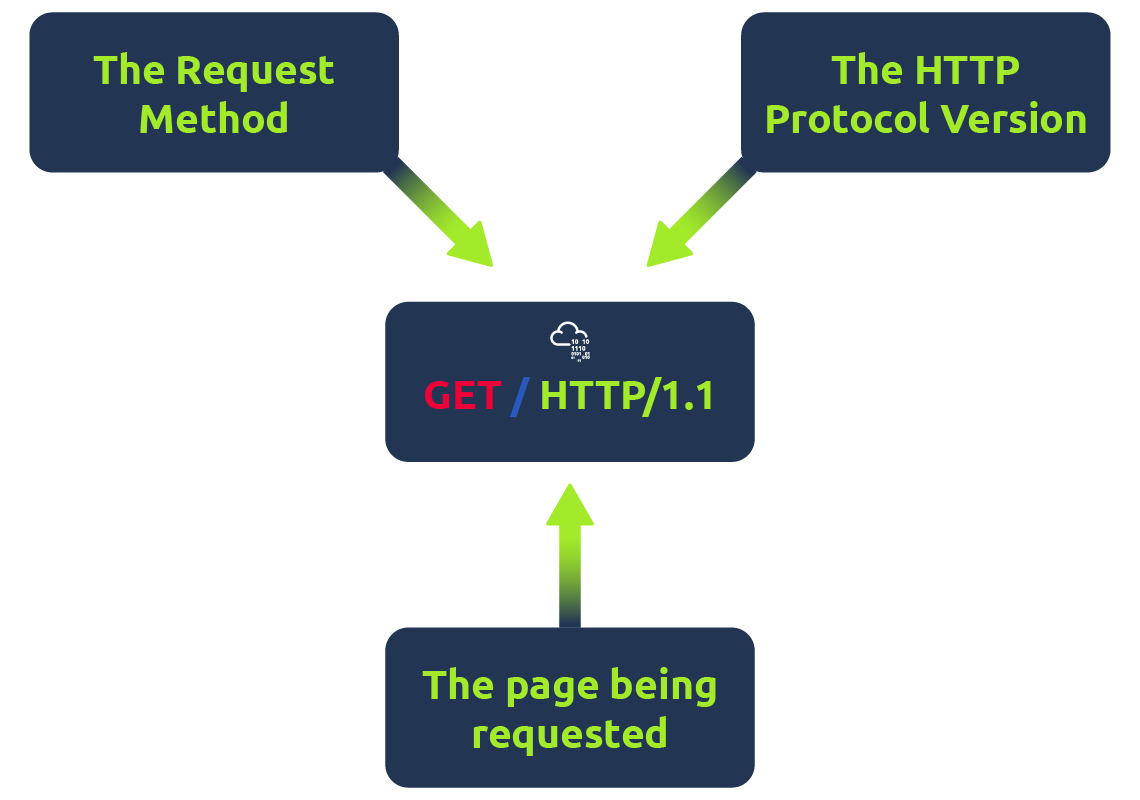
示例请求:
GET / HTTP/1.1 Host: tryhackme.com User-Agent: Mozilla/5.0 Firefox/87.0 Referer: https://tryhackme.com/
第1行: 该请求发送的是 GET 方法(HTTP 方法任务中有更多内容),请求主页,并告知 Web 服务器我们使用 HTTP 协议版本 1.1。
第2行: 我们告诉网页服务器我们想要网站的 tryhackme.com
第3行: 我们告诉网页服务器我们使用的是Firefox 87版浏览器
第4行: 我们告诉网页服务器,推荐我们访问的网页是 https://tryhackme.com
第5行:HTTP 请求总是以空行结尾,告知 Web 服务器请求已完成。
示例回答:
HTTP/1.1 200 OK Server: nginx/1.15.8 Date: Fri, 09 Apr 2021 13:34:03 GMT Content-Type: text/html Content-Length: 98 <html> <head> <title>TryHackMe</title> </head> <body> Welcome To TryHackMe.com </body> </html>
第1行: HTTP 1.1是服务器使用的HTTP协议版本,随后跟随HTTP状态码(此例为“200 OK”),表示请求已成功完成。
第2行: 这告诉我们网页服务器的软件和版本号。
第3行: 网页服务器的当前日期、时间和时区。
第4行: Content-Type 头告诉客户端将发送哪些信息,比如 HTML、图片、视频、PDF、XML。
第5行: Content-Length 告诉客户端响应的长度,这样我们就能确认没有数据缺失。
第6行: HTTP响应包含一行空行以确认HTTP响应的结束。
第7-14行: 所请求的信息,在这里是主页。
HTTP 方法
GET
这用于从网络服务器获取信息。
POST
这用于向网页服务器提交数据,并可能创建新记录
PUT
这用于向网络服务器提交数据以更新信息
DELETE
这用于从网络服务器中删除信息/记录。
HTTP 状态码
常见的HTTP状态码:
HTTP 状态码有很多种,这还不包括应用程序可以自定义的状态码,我们将介绍你最可能遇到的最常见的 HTTP 响应:
| 200 - 好的 | 该请求已成功完成。 |
| 201年 - 创建 | 已经创建了一个资源(例如新用户或新博客文章)。 |
| 301 - 永久搬迁 | 这会将客户的浏览器重定向到新的网页,或者告诉搜索引擎该页面已移动到其他地方,要求他们去那里查看。 |
| 302 - 发现 | 类似于上述永久重定向,但顾名思义,这只是暂时的变化,未来可能还会再次更改。 |
| 400 - 糟糕的请求 | 这告诉浏览器他们的请求中存在问题或缺失。有时如果被请求的网页服务器资源期望某个参数,而客户端未发送,这种方法有时可以使用。 |
| 401 - 未授权 | 目前,未经网页应用授权(通常需用户名和密码)你无法查看该资源。 |
| 403 - 禁忌 | 无论您是否登录,您都无权查看本资源。 |
| 405 - 不允许使用方法 | 资源不允许该方法请求,例如,你向资源/create-account发送GET请求,而它本应接收POST请求。 |
| 404 - 页面未找到 | 你请求的页面/资源不存在。 |
| 500 - 内部服务错误 | 服务器遇到了你的请求出现了某种错误,不知道该如何正确处理。 |
| 503 - 服务不可用 |
这台服务器无法处理你的请求,因为它要么过载,要么正在维护中停机。 |
如果你是视觉型学习者,也可以看看一个很棒的 http.cat 资源来学习状态码。
Headers
通用请求头
这些是客户端(通常是浏览器)发送给服务器的头部。
主持Host:有些服务器托管多个网站,所以通过提供主机头,你可以告诉它你需要哪个网站,否则你只能收到服务器的默认网站。
用户代理User-Agent:这是你的浏览器软件和版本号,告诉网页服务器你的浏览器软件帮助它正确格式化网站,同时 HTML、JavaScript 和 CSS 的某些元素仅在特定浏览器中可用。
内容长度Content-Length:当向网页服务器(如表单)发送数据时,内容长度告诉服务器应预期网络请求中的数据量。这样服务器可以确保没有遗漏任何数据。
接受编码Accept-Encoding:告诉网页服务器浏览器支持哪些类型的压缩方法,以便通过互联网传输时数据更小。
通用响应头
这些是服务器在请求后返回给客户端的头部。
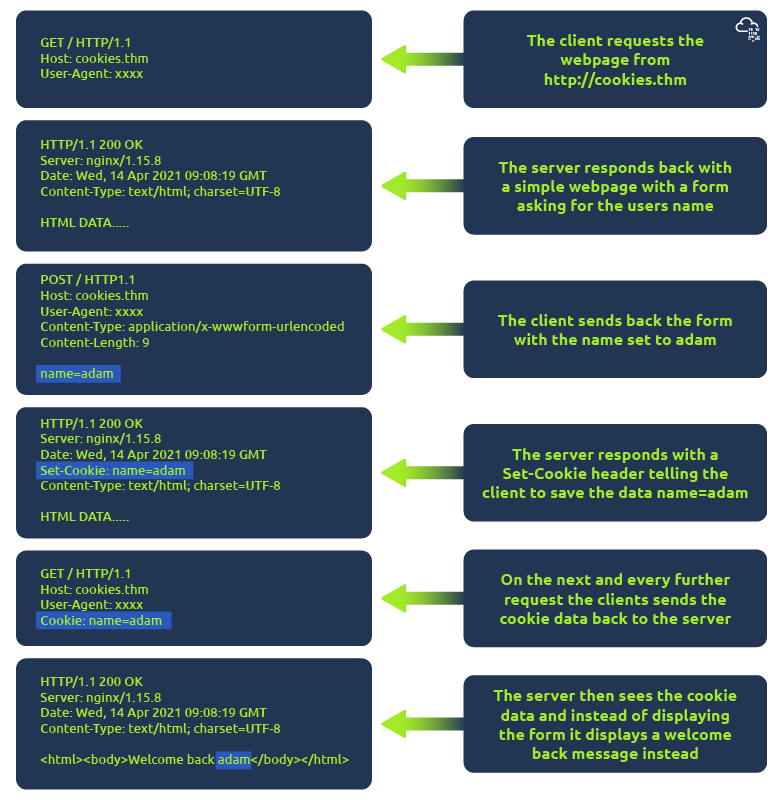
套装饼干Set-Cookie:存储信息,每次请求都会返回到网络服务器(更多信息请参见 cookies 任务)。
缓存控制Cache-Control:在浏览器缓存中存储响应内容多久后,才会再次请求。
内容类型Content-Type:这告诉客户返回的是哪种类型的数据,比如 HTML、CSS、JavaScript、图片、PDF、视频等。通过内容类型头,浏览器就能知道如何处理数据。
内容编码Content-Encoding: 通过互联网传输数据时,采用了什么方法压缩数据以使其更小?
COOKIE

Linux
echo 输出我们提供的任何文本
tryhackme@linux1:~$ echo "Hello Friend!" Hello Friend!
whoami 可以用来查找我们登录的用户名
tryhackme@linux1:~$ whoami
ls 列出目录内容
tryhackme@linux1:~$ ls 'Important Files' 'My Documents' Notes Pictures
cat 查看文本文件的内容
tryhackme@linux1:~/Documents$ cat todo.txt Here's something important for me to do later!
pwd 找这个“文档”文件夹的完整文件路径
tryhackme@linux1:~/Documents$ pwd
/home/ubuntu/Documents
find 查找文件
find -name passwords.txt 查找该特定文件
tryhackme@linux1:~$ find -name passwords.txt
./folder1/passwords.txt
find -name *.txt 搜索所有带有扩展名
tryhackme@linux1:~$ find -name *.txt ./folder1/passwords.txt ./Documents/todo.txt
grep 允许我们搜索文件内容,寻找特定值
举个例子,比如网页服务器的访问日志。在这种情况下,一个网络服务器的access.log有244个条目。
tryhackme@linux1:~$ wc -l access.log
244 access.log
用类似的命令在这里效果不佳。比如说,如果我们想搜索这个日志文件,看看某个用户/IP地址访问了哪些内容?在我们想要找到特定值的情况下,查看244个条目其实效率不高。cat
我们可以用它搜索该文件的全部内容,查找我们正在搜索的值的任何条目。以一个网页服务器的访问日志为例,我们希望看到IP地址“81.143.211.90”访问过的所有内容(注意这是虚构的)grep
tryhackme@linux1:~$ grep "81.143.211.90" access.log 81.143.211.90 - - [25/Mar/2021:11:17 + 0000] "GET / HTTP/1.1" 200 417 "-" "Mozilla/5.0 (Linux; Android 7.0; Moto G(4))"
touch文件 mkdir文件夹 创建文件与文件夹
tryhackme@linux2:~$ touch note tryhackme@linux2:~$ ls folder1 note tryhackme@linux2:~$ mkdir mydirectory tryhackme@linux2:~$ ls folder1 mydirectory note
rm 删除文件 -R删除文件夹
tryhackme@linux2:~$ rm note tryhackme@linux2:~$ ls folder1 mydirectory tryhackme@linux2:~$ rm -R mydirectory tryhackme@linux2:~$ ls folder1
cp mv 复制和移动文件和文件夹
cp将现有文件的全部内容复制到新文件中。在下面的截图中,我们正在将“note”复制到“note2”tryhackme@linux2:~$ cp note note2 tryhackme@linux2:~$ ls folder1 note note2
移动文件需要两个参数,就像 cp 命令一样。然而,它不会复制和/或创建新文件,而是合并或修改我们作为参数的第二个文件。你不仅可以用来将文件移动到新文件夹,还可以用它重命名文件或文件夹。例如,在下面的截图中,我们将文件“note2”改名为“note3”。“Note3”现在将拥有“Note2”的内容
tryhackme@linux2:~$ mv note2 note3 tryhackme@linux2:~$ ls folder1 note note3
file 确定文件类型
tryhackme@linux2:~$ file note
note: ASCII text
nano 创建或编辑文件

scp 用于 Linux 之间复制文件和目录
从本地将文件传输到服务器 scp【本地文件的路径】【服务器用户名】@【服务器地址】:【服务器上存放文件的路径】 scp /Users/mac_pc/Desktop/test.png root@192.168.1.1:/root scp 【服务器用户名】@【服务器地址】:【服务器上存放文件的路径】【本地文件的路径】 scp root@192.168.1.1:/data/wwwroot/default/111.png /Users/mac_pc/Desktop
python3 -m http.server
快速启动一个轻量级HTTP服务器,用于本地开发测试或临时文件共享
核心功能:监听指定端口,提供静态文件服务。
常见场景:
前端开发时本地预览页面
临时共享文件夹中的文件
目录暴露风险:服务器会暴露当前目录下所有文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号